

{kind=link}
LLMs are more and more utilized in healthcare for duties like query answering and doc summarization, acting on par with area specialists. Nonetheless, their effectiveness in conventional biomedical duties, reminiscent of structured info extraction, stays to be seen. Whereas LLMs have efficiently generated free-text outputs, present approaches primarily concentrate on enhancing the fashions’ inner information by way of strategies like fine-tuning and in-context studying. These strategies rely upon available knowledge, typically inadequate within the biomedical area on account of area shifts and the shortage of assets for particular structured duties, making zero-shot efficiency vital but underexplored.
Researchers from a number of establishments, together with ASUS Clever Cloud Providers, Imperial School London, and the College of Manchester, performed a research to benchmark the efficiency of LLMs in medical classification and Named Entity Recognition (NER) duties. They aimed to investigate how various factors, reminiscent of task-specific reasoning, area information, and the addition of exterior experience, affect LLM efficiency. Their findings revealed that normal prompting outperformed extra advanced strategies like Chain-of-Thought (CoT) reasoning and Retrieval-Augmented Technology (RAG). The research highlights the challenges of making use of superior prompting strategies in biomedical duties and emphasizes higher integrating exterior information in LLMs for real-world functions.
The present literature on benchmarking LLMs within the medical area primarily focuses on duties like Query Answering, summarization, and scientific coding, typically neglecting structured prediction duties reminiscent of doc classification and Named Entity Recognition. Whereas earlier work has offered precious assets for historically structured duties, many benchmarks overlook these in favor of evaluating domain-specific fashions. Latest approaches to reinforce LLM efficiency embody domain-specific pretraining, instruction tuning, CoT reasoning, and RAG. Nonetheless, these strategies typically want extra systematic analysis within the context of structured prediction, which the research goals to deal with.
To evaluate LLM efficiency on structured prediction duties, the research benchmark a variety of fashions on biomedical textual content classification and NER duties in a real zero-shot setting. This strategy evaluates the fashions’ inherent parametric information, which is essential as a result of shortage of annotated biomedical knowledge. We examine this baseline efficiency with enhancements from CoT reasoning, RAG, and Self-Consistency strategies whereas protecting the parametric information fixed. Strategies are evaluated utilizing a wide range of datasets, together with each English and non-English sources, and the fashions are constrained to make sure structured output.
The analysis outcomes reveal that reasoning and information enhancement strategies typically don’t increase efficiency. Normal Prompting constantly yields the best F1 scores for classification duties throughout all fashions, with BioMistral-7B, Llama-2-70B, and Llama-2-7B scoring 36.48%, 40.34%, and 34.92%, respectively. Advanced strategies like CoT Prompting and RAG should typically carry out higher than Normal Prompting. Bigger fashions, reminiscent of Llama-2-70B, considerably enhance, particularly in duties requiring superior reasoning. Nonetheless, multilingual and personal datasets present decrease efficiency, and high-complexity duties nonetheless have to be improved, with RAG strategies displaying inconsistent advantages.
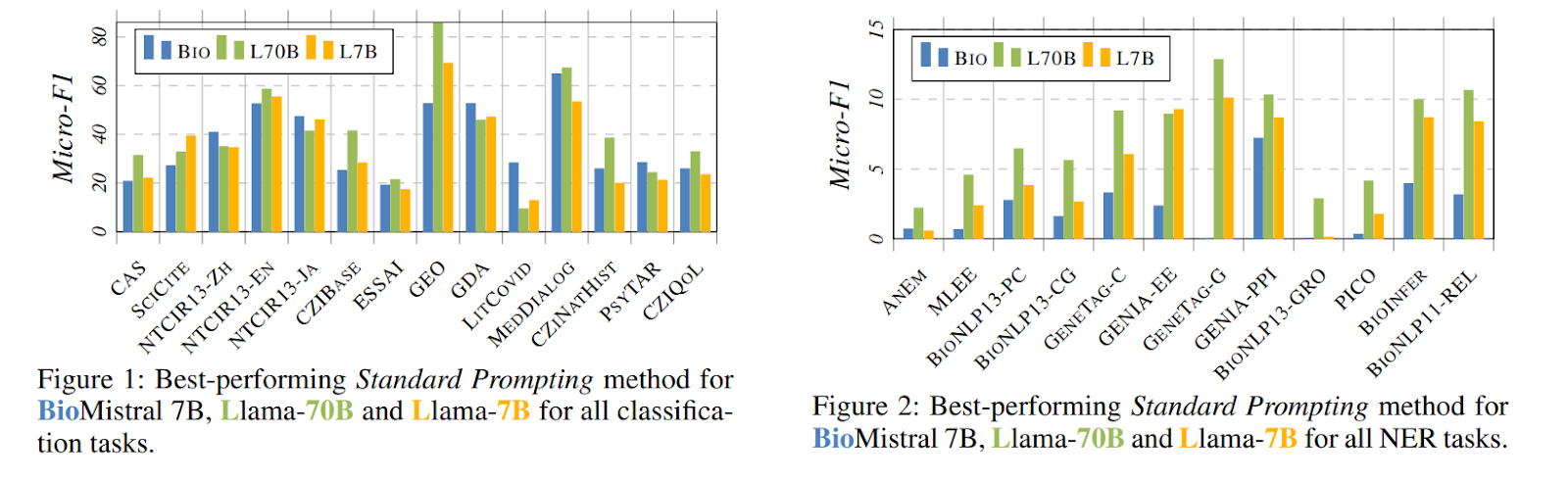
The research benchmarks LLMs in Medical Classification and NER, revealing important insights. Regardless of the superior strategies like CoT and RAG, Normal Prompting constantly outperforms these strategies throughout duties. This underscores a basic limitation in LLMs’ generalizability and effectiveness in structured biomedical info extraction. The outcomes spotlight that present superior prompting strategies should translate higher to biomedical duties, emphasizing the necessity to combine domain-specific information and reasoning capabilities to reinforce LLM efficiency in real-world healthcare functions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.