

{kind=link}
What comes after Transformers? Google Analysis is proposing a brand new approach to give sequence fashions usable long run reminiscence with Titans and MIRAS, whereas protecting coaching parallel and inference near linear.
Titans is a concrete structure that provides a deep neural reminiscence to a Transformer model spine. MIRAS is a common framework that views most trendy sequence fashions as cases of on-line optimization over an associative reminiscence.
Why Titans and MIRAS?
Customary Transformers use consideration over a key worth cache. This offers robust in context studying, however value grows quadratically with context size, so sensible context is proscribed even with FlashAttention and different kernel tips.
Environment friendly linear recurrent neural networks and state house fashions reminiscent of Mamba-2 compress the historical past into a set measurement state, so value is linear in sequence size. Nonetheless, this compression loses info in very lengthy sequences, which hurts duties reminiscent of genomic modeling and excessive lengthy context retrieval.
Titans and MIRAS mix these concepts. Consideration acts as a exact quick time period reminiscence on the present window. A separate neural module gives long run reminiscence, learns at take a look at time, and is skilled in order that its dynamics are parallelizable on accelerators.
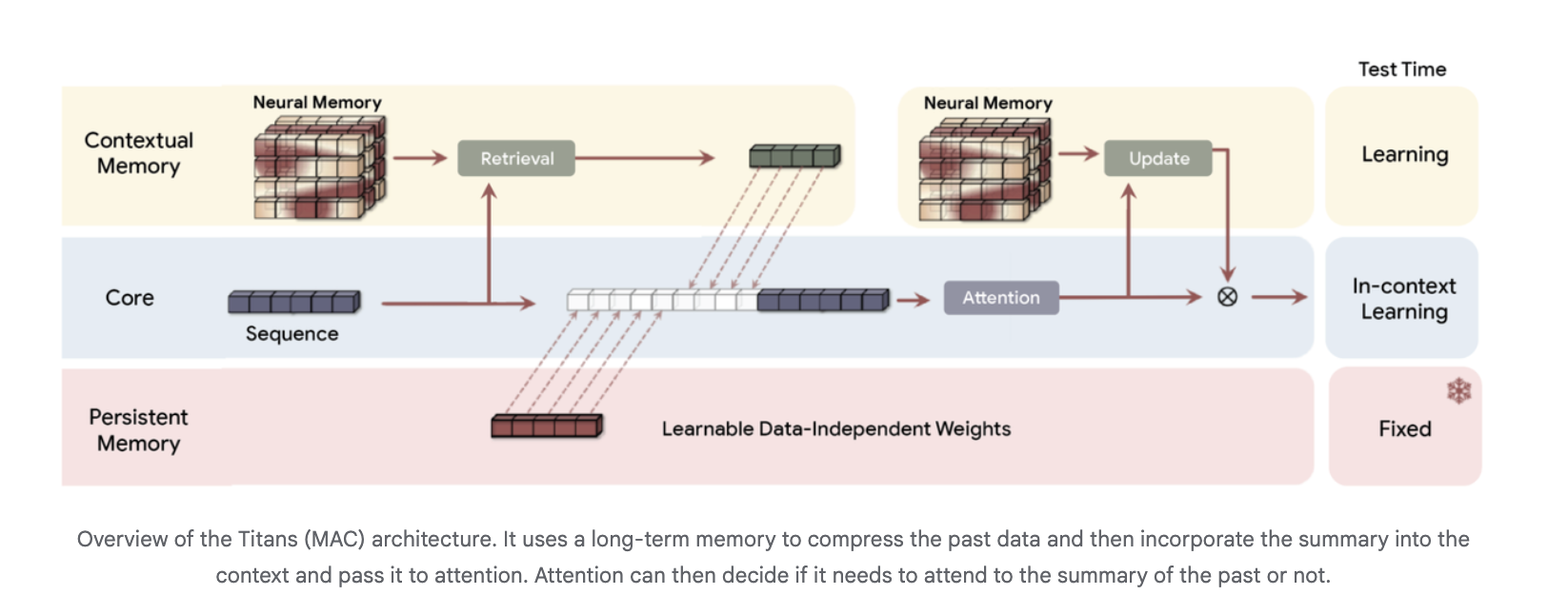
Titans, a neural long run reminiscence that learns at take a look at time
The Titans analysis paper introduces a neural long run reminiscence module that’s itself a deep multi layer perceptron fairly than a vector or matrix state. Consideration is interpreted as quick time period reminiscence, because it solely sees a restricted window, whereas the neural reminiscence acts as persistent long run reminiscence.
For every token, Titans defines an associative reminiscence loss
ℓ(Mₜ₋₁; kₜ, vₜ) = ‖Mₜ₋₁(kₜ) − vₜ‖²
the place Mₜ₋₁ is the present reminiscence, kₜ is the important thing and vₜ is the worth. The gradient of this loss with respect to the reminiscence parameters is the “shock metric”. Giant gradients correspond to shocking tokens that needs to be saved, small gradients correspond to anticipated tokens that may be principally ignored.
The reminiscence parameters are up to date at take a look at time by gradient descent with momentum and weight decay, which collectively act as a retention gate and forgetting mechanism.To maintain this on-line optimization environment friendly, the analysis paper reveals the way to compute these updates with batched matrix multiplications over sequence chunks, which preserves parallel coaching throughout lengthy sequences.
Architecturally, Titans makes use of three reminiscence branches within the spine, typically instanced within the Titans MAC variant:
- a core department that performs commonplace in context studying with consideration
- a contextual reminiscence department that learns from the current sequence
- a persistent reminiscence department with fastened weights that encodes pretraining information
The long run reminiscence compresses previous tokens right into a abstract, which is then handed as further context into consideration. Consideration can select when to learn that abstract.
Experimental outcomes for Titans
On language modeling and commonsense reasoning benchmarks reminiscent of C4, WikiText and HellaSwag, Titans architectures outperform cutting-edge linear recurrent baselines Mamba-2 and Gated DeltaNet and Transformer++ fashions of comparable measurement. The Google analysis attribute this to the upper expressive energy of deep reminiscence and its capacity to take care of efficiency as context size grows. Deep neural reminiscences with the identical parameter finances however increased depth give persistently decrease perplexity.
For excessive lengthy context recall, the analysis workforce makes use of the BABILong benchmark, the place information are distributed throughout very lengthy paperwork. Titans outperforms all baselines, together with very massive fashions reminiscent of GPT-4, whereas utilizing many fewer parameters, and scales to context home windows past 2,000,000 tokens.
The analysis workforce stories that Titans retains environment friendly parallel coaching and quick linear inference. Neural reminiscence alone is barely slower than the quickest linear recurrent fashions, however hybrid Titans layers with Sliding Window Consideration stay aggressive on throughput whereas bettering accuracy.
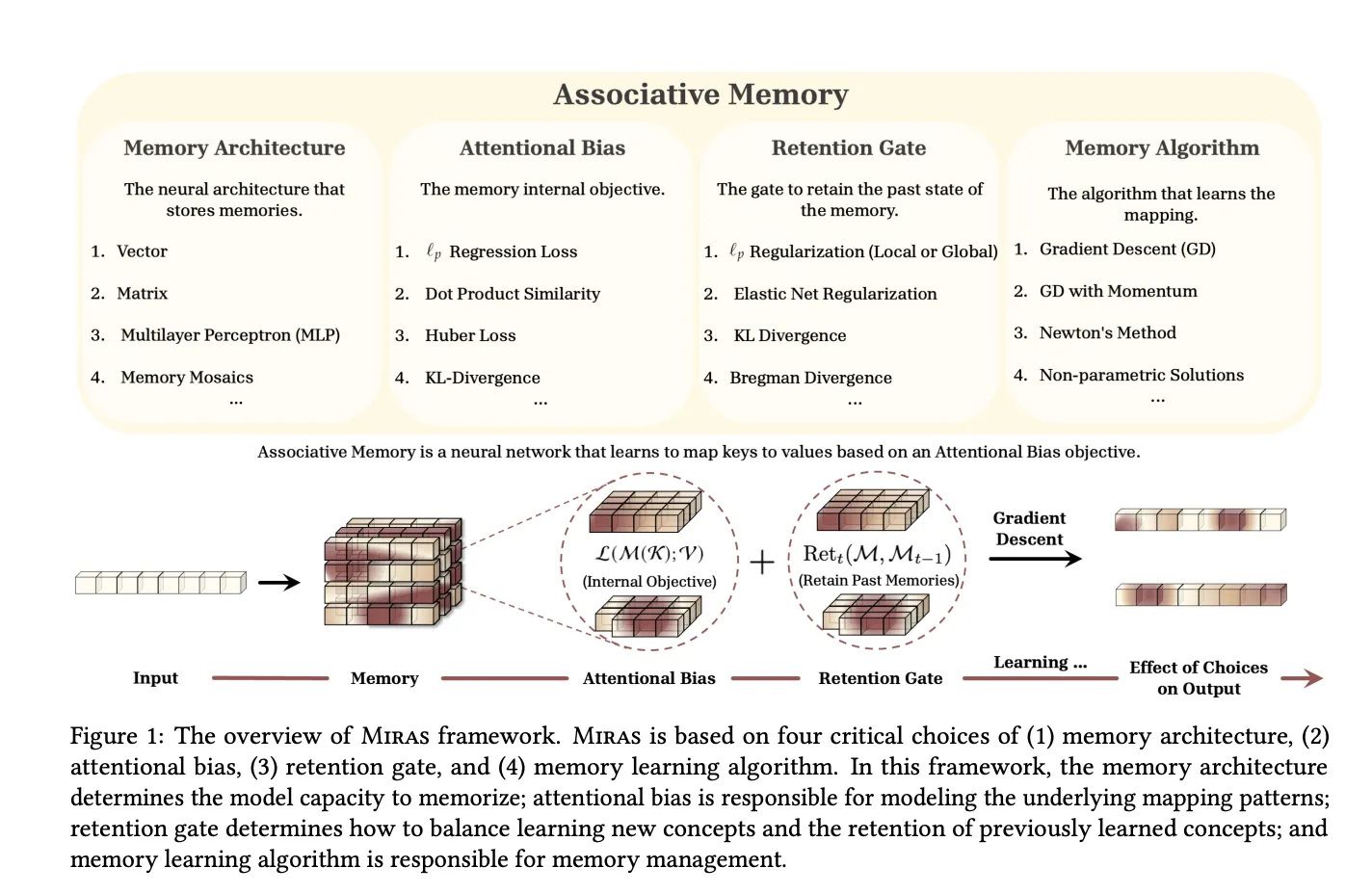
MIRAS, a unified framework for sequence fashions as associative reminiscence
The MIRAS analysis paper, “It’s All Linked: A Journey By Check Time Memorization, Attentional Bias, Retention, and On-line Optimization,” generalizes this view. It observes that trendy sequence fashions may be seen as associative reminiscences that map keys to values whereas balancing studying and forgetting.
MIRAS defines any sequence mannequin by way of 4 design selections:
- Reminiscence construction for instance a vector, linear map, or MLP
- Attentional bias the interior loss that defines what similarities the reminiscence cares about
- Retention gate the regularizer that retains the reminiscence near its previous state
- Reminiscence algorithm the net optimization rule, typically gradient descent with momentum
Utilizing this lens, MIRAS recovers a number of households:
- Hebbian model linear recurrent fashions and RetNet as dot product based mostly associative reminiscences
- Delta rule fashions reminiscent of DeltaNet and Gated DeltaNet as MSE based mostly reminiscences with worth alternative and particular retention gates
- Titans LMM as a nonlinear MSE based mostly reminiscence with native and world retention optimized by gradient descent with momentum
Crucially, MIRAS then strikes past the same old MSE or dot product goals. The analysis workforce constructs new attentional biases based mostly on Lₚ norms, sturdy Huber loss and sturdy optimization, and new retention gates based mostly on divergences over likelihood simplices, elastic internet regularization and Bregman divergence.
From this design house, the analysis workforce instantiate three consideration free fashions:
- Moneta makes use of a 2 layer MLP reminiscence with Lₚ attentional bias and a hybrid retention gate based mostly on generalized norms
- Yaad makes use of the identical MLP reminiscence with Huber loss attentional bias and a overlook gate associated to Titans
- Memora makes use of regression loss as attentional bias and a KL divergence based mostly retention gate over a likelihood simplex model reminiscence.
These MIRAS variants substitute consideration blocks in a Llama model spine, use depthwise separable convolutions within the Miras layer, and may be mixed with Sliding Window Consideration in hybrid fashions. Coaching stays parallel by chunking sequences and computing gradients with respect to the reminiscence state from the earlier chunk.
In analysis experiments, Moneta, Yaad and Memora match or surpass robust linear recurrent fashions and Transformer++ on language modeling, commonsense reasoning and recall intensive duties, whereas sustaining linear time inference.
Key Takeaways
- Titans introduces a deep neural long run reminiscence that learns at take a look at time, utilizing gradient descent on an L2 associative reminiscence loss so the mannequin selectively shops solely shocking tokens whereas protecting updates parallelizable on accelerators.
- Titans combines consideration with neural reminiscence for lengthy context, utilizing branches like core, contextual reminiscence and protracted reminiscence so consideration handles quick vary precision and the neural module maintains info over sequences past 2,000,000 tokens.
- Titans outperforms robust linear RNNs and Transformer++ baselines, together with Mamba-2 and Gated DeltaNet, on language modeling and commonsense reasoning benchmarks at comparable parameter scales, whereas staying aggressive on throughput.
- On excessive lengthy context recall benchmarks reminiscent of BABILong, Titans achieves increased accuracy than all baselines, together with bigger consideration fashions reminiscent of GPT 4, whereas utilizing fewer parameters and nonetheless enabling environment friendly coaching and inference.
- MIRAS gives a unifying framework for sequence fashions as associative reminiscences, defining them by reminiscence construction, attentional bias, retention gate and optimization rule, and yields new consideration free architectures reminiscent of Moneta, Yaad and Memora that match or surpass linear RNNs and Transformer++ on lengthy context and reasoning duties.
Try the Technical particulars. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling complicated datasets into actionable insights.