

{kind=link}
On this tutorial, we are going to look into learn how to simply carry out sentiment evaluation on textual content knowledge utilizing IBM’s open-source Granite 3B mannequin built-in with Hugging Face Transformers. Sentiment evaluation, a widely-used pure language processing (NLP) approach, helps rapidly determine the feelings expressed in textual content. It makes it invaluable for companies aiming to grasp buyer suggestions and improve their services and products. Now, let’s stroll you thru putting in the mandatory libraries, loading the IBM Granite mannequin, classifying sentiments, and visualizing your outcomes, all effortlessly executable in Google Colab.
!pip set up transformers torch speed upFirst, we’ll set up the important libraries—transformers, torch, and speed up—required for loading and working highly effective NLP fashions seamlessly. Transformers offers pre-built NLP fashions, torch serves because the backend for deep studying duties, and speed up ensures environment friendly useful resource utilization on GPUs.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import pandas as pd
import matplotlib.pyplot as pltThen, we’ll import the required Python libraries. We’ll use torch for environment friendly tensor operations, transformers for loading pre-trained NLP fashions from Hugging Face, pandas for managing and processing knowledge in structured codecs, and matplotlib for visually decoding your evaluation outcomes clearly and intuitively.
model_id = "ibm-granite/granite-3.0-3b-a800m-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
mannequin = AutoModelForCausalLM.from_pretrained(
model_id,
device_map='auto',
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
generator = pipeline("text-generation", mannequin=mannequin, tokenizer=tokenizer)Right here, we’ll load IBM’s open-source Granite 3B instruction-following mannequin, particularly ibm-granite/granite-3.0-3b-a800m-instruct, utilizing Hugging Face’s AutoTokenizer and AutoModelForCausalLM. This compact, instruction-tuned mannequin is optimized to deal with duties like sentiment classification straight inside Colab, even beneath restricted computational assets.
def classify_sentiment(evaluate):
immediate = f"""Classify the sentiment of the next evaluate as Optimistic, Unfavourable, or Impartial.
Evaluation: "{evaluate}"
Sentiment:"""
response = generator(
immediate,
max_new_tokens=5,
do_sample=False,
pad_token_id=tokenizer.eos_token_id
)
sentiment = response[0]['generated_text'].cut up("Sentiment:")[-1].cut up("n")[0].strip()
return sentimentNow we’ll outline the core perform classify_sentiment. This perform leverages the IBM Granite 3B mannequin via an instruction-based immediate to categorise the sentiment of any given evaluate into Optimistic, Unfavourable, or Impartial. The perform codecs the enter evaluate, invokes the mannequin with exact directions, and extracts the ensuing sentiment from the generated textual content.
import pandas as pd
critiques = [
"I absolutely loved the service! Definitely coming back.",
"The item arrived damaged, very disappointed.",
"Average product. Nothing too exciting.",
"Superb experience, exceeded all expectations!",
"Not worth the money, poor quality."
]
reviews_df = pd.DataFrame(critiques, columns=['review'])Subsequent, we’ll create a easy DataFrame reviews_df utilizing Pandas, containing a set of instance critiques. These pattern critiques function enter knowledge for sentiment classification, enabling us to watch how successfully the IBM Granite mannequin can decide buyer sentiments in a sensible state of affairs.
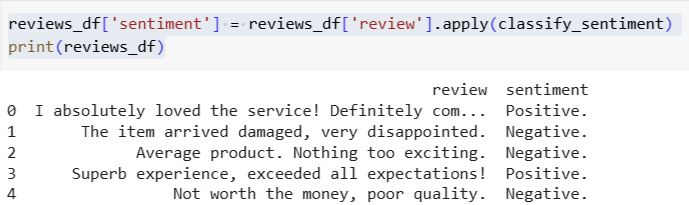
reviews_df['sentiment'] = reviews_df['review'].apply(classify_sentiment)
print(reviews_df)After defining the critiques, we’ll apply the classify_sentiment perform to every evaluate within the DataFrame. It will generate a brand new column, sentiment, the place the IBM Granite mannequin classifies every evaluate as Optimistic, Unfavourable, or Impartial. By printing the up to date reviews_df, we are able to see the unique textual content and its corresponding sentiment classification.
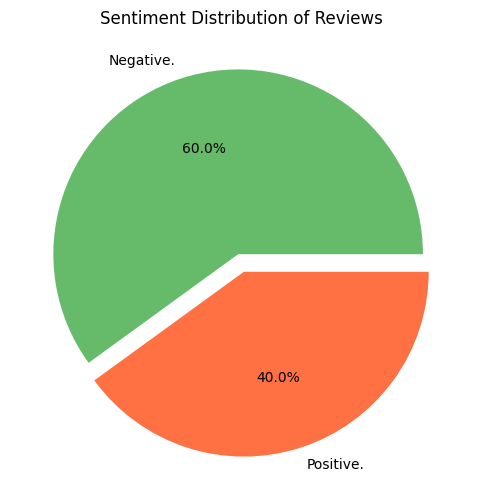
import matplotlib.pyplot as plt
sentiment_counts = reviews_df['sentiment'].value_counts()
plt.determine(figsize=(8, 6))
sentiment_counts.plot.pie(autopct="%1.1f%%", explode=[0.05]*len(sentiment_counts), colours=['#66bb6a', '#ff7043', '#42a5f5'])
plt.ylabel('')
plt.title('Sentiment Distribution of Critiques')
plt.present()
Lastly, we’ll visualize the sentiment distribution in a pie chart. This step offers a transparent, intuitive overview of how the critiques are labeled, making decoding the mannequin’s general efficiency simpler. Matplotlib lets us rapidly see the proportion of Optimistic, Unfavourable, and Impartial sentiments, bringing your sentiment evaluation pipeline full circle.
In conclusion, we now have efficiently carried out a robust sentiment evaluation pipeline utilizing IBM’s Granite 3B open-source mannequin hosted on Hugging Face. You realized learn how to leverage pre-trained fashions to rapidly classify textual content into optimistic, destructive, or impartial sentiments, visualize insights successfully, and interpret your findings. This foundational strategy means that you can simply adapt these abilities to research datasets or discover different NLP duties. IBM’s Granite fashions mixed with Hugging Face Transformers provide an environment friendly solution to carry out superior NLP duties.
Right here is the Colab Pocket book. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 80k+ ML SubReddit.
🚨 Really useful Learn- LG AI Analysis Releases NEXUS: An Superior System Integrating Agent AI System and Knowledge Compliance Requirements to Handle Authorized Considerations in AI Datasets
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.