

{kind=link}
Experimentation and validation of LLM efficiency is essential when constructing LLM-driven programs that should reliably ship a service, from customer support chat bots to intelligence evaluation instruments. To assist groups meet the necessity for rigorous analysis strategies, researchers in SEI’s AI Division developed the Increasing Massive Language Mannequin Metrics (ELM) library constructed on finest practices for LLM analysis and benchmarking.
On this weblog publish, we offer a tutorial for utilizing the ELM library, a set of extensible, customizable instruments designed to make LLM evaluations repeatable, explainable, and constant. The ELM library allows the next:
- full customization: write your personal prompts and assessments and plug in any metrics or fashions.
- inference-independent analysis: works on a JSON of inference outcomes so you’ll be able to generate leads to one atmosphere and rating them in one other.
- auditable and reproducible testing: each run shops the config, seed, mannequin model, and metric code.
- zero-cost, open-source functionality: freed from hidden charges or vendor lock-in.
Beneath, we dive into the inference and analysis engines that energy ELM, exhibiting you how you can arrange a dependable, finish‑to‑finish analysis workflow.
Tutorial: Utilizing the ELM Analysis Engine
The ELM library contains each an inference engine and an analysis engine. The inference engine allows batch inference utilizing native or API-based fashions, with built-in logging, {hardware} monitoring, and validation. The analysis engine supplies a customizable framework for evaluating LLM efficiency towards current or bespoke benchmarks and metrics. The Python code, obtainable on Github, is designed for light-weight, adaptable experimentation with native or API-based fashions. The library makes use of a configuration-driven strategy to defining inference and analysis jobs, guaranteeing experiments are repeatable.
For native fashions, customers can override hyperparameters to assist experimentation and benchmarking. Inference and analysis outcomes are saved to JSON recordsdata alongside enter parameters and metadata, offering constant, queryable experimental outputs.
{kind=link}
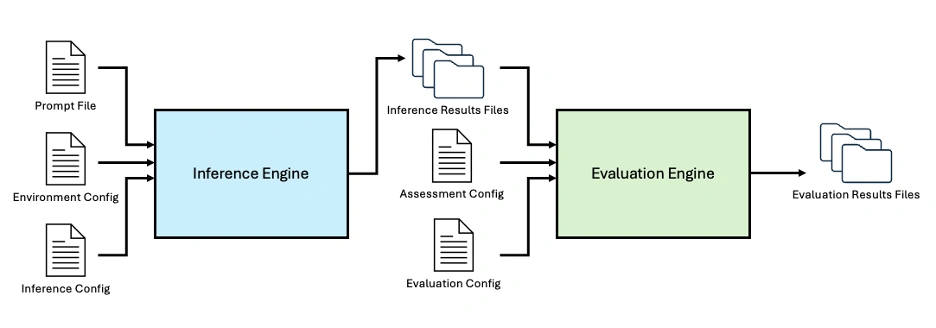
Determine 1: The ELM Library contains an Inference Engine and Analysis Engine to allow end-to-end LLM analysis, customizable utilizing a collection of configuration recordsdata.
At a excessive degree, customers can customise each the mannequin configuration file and the immediate configuration file. These recordsdata outline a set of reproducible, traceable inferences which might be robotically executed by the inference engine. The ensuing outputs are then fed into the analysis engine along with a customizable evaluation configuration file and an analysis configuration file, producing the ultimate analysis outcomes.
Getting the Engine Prepared
To start, set up the ELM library and its dependencies. The necessities.txt file contains frequent AI/ML packages comparable to scikit-learn, transformers, torch, and openai. All packages may be obtained by way of PyPI.
After cloning the repository, navigate to the highest degree of the repository and set up the pipelines and required dependencies with pip:
```bash
pip set up -e .
```
For regionally hosted fashions, the pipelines robotically choose the perfect GPU assets (if obtainable) and fall again to the CPU in any other case.
If utilizing an OpenAI mannequin, set the API key within the terminal:
```bash
export OPENAI_API_KEY="{api_key}"
```
Working Batch Inference
Essentially the most fundamental use of the ELM is batch inference over a set of prompts. Three JSON-style enter recordsdata are required: a immediate file, an atmosphere config, and an inference config.
Defining a Immediate File
The immediate file comprises a formatted listing of all of the prompts. Every immediate entry should embrace the identify, type, and immediate textual content. An optionally available ground-truth textual content subject may be included for analysis. An inventory of parameters and definitions are enumerated in PromptConfig.py. Right here is an instance immediate entry:
```json
[
{
"name": "Test Prompt 1",
"style": "basic",
"text": "Finish the following sentence: That's one small step for",
“gt_text”: “man, one giant leap for mankind.”
}
]
```
Setting Up the Atmosphere Configuration
The atmosphere configuration file specifies fashions and their areas. Each mannequin entry should embrace the mannequin identify and mannequin household. Some households might require further particulars. For instance, Llama fashions should specify paths for the weights, tokenizer, and cache. An inventory of parameters and definitions are enumerated in EnvironmentConfig.py. Right here is an instance atmosphere configuration file for a run that makes use of two completely different variations of Llama 3:
```json
{
"identify": "multi_configs_env",
"fashions":
[
{
"model_name": "LLaMa 3.2 1B",
"model_family": "Llama",
"weights_dir": "/path/to/Llama3.2-1B-hf",
"tokenizer_dir": "/path/to/ Llama3.2-1B-hf",
"cache_dir": "/path/to/ Llama3.2-1B-hf"
},
{
"model_name": "LLaMa 3.2 3B",
"model_family": "Llama",
"weights_dir": "/path/to/ Llama3.2-3B-hf",
"tokenizer_dir": "/path/to/Llama3.2-3B-hf",
"cache_dir": "/path/to/ Llama3.2-3B-hf"
},
]
}
```
Configuring the Inference Settings
The inference configuration specifies the output listing, the atmosphere config, and a number of inference units mapping fashions to immediate recordsdata. Inference units include lists of immediate file names together with mannequin names that correspond to these outlined within the atmosphere configuration file. An inventory of parameters and definitions are enumerated in InferenceConfig.py. Right here is an instance inference configuration file:
```json
[
{
"output_directory": "test_dir_1",
"environment_config": "multi_configs_env.json",
"inference_sets": [
{
"models": [
"LLaMa 3.2 1B",
"LLaMa 3.2 3B"
],
"prompts": [
"two_prompts.json",
"test_prompt2.json"
]
},
{
"fashions": [
"LLaMa 3.1 8B Instruct"
],
"prompts": [
"test_prompt2.json"
]
}
]
}
]
```
Working Batch Inference
As soon as the configuration recordsdata have been specified, run the next command from the listing containing Inference_Engine.py to start out batch inference:
```bash
python Inference_Engine.py -c /path/to/inference/configs.json
```
The engine writes timestamped outcomes recordsdata to the output listing. Every file information
- the unique immediate and mannequin identify
- RAM & GPU utilization (for each mannequin loading and inference)
- the mannequin output
Console logs are written to a separate logs listing.
Working Analysis Experiments
After batch inference is configured throughout units of prompts and fashions, an evaluation step may be integrated to allow large-scale evaluations. This requires two further JSON recordsdata: an evaluation configuration file and an analysis configuration file. An inventory of parameters and definitions are enumerated in AssessmentConfig.py and EvaluationConfig.py.
Creating an Evaluation Configuration
The evaluation configuration file defines the prompts and metrics used throughout analysis. The metrics correspond to lessons within the metrics folder, and the prompts are specified as paths to the identical immediate recordsdata utilized by the inference engine.
The evaluation configuration successfully defines a benchmark as a mix of prompts and metrics. For instance, a immediate file might include supply texts and corresponding ground-truth summaries, paired with a summarization metric comparable to ROUGE to judge abstract efficiency.
```json
{
"identify": "assess_test_rouge",
"description": "Check evaluation for ROUGE rating",
"model": "1.0",
"prompts": ["prompt_billsum_demo.json”],
"metrics": ["ROUGE_Score"]
}
```
Defining an Analysis Configuration
The analysis configuration file controls the general experiment. This file specifies
- the output listing
- an inventory of fashions
- an inventory of the evaluation recordsdata
- the atmosphere configuration file
- the pipeline kind
A full pipeline will run each inference and analysis, whereas a metrics_only pipeline depends on earlier inference outcomes and can solely run the analysis.
```json
{
"outdir": "test_rouge_score",
"pipeline_type": "full",
"fashions": ["LLaMa 3.2 1B", "T5 Summarization5"],
"assessments": ["assess_test_rouge.json"],
"environment_config": "rouge_eval_env.json",
"metrics": []
}
```
Executing the Analysis
From the listing containing Evaluation_Engine.py, run
```bash
python Evaluation_Engine.py -c /path/to/analysis/configs.json
```
This command runs the analysis engine, together with the inference engine if wanted, and produces output recordsdata and logs.
If run as a metrics_only pipeline, the first output file is the evaluation_report.json file that might be saved to the run outcomes listing specified by the outdir subject within the analysis config file. The analysis report contains
- run metadata (e.g., run_id)
- the originating analysis configuration file
- the whole variety of fashions and assessments
- combination outcomes organized by model-assessment pairings, together with metric particulars and references to the corresponding inference consequence recordsdata
Analysis reviews are saved by default to /elm/evaluation_engine/evaluation_results/<outdir>. The evaluation_report_timestamp.json file is saved on this outdir. Within the case of a full pipeline run, as detailed within the subsequent part, this outdir additionally comprises subdirectories for every mannequin within the run. Every mannequin listing will include separate directories for every evaluation ran towards that mannequin, e.g. /gpt-oss-120b/mmlu_assessment. Every evaluation listing will include an inference_result.json file for every immediate inside the evaluation.
Here’s a pattern analysis report from a metrics_only run:
```json
{
"evaluation_metadata": {
"run_id": "eval_YYYYMMDD_HHmmss",
"evaluation_config": "evaluation_configs/source_eval_config.json",
"timestamp": "YYYY-MM-DDThh:mm:ss.ssssss",
"pipeline_type": "metrics_only",
"total_models": 1,
"total_assessments": 1,
"total_execution_time": 1.2
},
"model_results": [
{
"model_name": "LLaMa 3.2 1B",
"assessments": [
{
"name": "assessment_name",
"config": "/path/to/assessment_config.json",
"execution_time": 0.8,
"total_prompts": 1,
"metric_summaries": {
"metric_name": {
"counts": {
"total_items": 1,
"scored_items": 1,
"skipped_items": 0,
"failed_items": 0,
"correct_answers": 1,
"incorrect_answers": 1
},
"scores": {
"accuracy": 1.0,
"accuracy_percentage": 100.0
},
"issues": []
}
},
"prompt_results": [
{
"name": "name_of_first_prompt",
"model_output": "example model output",
"inference_time": 0,
"source_file": "/path/to/inference_result_file.json",
"gt_text": "C",
"metric_details": {
"metric_name": {
"status": "ok",
"errors": [],
"right": true
}
}
}
]
}
]
}
]
}
```
If executed as a full pipeline, the output listing can even embrace all inference consequence recordsdata generated by the inference engine. Every inference consequence file information the inputs and outputs for a single inference, together with metadata and {hardware} utilization (for native fashions). This contains the mannequin identify, immediate configuration, era configuration, optionally available quantization configuration, the mannequin’s output, and related metadata.
Here’s a pattern analysis report from a full pipeline run:
```
```json
{
"evaluation_metadata": {
"run_id": "eval_20260505_180410",
"evaluation_config": "evaluation_configs/eval_mmlu_global_facts.json",
"timestamp": "2026-05-05T18:04:10.513927",
"pipeline_type": "full",
"total_models": 1,
"total_assessments": 1,
"total_execution_time": 20.6
},
"model_results": [
{
"model_name": "LLaMa 3.2 1B",
"assessments": [
{
"name": "mmlu_global_facts",
"config": "/full/path/to/elm/evaluation_engine/assessment_configs/assess_mmlu_global_facts.json",
"execution_time": 20.6,
"total_prompts": 1,
"metric_summaries": {
"MMLU_Accuracy": {
"counts": {
"total_items": 1,
"scored_items": 1,
"skipped_items": 0,
"failed_items": 0,
"correct_answers": 0,
"incorrect_answers": 1
},
"scores": {
"accuracy": 0.0,
"accuracy_percentage": 0.0
},
"issues": []
}
},
"prompt_results": [
{
"name": "mmlu_global_facts_test_0",
"model_output": "model response here",
"inference_time": 12.6,
"source_file": "/full/path/to/elm/evaluation_engine/evaluation_results/evaluation_name/run_eval_dir/model_name/assessment_name/inference_results/inference_result.json",
"gt_text": "C",
"metric_details": {
"MMLU_Accuracy": {
"status": "ok",
"errors": [],
"right": false
}
}
}
]
}
]
}
]
}
```
Including Hyperparameter Overrides
Customized hyperparameters may be specified within the inference or analysis configuration recordsdata to override the default settings utilized by supported HuggingFace Transformers-based native fashions throughout era. The entire era configuration is recorded in every inference consequence file to make sure full reproducibility. These overrides allow experimentation with completely different hyperparameter settings to find out essentially the most appropriate configuration for a given mannequin and process, or to look at how mannequin outputs fluctuate as hyperparameters change.
Hyperparameter overrides are utilized by way of the inference configuration file for the inference engine, and by way of the analysis configuration file for the analysis engine. Hyperparameter overrides may be utilized at three ranges inside the configuration recordsdata: international, inference set or evaluation, and mannequin. Mannequin-level overrides take priority over inference set or assessment-level overrides, which in flip take priority over global-level overrides, preserving essentially the most particular settings.
Right here is an instance of hyperparameter overrides in an inference configuration file:
```json
[
{
"output_directory": "path/to/store/results",
"environment_config": "example_env.json",
"hyperparameters": { // Global overrides
"temperature": 0.7,
"max_new_tokens": 256
},
"inference_sets": [
{
"prompts": ["example_prompt_file.json"],
"hyperparameters": {
"temperature": 0.5 // Set-level overrides
},
"fashions": [
{"name": "LLaMa 3.2 1B"},
{
"name": "LLaMa 3.1 8B Instruct",
"hyperparameters": { // Model-level overrides
"temperature": 0.9,
"top_k": 100
}
}
]
}
]
}
]
```
On this instance, the Llama 3.1 8B Instruct mannequin will generate responses with a temperature of 0.9, top_k of 100, and max_new_tokens of 256. The Llama 3.2 1B mannequin will generate responses with a temperature of 0.5 and max_new_tokens of 256.
For a full listing of configurable choices, see HuggingFace GenerationConfig.
Extending the Framework
Customized metrics and new mannequin households can simply be added inside the ELM analysis engine.
Including a Customized Mannequin Household
The repository contains built-in assist for the Llama, OpenAI, and T5 households of fashions.
So as to add a brand new mannequin household, create a Python file within the inference_engine/languagemodels folder. Subclass the supplied LanguageModel class and embrace the next:
- six required strategies:
identify,load,ask,delete,log, andprompter - every other required attributes outlined within the
environment_configfile, comparable to paths to the mannequin file
Add the mannequin to __all__ within the corresponding __init__ file and replace the import assertion.
```json
from .LanguageModel import LanguageModel
class Mannequin(LanguageModel):
def __init__(self, specs):
self._name = specs["model_name"]
self.attribute = specs["model_attribute"]
self.quantization_config_used = None
# Initialize model-specific parameters
@property
def identify(self):
return self._name
def load(self, quantization_config=None):
# Load mannequin into reminiscence
go
def ask(self, immediate, historical past=None, hyperparameters=None):
# Generate response to immediate
go
def delete(self):
# Clear up mannequin from reminiscence
go
def log(self):
# Mannequin-specific logging
go
def prompter(self):
# Deal with immediate formatting
go
```
Incorporating a Customized Metric
The framework contains built-in assist for the MMLU and ROUGE metrics. ROUGE is an n-gram primarily based similarity rating metric used for evaluating translation and summarization. MMLU is a multiple-choice benchmark for measuring data.
So as to add a customized metric, add a Python file to the evaluation_engine/metrics folder. The metric file ought to subclass the supplied MetricBase class and implement two features: identify() and compute(inference outcomes). The compute operate should return a formatted abstract of the outcomes together with counts, combination scores, and particular person prompt-level leads to the next format:
```json
"abstract": {
"counts": {
"total_items": total_items,
"scored_items": scored_items,
"skipped_items": skipped_count,
"failed_items": failed_count
},
"scores": summary_scores,
"points": points
},
"individual_results": individual_results
}
```
Future Work: T&E for Agentic Programs
Agentic programs are quickly reshaping the panorama of clever programs. LLMs function the core of autonomous agentic workflows, and evaluating the underlying mannequin is just step one. Agentic programs convey new challenges: measuring the success of device utilization, analyzing execution traces for effectivity, and gauging efficiency on finish‑to‑finish duties.
The subsequent part of the ELM challenge focuses on testing agentic programs and establishing finest practices for benchmark creation and utility. We plan to develop the ELM Library with the discharge of a pipeline for designing and working agentic benchmarks set for August 2026.