

{kind=link}
Black Forest Labs has launched FLUX.2, its second technology picture technology and enhancing system. FLUX.2 targets actual world inventive workflows comparable to advertising and marketing property, product pictures, design layouts, and sophisticated infographics, with enhancing assist as much as 4 megapixels and robust management over structure, logos, and typography.
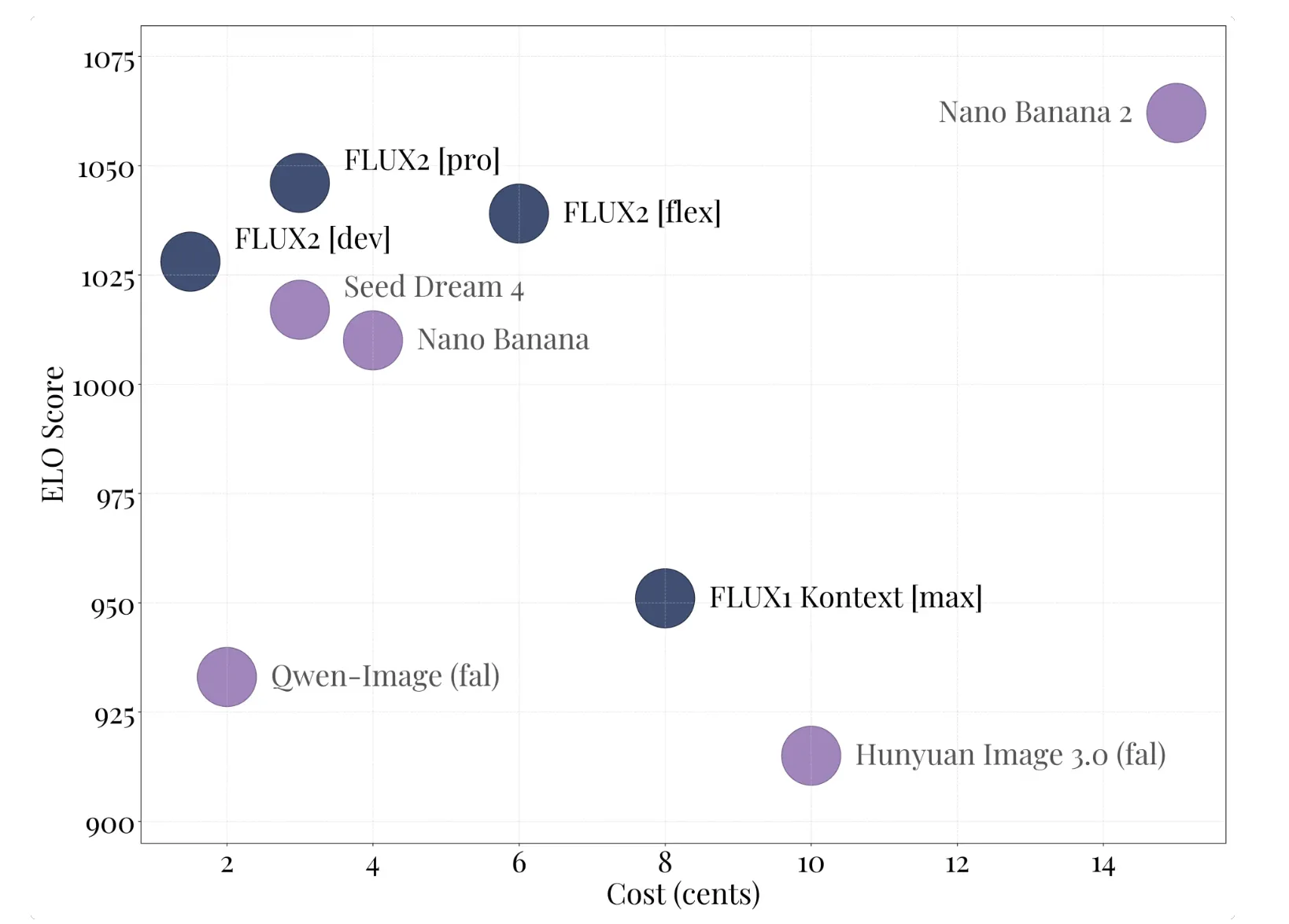
FLUX.2 product household and FLUX.2 [dev]
The FLUX.2 household spans hosted APIs and open weights:
- FLUX.2 [pro] is the managed API tier. It targets state-of-the-art high quality relative to closed fashions, with excessive immediate adherence and low inference value, and is accessible within the BFL Playground, BFL API, and associate platforms.
- FLUX.2 [flex] exposes parameters comparable to variety of steps and steering scale, so builders can commerce off latency, textual content rendering accuracy, and visible element.
- FLUX.2 [dev] is the open weight checkpoint, derived from the bottom FLUX.2 mannequin. It’s described as essentially the most highly effective open weight picture technology and enhancing mannequin, combining textual content to picture and multi picture enhancing in a single checkpoint, with 32 billion parameters.
- FLUX.2 [klein] is a coming open supply Apache 2.0 variant, measurement distilled from the bottom mannequin for smaller setups, with lots of the similar capabilities.
All variants assist picture enhancing from textual content and a number of references in a single mannequin, which removes the necessity to preserve separate checkpoints for technology and enhancing.
Structure, latent move, and the FLUX.2 VAE
FLUX.2 makes use of a latent move matching structure. The core design {couples} a Mistral-3 24B imaginative and prescient language mannequin with a rectified move transformer that operates on latent picture representations. The imaginative and prescient language mannequin offers semantic grounding and world data, whereas the transformer spine learns spatial construction, supplies, and composition.
The mannequin is educated to map noise latents to picture latents beneath textual content conditioning, so the identical structure helps each textual content pushed synthesis and enhancing. For enhancing, latents are initialized from current photographs, then up to date beneath the identical move course of whereas preserving construction.
A brand new FLUX.2 VAE defines the latent house. It’s designed to stability learnability, reconstruction high quality, and compression, and is launched individually on Hugging Face beneath an Apache 2.0 license. This autoencoder is the spine for all FLUX.2 move fashions and will also be reused in different generative programs.
Capabilities for manufacturing workflows
The FLUX.2 Docs and Diffusers integration spotlight a number of key capabilities:
- Multi reference assist: FLUX.2 can mix as much as 10 reference photographs to take care of character id, product look, and magnificence throughout outputs.
- Photoreal element at 4MP: the mannequin can edit and generate photographs as much as 4 megapixels, with improved textures, pores and skin, materials, palms, and lighting appropriate for product pictures and picture like use instances.
- Sturdy textual content and structure rendering: it will possibly render advanced typography, infographics, memes, and consumer interface layouts with small legible textual content, which is a typical weak point in lots of older fashions.
- World data and spatial logic: the mannequin is educated for extra grounded lighting, perspective, and scene composition, which reduces artifacts and the artificial look.

Key Takeaways
- FLUX.2 is a 32B latent move matching transformer that unifies textual content to picture, picture enhancing, and multi reference composition in a single checkpoint.
- FLUX.2 [dev] is the open weight variant, paired with the Apache 2.0 FLUX.2 VAE, whereas the core mannequin weights use the FLUX.2-dev Non Industrial License with obligatory security filtering.
- The system helps as much as 4 megapixel technology and enhancing, sturdy textual content and structure rendering, and as much as 10 visible references for constant characters, merchandise, and kinds.
- Full precision inference requires greater than 80GB VRAM, however 4 bit and FP8 quantized pipelines with offloading make FLUX.2 [dev] usable on 18GB to 24GB GPUs and even 8GB playing cards with adequate system RAM.
Editorial Notes
FLUX.2 is a crucial step for open weight visible technology, because it combines a 32B rectified move transformer, a Mistral 3 24B imaginative and prescient language mannequin, and the FLUX.2 VAE right into a single excessive constancy pipeline for textual content to picture and enhancing. The clear VRAM profiles, quantized variants, and robust integrations with Diffusers, ComfyUI, and Cloudflare Staff make it sensible for actual workloads, not solely benchmarks. This launch pushes open picture fashions nearer to manufacturing grade inventive infrastructure.
Try the Technical particulars, Mannequin weight and Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be a part of us on telegram as properly.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at reworking advanced datasets into actionable insights.