

{kind=link}
Why do present audio AI fashions usually carry out worse once they generate longer reasoning as a substitute of grounding their selections within the precise sound. StepFun analysis staff releases Step-Audio-R1, a brand new audio LLM designed for check time compute scaling, tackle this failure mode by exhibiting that the accuracy drop with chain of thought just isn’t an audio limitation however a coaching and modality grounding drawback?
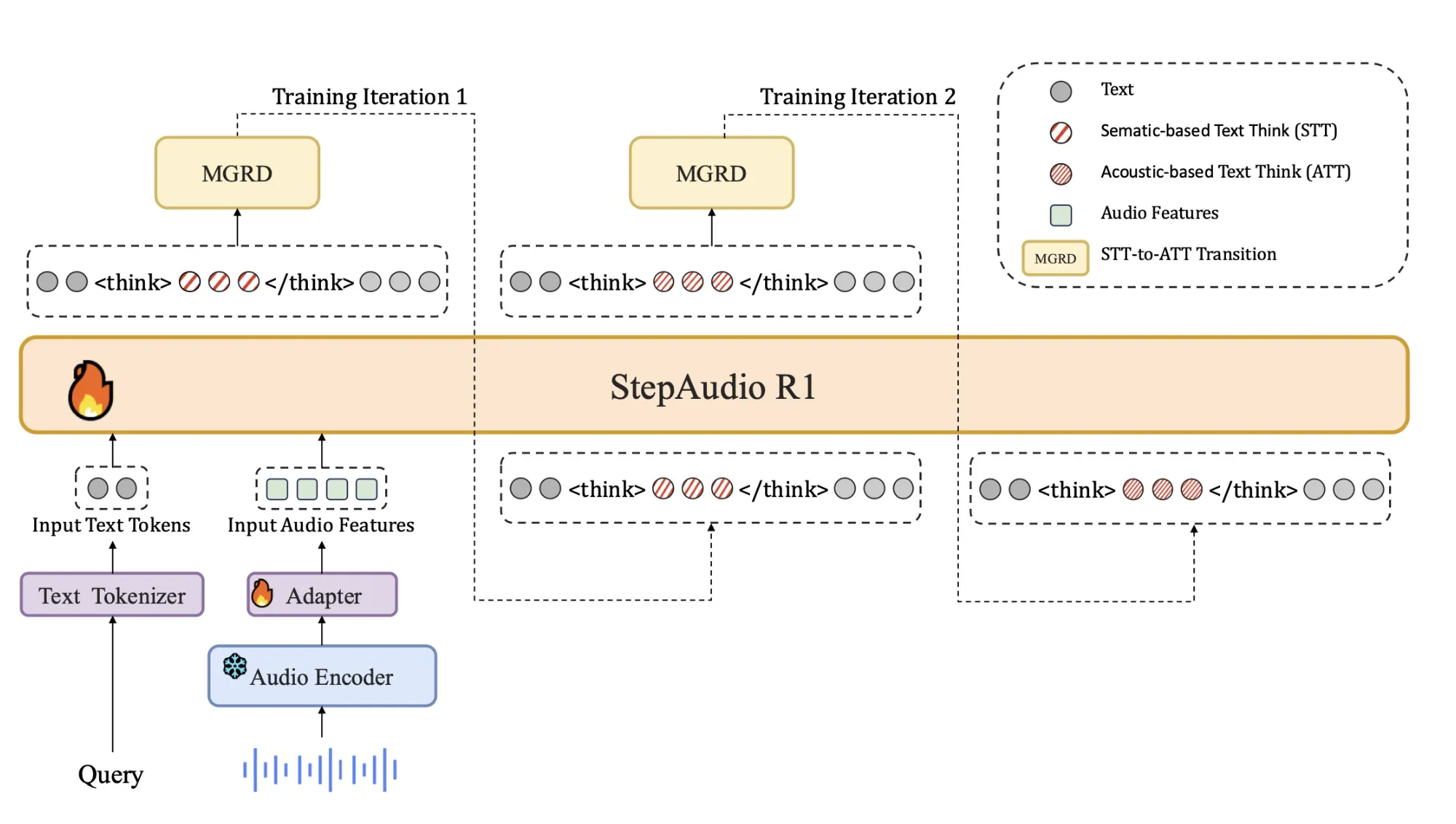
The Core Drawback, Audio Fashions Cause over Textual content Surrogates
Most present audio fashions inherit their reasoning conduct from textual content coaching. They study to purpose as in the event that they learn transcripts, not as in the event that they hear. The StepFun staff calls this Textual Surrogate Reasoning. The mannequin makes use of imagined phrases and descriptions as a substitute of acoustic cues corresponding to pitch contour, rhythm, timbre or background noise patterns.
This mismatch explains why longer chain of thought usually hurts efficiency in audio. The mannequin spends extra tokens elaborating unsuitable or modality irrelevant assumptions. Step-Audio-R1 assaults this by forcing the mannequin to justify solutions utilizing acoustic proof. The coaching pipeline is organized round Modality Grounded Reasoning Distillation, MGRD, which selects and distills reasoning traces that explicitly reference audio options.
Structure
The structure stays near the earlier Step Audio methods:
- A Qwen2 based mostly audio encoder processes uncooked waveforms at 25 Hz.
- An audio adaptor downsamples the encoder output by an element of two, to 12.5 Hz, and aligns frames to the language token stream.
- A Qwen2.5 32B decoder consumes the audio options and generates textual content.
The decoder at all times produces an express reasoning block inside <assume> and </assume> tags, adopted by the ultimate reply. This separation lets coaching targets form the construction and content material of reasoning with out dropping give attention to job accuracy. The mannequin is launched as a 33B parameter audio textual content to textual content mannequin on Hugging Face beneath Apache 2.0.
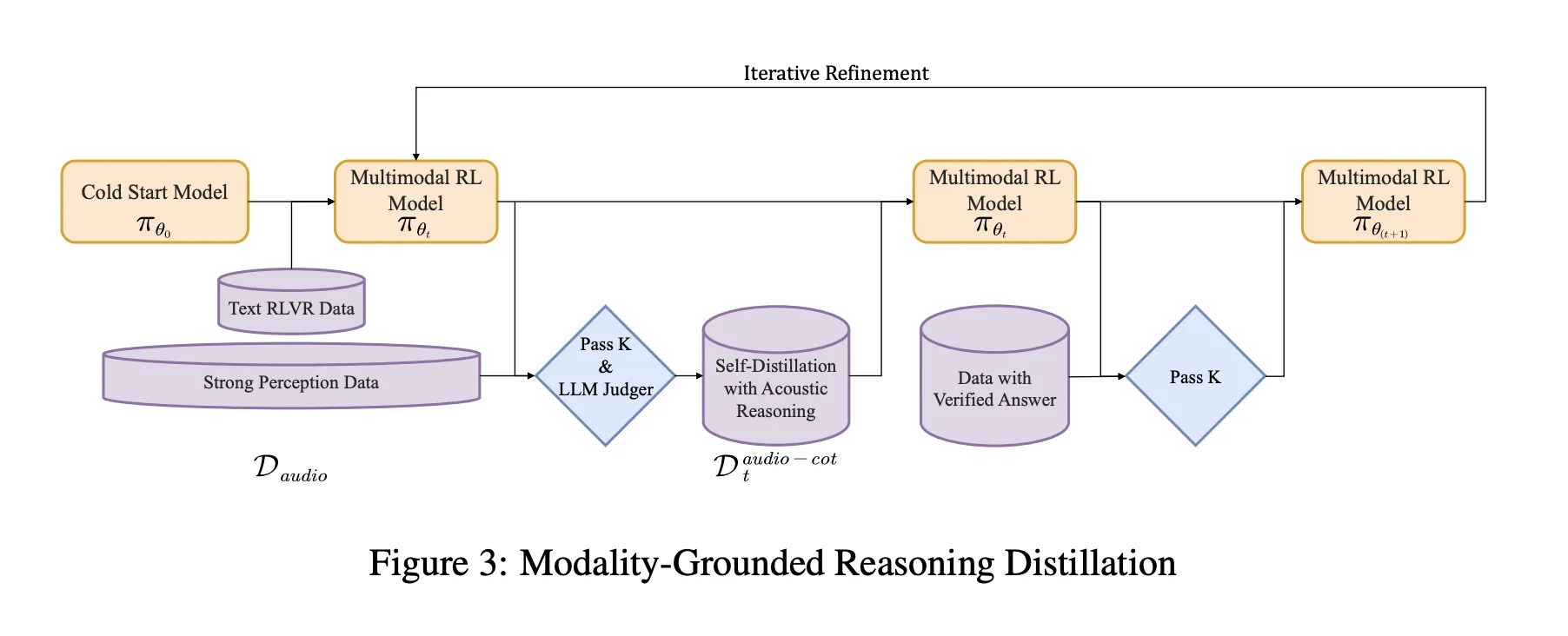
Coaching Pipeline, from Chilly Begin to Audio Grounded RL
The pipeline has a supervised chilly begin stage and a reinforcement studying stage that each combine textual content and audio duties.
Chilly begin makes use of about 5 million examples, overlaying 1 billion tokens of textual content solely knowledge and 4 billion tokens from audio paired knowledge. Audio duties embrace computerized speech recognition, paralinguistic understanding and audio query textual content reply fashion dialogs. A fraction of the audio knowledge carries audio chain of thought traces generated by an earlier mannequin. Textual content knowledge covers multi flip dialog, data query answering, math and code reasoning. All samples share a format the place reasoning is wrapped in <assume> tags, even when the reasoning block is initially empty.
Supervised studying trains Step-Audio-R1 to comply with this format and to generate helpful reasoning for each audio and textual content. This offers a baseline chain of thought conduct, however it’s nonetheless biased towards textual content based mostly reasoning.
Modality Grounded Reasoning Distillation MGRD
MGRD is utilized in a number of iterations. For every spherical, the analysis staff samples audio questions the place the label is determined by actual acoustic properties. For instance, questions on speaker emotion, background occasions in sound scenes or musical construction. The present mannequin produces a number of reasoning and reply candidates per query. A filter retains solely chains that meet three constraints:
- They reference acoustic cues, not simply textual descriptions or imagined transcripts.
- They’re logically coherent as brief step-by-step explanations.
- Their ultimate solutions are right in line with labels or programmatic checks.
These accepted traces kind a distilled audio chain of thought dataset. The mannequin is okay tuned on this dataset along with the unique textual content reasoning knowledge. That is adopted by Reinforcement Studying with Verified Rewards, RLVR. For textual content questions, rewards are based mostly on reply correctness. For audio questions, the reward mixes reply correctness and reasoning format, with a typical weighting of 0.8 for accuracy and 0.2 for reasoning. Coaching makes use of PPO with about 16 responses sampled per immediate and helps sequences as much as round 10 240 tokens to permit lengthy deliberation.
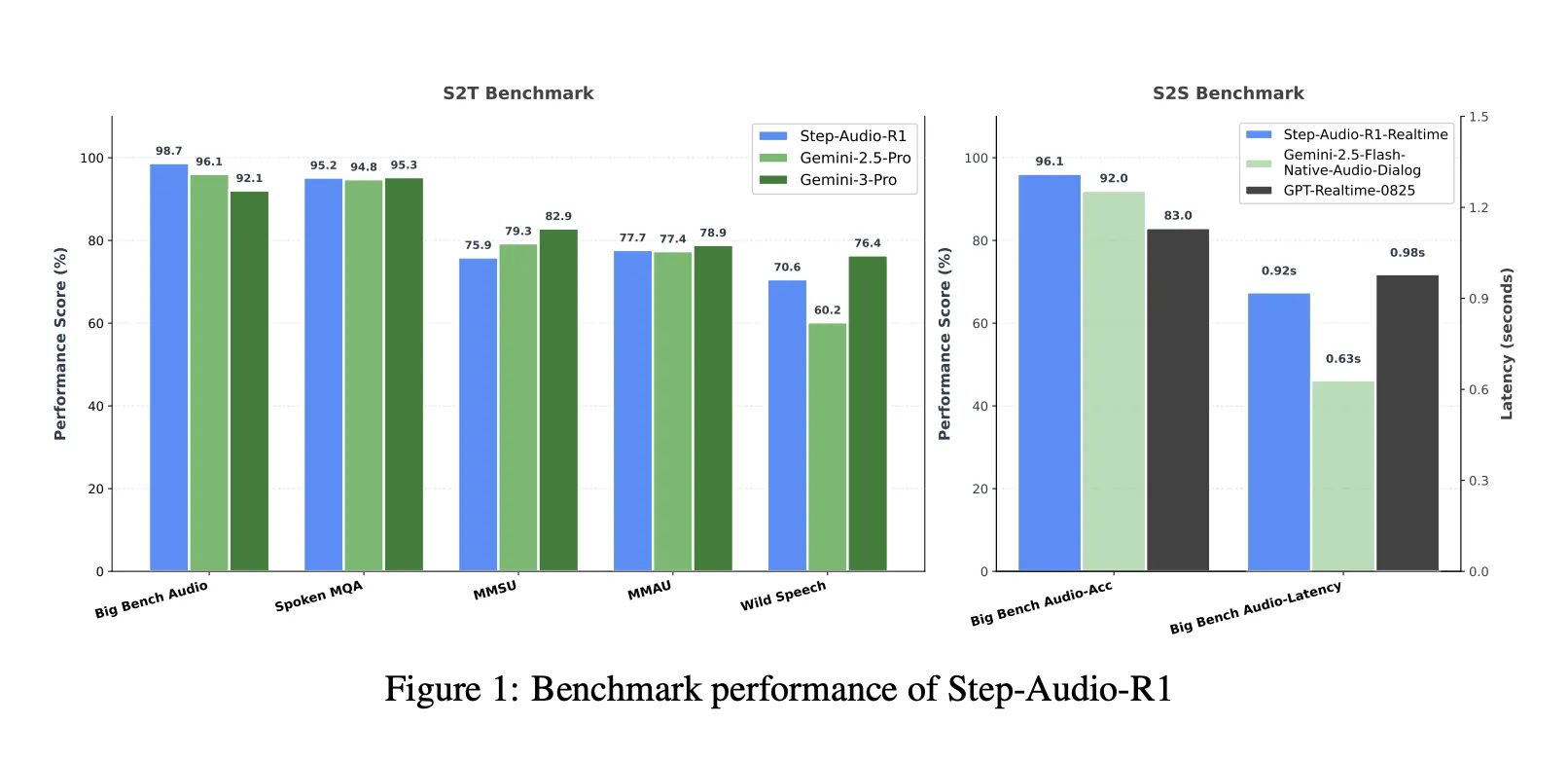
Benchmarks, closing the hole to Gemini 3 Professional
On a mixed speech to textual content benchmark suite that features Huge Bench Audio, Spoken MQA, MMSU, MMAU and Wild Speech, Step-Audio-R1 reaches a median rating of about 83.6 %. Gemini 2.5 Professional reviews about 81.5 % and Gemini 3 Professional reaches about 85.1 %. On Huge Bench Audio alone, Step-Audio-R1 reaches about 98.7 %, which is greater than each Gemini variations.
For speech to speech reasoning, the Step-Audio-R1 Realtime variant adopts hear whereas considering and assume whereas talking fashion streaming. On Huge Bench Audio speech to speech, it reaches about 96.1 % reasoning accuracy with first packet latency round 0.92 seconds. This rating surpasses GPT based mostly realtime baselines and Gemini 2.5 Flash fashion native audio dialogs whereas preserving sub second interplay.
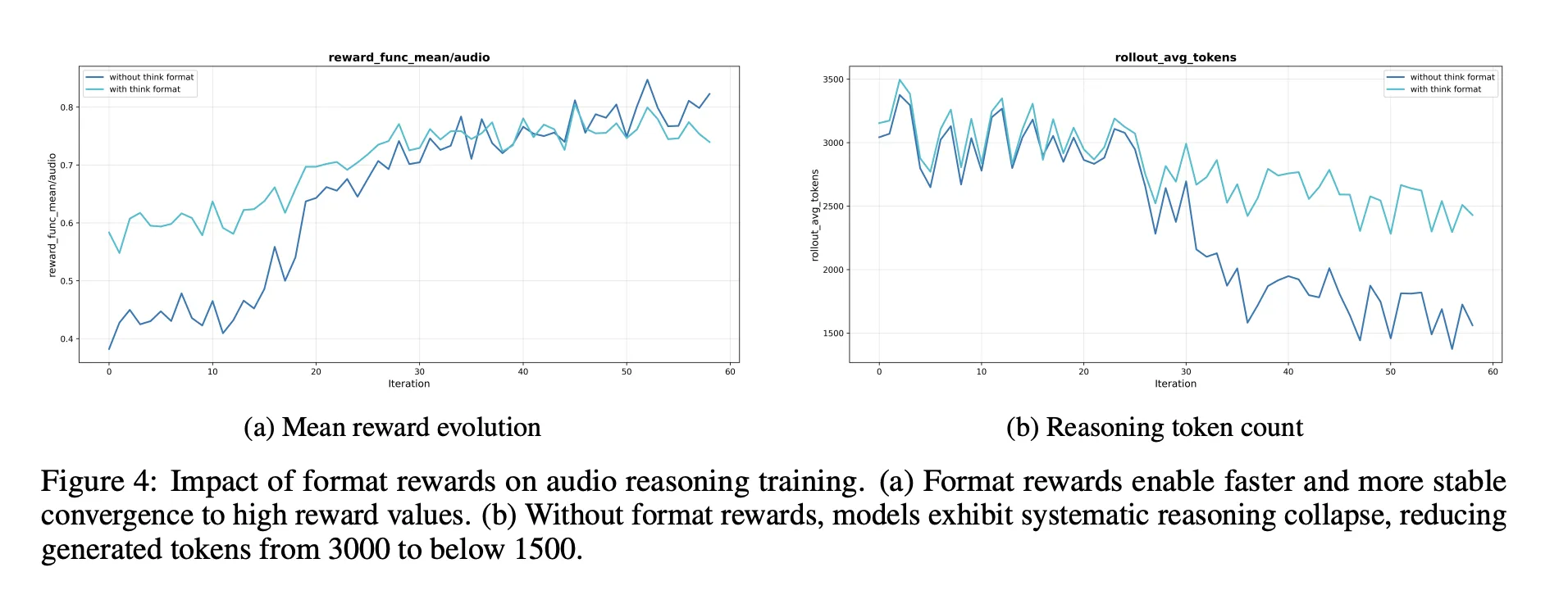
Ablations, what issues for audio reasoning
The ablation part gives a number of design indicators for engineers:
- A reasoning format reward is critical. With out it, reinforcement studying tends to shorten or take away chain of thought, which lowers audio benchmark scores.
- RL knowledge ought to goal medium issue issues. Deciding on questions the place go at 8 lies in a center band offers extra secure rewards and maintains lengthy reasoning.
- Scaling RL audio knowledge with out such choice doesn’t assist. High quality of prompts and labels issues greater than uncooked measurement.
The researchers additionally describe a self cognition correction pipeline that reduces the frequency of solutions corresponding to ‘I can solely learn textual content and can’t hear audio’ in a mannequin that’s educated to course of sound. This makes use of Direct Desire Optimization on curated choice pairs the place right conduct is to acknowledge and use audio enter.
Key Takeaways
- Step-Audio-R1 is among the first audio language mannequin that turns longer chain of thought right into a constant accuracy achieve for audio duties, fixing the inverted scaling failure seen in earlier audio LLMs.
- The mannequin explicitly targets Textual Surrogate Reasoning by utilizing Modality Grounded Reasoning Distillation, which filters and distills solely these reasoning traces that depend on acoustic cues corresponding to pitch, timbre and rhythm as a substitute of imagined transcripts.
- Architecturally, Step-Audio-R1 combines a Qwen2 based mostly audio encoder with an adaptor and a Qwen2.5 32B decoder that at all times generates
<assume>reasoning segments earlier than solutions, and is launched as a 33B audio textual content to textual content mannequin beneath Apache 2.0. - Throughout complete audio understanding and reasoning benchmarks overlaying speech, environmental sounds and music, Step-Audio-R1 surpasses Gemini 2.5 Professional and reaches efficiency akin to Gemini 3 Professional, whereas additionally supporting a realtime variant for low latency speech to speech interplay.
- The coaching recipe combines massive scale supervised chain of thought, modality grounded distillation and Reinforcement Studying with Verified Rewards, offering a concrete and reproducible blueprint for constructing future audio reasoning fashions that truly profit from check time compute scaling.

Editorial Notes
Step-Audio-R1 is a vital launch as a result of it converts chain of thought from a legal responsibility into a great tool for audio reasoning by instantly addressing Textual Surrogate Reasoning with Modality Grounded Reasoning Distillation and Reinforcement Studying with Verified Rewards. It exhibits that check time compute scaling can profit audio fashions when reasoning is anchored in acoustic options and delivers benchmark outcomes akin to Gemini 3 Professional whereas remaining open and virtually usable for engineers. Total this analysis work turns prolonged deliberation in audio LLMs from a constant failure mode right into a controllable and reproducible design sample.
Try the Paper, Repo, Challenge Web page and Mannequin Weights. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.