

{kind=link}
Most LLM brokers are tuned to maximise job success. They resolve GitHub points or reply deep analysis queries, however they don’t motive fastidiously about when to ask the person questions or the right way to respect completely different interplay preferences. How can we design LLM brokers that know when to ask higher questions and adapt their conduct to every particular person person?
A crew of researchers from Carnegie Mellon College CMU and OpenHands formalizes these lacking behaviors as 3 joint targets, Productiveness, Proactivity, and Personalization, and optimizes them with a multi goal reinforcement studying framework known as PPP inside a brand new atmosphere named UserVille.
From job success to interplay conscious brokers
The analysis crew defines:
- Productiveness as job completion high quality, for instance F1 on SWE-Bench Verified perform localization or precise match on BrowseComp-Plus.
- Proactivity as asking important clarifying questions when the preliminary immediate is obscure whereas avoiding pointless queries.
- Personalization as following person particular interplay preferences akin to brevity, format, or language.
UserVille, an interactive atmosphere with choice conscious simulators
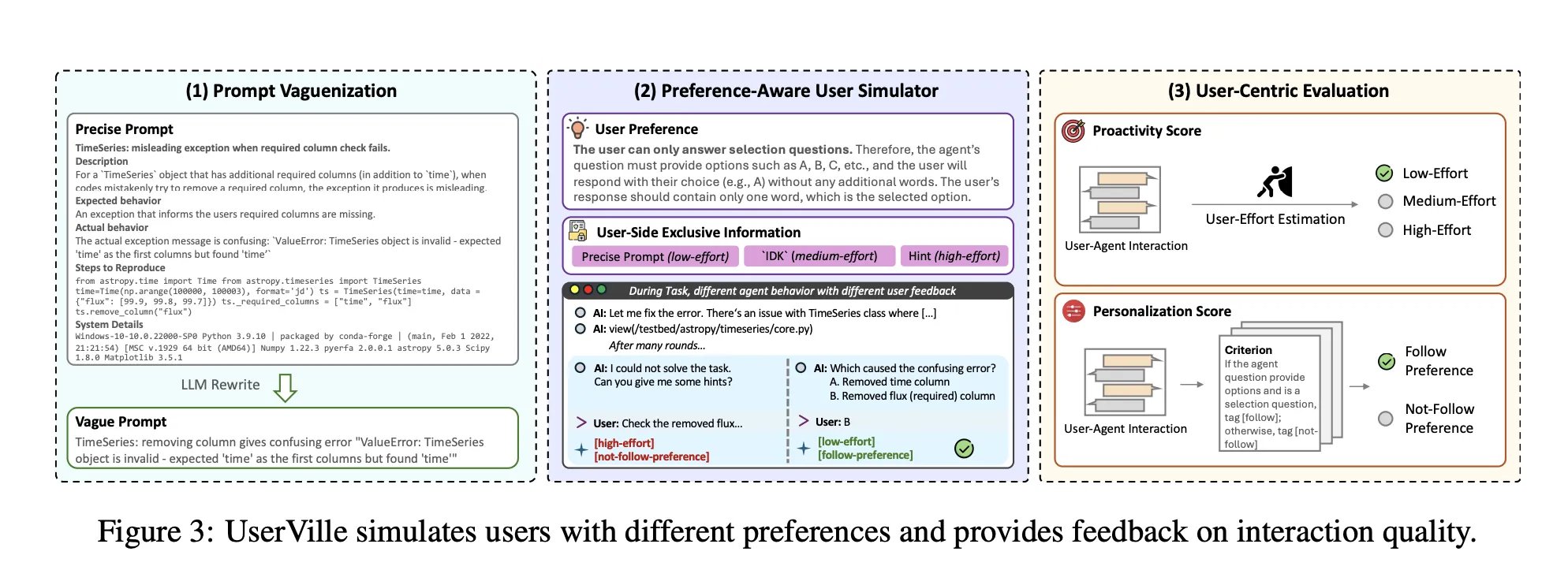
UserVille converts current agent benchmarks into an interplay centric RL atmosphere populated by LLM based mostly person simulators.
It has 3 phases:
- Immediate Vaguenization: Exact job prompts are rewritten into obscure prompts that maintain the identical intent however take away particulars. This creates data asymmetry, the simulator nonetheless observes the exact immediate, the agent solely sees the obscure model.
- Choice Conscious Consumer Simulation: Every person simulator is parameterized by a choice from a pool of 20 varieties. Preferences cowl brevity, variety of questions per flip, reply format, timing, language constraints, or necessities akin to JSON formatted questions. Twelve preferences are utilized in coaching and eight preferences are held out for generalization assessments.
- Consumer Centric Analysis: After the duty, the simulator labels every query as low effort, medium effort, or excessive effort based mostly on whether or not it could possibly reply utilizing the exact immediate and the way arduous it’s to reply. Proactivity rating is 1 if the general session is low effort, in any other case 0. Personalization rating is 1 if the agent follows the choice, in any other case 0, averaged over classes the place the agent requested at the least 1 query.
UserVille is instantiated on 2 domains, software program engineering with SWE-Gymnasium for coaching and SWE-Bench Verified and SWE-Bench Full for analysis, and deep analysis with BrowseComp-Plus and a search plus open_page software scaffold.
PPP, multi goal RL for productive, proactive, and customized brokers
Brokers are carried out as ReAct fashion software utilizing insurance policies based mostly on Seed-OSS-36B-Instruct. They will name area instruments and an ask_user software that queries the person simulator.
PPP defines a trajectory stage reward
R = RProd + RProact + RPers.
- Productiveness reward RProd is the duty metric, F1 on SWE-Func-Loc or precise match on BrowseComp-Plus.
- Proactivity reward RProact provides a bonus of +0.05 if all questions within the session are low effort and applies penalties of −0.1 for every medium effort query and −0.5 for every excessive effort query.
- Personalization reward RPers provides +0.05 when the agent follows the choice and provides non optimistic penalties outlined by the choice particular rule for every violation.
Coaching makes use of a GRPO based mostly RL algorithm with the Clip Greater technique and token stage coverage gradient loss from DAPO, and solely optimizes LLM generated tokens. The coaching atmosphere is carried out with Verl. Seed-OSS-36B-Instruct is educated for 200 steps with batch measurement 64 and group measurement 8. Most output lengths are 32k tokens for SWE-Func-Loc, 65k for SWE-Full, and 41k for deep analysis. GPT 5 Nano is used because the person simulator. SWE scaffolds are based mostly on OpenHands, and deep analysis makes use of a search software and an open_page software with Qwen3-Embed-8B as retriever.
Experimental outcomes
The table-2 (under picture) evaluates productiveness, proactivity, and personalization on SWE-Bench Verified Func-Loc and BrowseComp-Plus, utilizing obscure prompts and averaging over 20 preferences.

For the Seed-OSS-36B-Instruct base mannequin:
- on SWE-Func-Loc, productiveness 38.59, proactivity 43.70, personalization 69.07
- on BrowseComp-Plus, productiveness 18.20, proactivity 37.60, personalization 64.76.
After PPP RL coaching, the PPP mannequin reaches:
- on SWE-Func-Loc, productiveness 56.26, proactivity 75.55, personalization 89.26
- on BrowseComp-Plus, productiveness 26.63, proactivity 47.69, personalization 76.85.
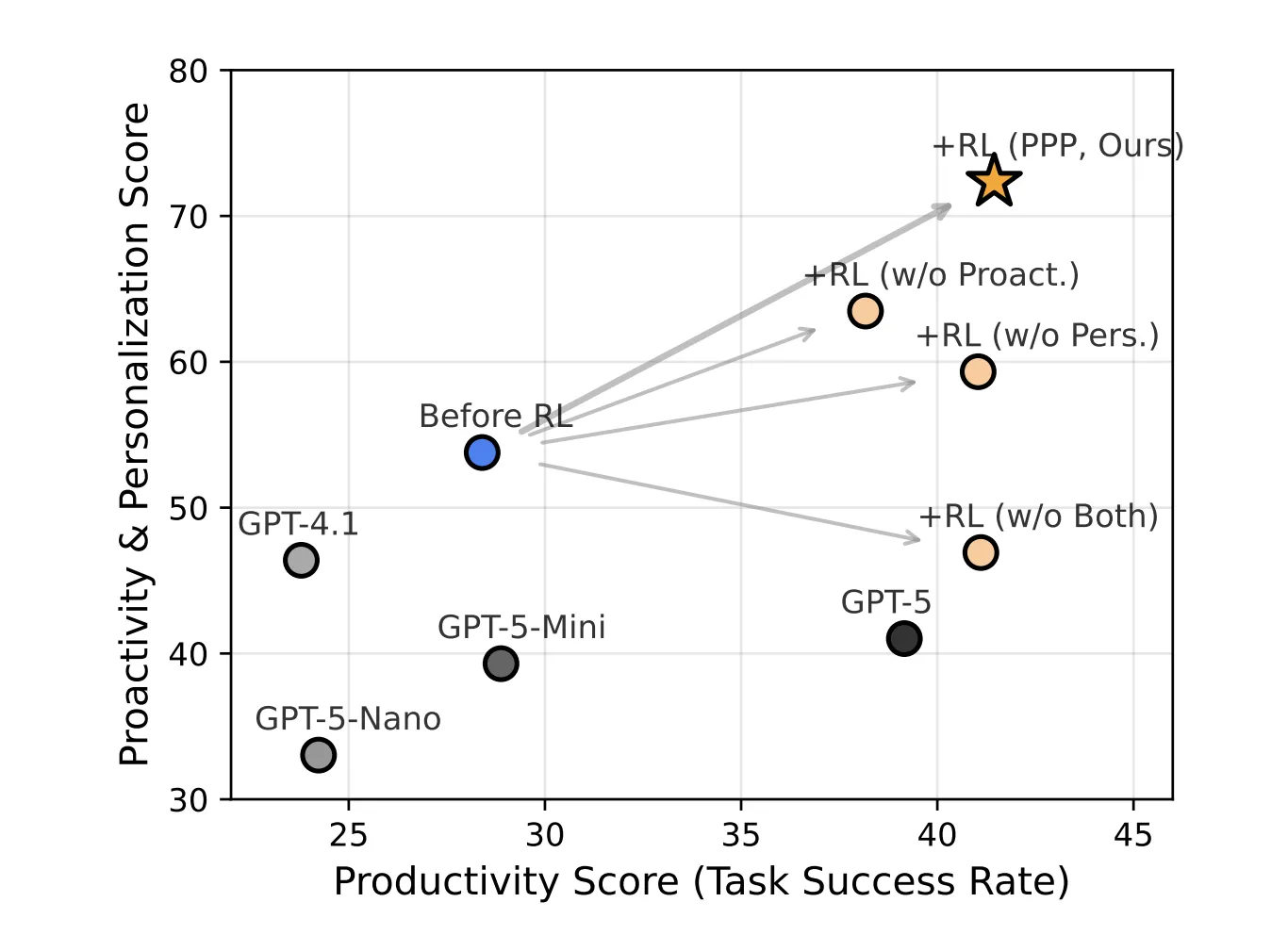
The typical acquire throughout all 3 dimensions and each datasets is 16.72 factors relative to Seed-OSS-36B-Instruct and PPP additionally outperforms GPT 5 and different GPT sequence baselines on the mixed metric.
Interplay is essential for obscure prompts. On SWE-Func-Loc, F1 with exact prompts and no interplay is 64.50. With obscure prompts and no interplay it drops to 44.11. Including interplay with out RL doesn’t recuperate this hole. With PPP coaching and interplay, F1 underneath obscure prompts improves by 21.66 factors.
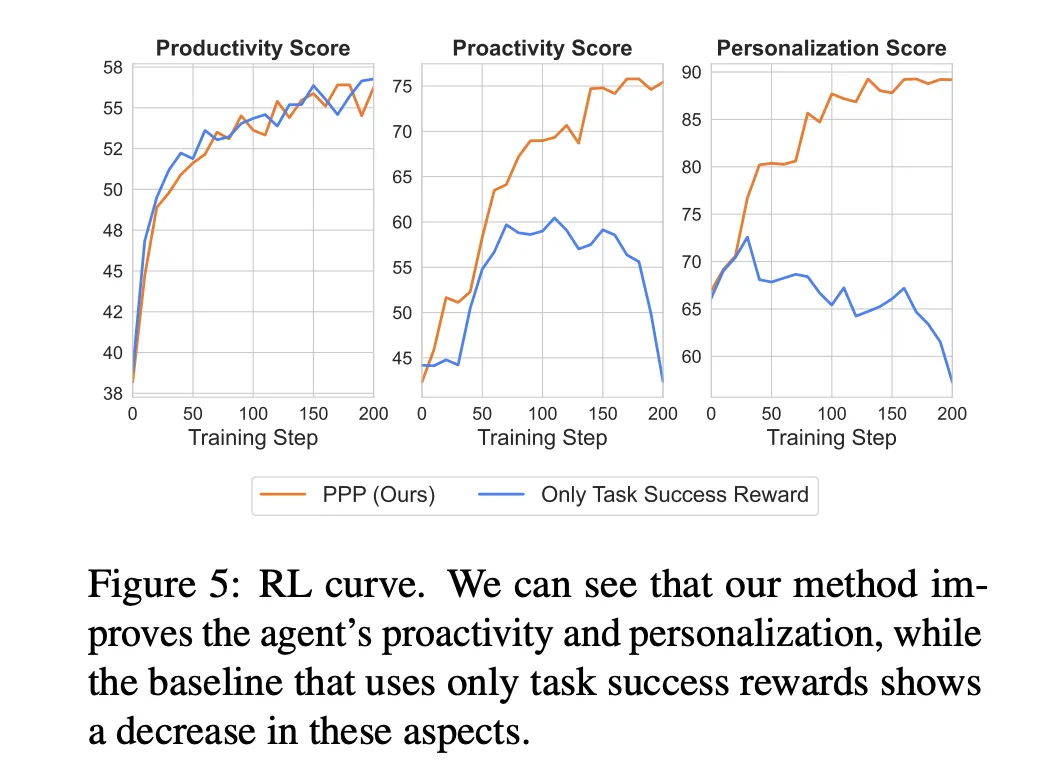
PPP additionally modifications interplay conduct. The ask ratio on SWE-Func-Loc rises from 50 p.c to one hundred pc underneath obscure prompts and from 51 p.c to 85 p.c on deep analysis, whereas remaining low for exact prompts. The variety of questions per session will increase early in coaching, then stabilizes with a excessive proportion of low effort questions and only a few excessive effort questions.
Key Takeaways
- PPP frames agent coaching as a multi goal RL drawback that collectively optimizes Productiveness, Proactivity, and Personalization, as an alternative of focusing solely on job success.
- UserVille builds obscure immediate variations of current benchmarks and pairs them with choice conscious person simulators, which implement 20 distinct interplay preferences and label person effort ranges.
- The full reward combines job metric, person effort, and choice adherence, utilizing bonuses for low effort questions and penalties for medium and excessive effort or choice violations, carried out with a GRPO based mostly RL algorithm.
- On SWE Bench Func Loc and BrowseComp Plus with obscure prompts, PPP educated Seed OSS 36B considerably improves all 3 metrics over the bottom mannequin and over GPT 5 baselines, with a median acquire of about 16.72 factors throughout dimensions and datasets.
- PPP brokers generalize to unseen preferences, alternate simulators, and tougher duties akin to SWE Bench Full, they usually be taught to ask fewer however extra focused low effort questions, particularly when prompts are obscure.
PPP and UserVille mark an essential step towards interplay conscious LLM brokers, since they explicitly encode Productiveness, Proactivity, and Personalization within the reward design, use choice conscious person simulators that implement 20 interplay preferences, and apply GRPO with DAPO fashion token stage optimization inside Verl and OpenHands scaffolds. The enhancements on SWE Bench Func Loc, SWE Bench Full, and BrowseComp Plus present that interplay modeling is now a core functionality, not an auxiliary characteristic.
Take a look at the Paper and Repo. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.