

{kind=link}
Are your LLM code benchmarks truly rejecting wrong-complexity options and interactive-protocol violations, or are they passing under-specified unit checks? A crew of researchers from UCSD, NYU, College of Washington, Princeton College, Canyon Crest Academy, OpenAI, UC Berkeley, MIT, College of Waterloo, and Sentient Labs introduce AutoCode, a brand new AI framework that lets LLMs create and confirm aggressive programming issues, mirroring the workflow of human downside setters. AutoCode reframes analysis for code-reasoning fashions by treating downside setting (not solely downside fixing) because the goal process. The system trains LLMs to supply competition-grade statements, check knowledge, and verdict logic that match official on-line judges at excessive charges. On a 7,538-problem benchmark constructed from prior datasets, AutoCode achieves 91.1% consistency with official judgments (FPR 3.7%, FNR 14.1%). On a separate, harder 720 latest Codeforces issues (together with interactive duties), the total framework reviews 98.7% consistency, 1.3% FPR, 1.2% FNR.
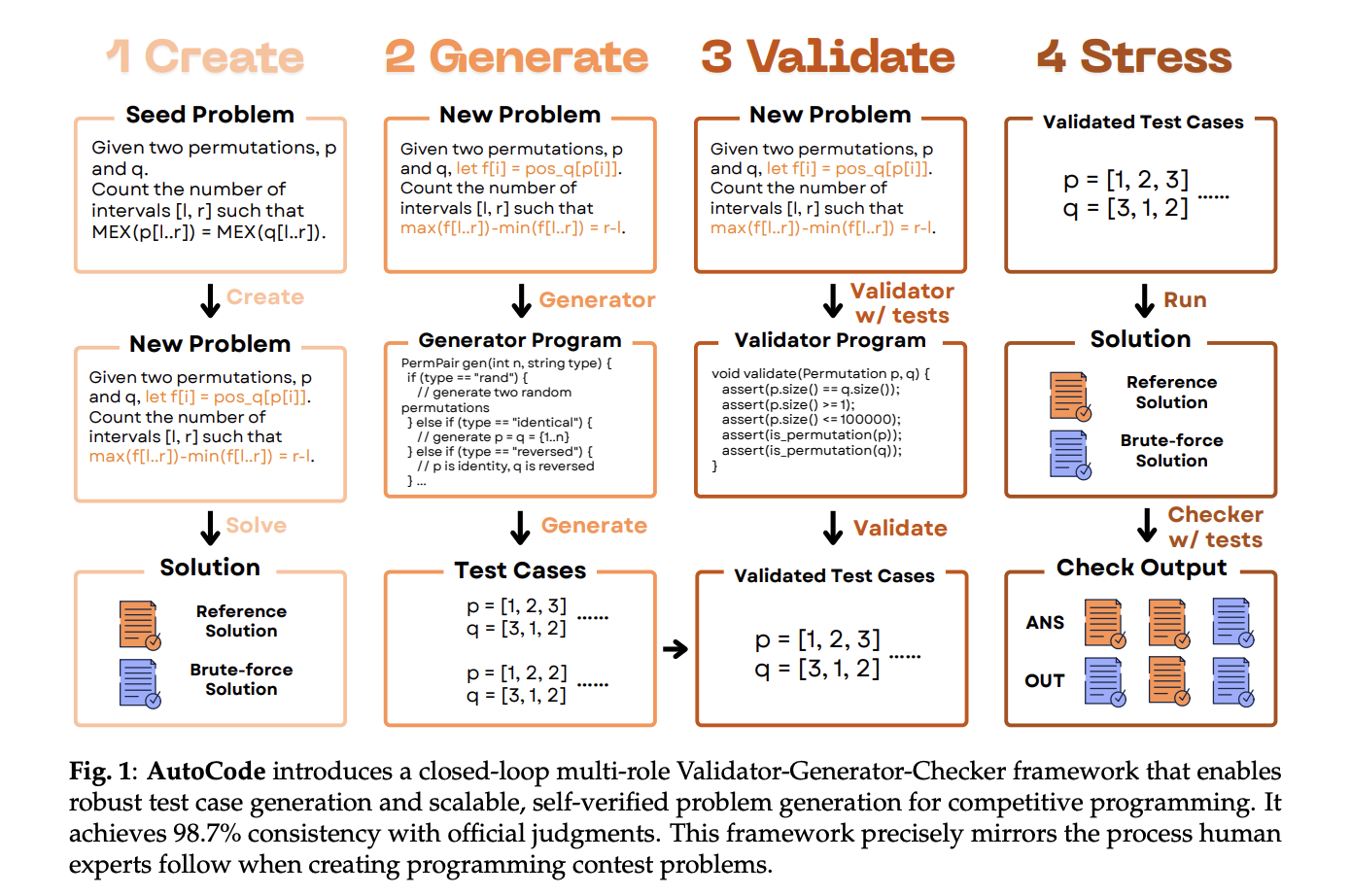
Why downside setting issues for analysis?
Public code benchmarks usually depend on under-specified checks that permit wrong-complexity or shortcut options go. That inflates scores and pollutes reinforcement alerts (rewarding fragile techniques). AutoCode’s validator-first method and adversarial check technology purpose to cut back false positives (FPR)—incorrect applications that go—and false negatives (FNR)—appropriate applications rejected as a result of malformed inputs.
The core loop: Validator → Generator → Checker
AutoCode runs a closed loop that mirrors human contest workflows, however every step is chosen from LLM-generated candidates utilizing focused in-framework checks.
1) Validator (decrease FNR by imposing enter legality)
The system first asks an LLM to synthesize 40 analysis inputs—10 legitimate and 30 near-valid unlawful (e.g., off-by-one boundary violations). It then prompts the LLM for three candidate validator applications and selects the one which greatest classifies these circumstances. This prevents “appropriate” options from crashing on malformed knowledge.

2) Generator (cut back FPR by adversarial protection)
Three complementary methods produce check circumstances:
• Small-data exhaustion for boundary protection,
• Randomized + excessive circumstances (overflows, precision, hash-collisions),
• TLE-inducing constructions to interrupt wrong-complexity options.
Invalid circumstances are filtered by the chosen validator; then circumstances are deduplicated and bucket-balanced earlier than sampling.

3) Checker (verdict logic)
The checker compares contestant outputs with the reference resolution underneath advanced guidelines. AutoCode once more generates 40 checker situations and three candidate checker applications, retains solely situations with validator-approved inputs, and selects one of the best checker by accuracy in opposition to the 40 labeled situations.

4) Interactor (for interactive issues)
For duties that require dialogue with the decide, AutoCode introduces a mutant-based interactor: it makes small logical edits (“mutants”) to the reference resolution, selects interactors that settle for the true resolution however reject the mutants, maximizing discrimination. This addresses a niche in earlier public datasets that prevented interactives.

Twin verification permits new issues (not simply checks for current ones)
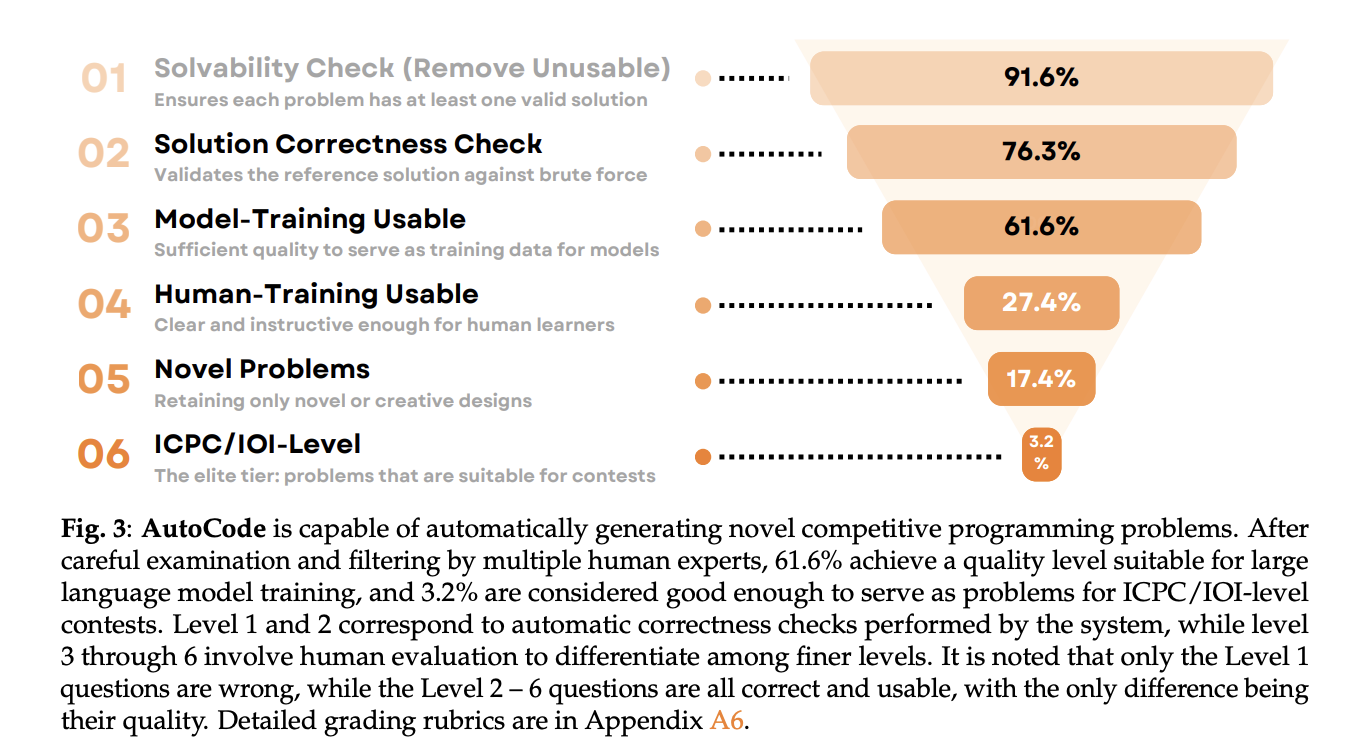
AutoCode can generate novel downside variants ranging from a random “seed” Codeforces downside (<2200 Elo). The LLM drafts a brand new assertion and two options: an environment friendly reference and a less complicated brute-force baseline. An issue is accepted provided that the reference output matches brute pressure throughout the generated check suite (the brute pressure could TLE on giant circumstances however serves as floor reality on small/exhaustive circumstances). This dual-verification protocol filters ~27% of error-prone objects, lifting reference-solution correctness from 86% → 94% earlier than human evaluate.
Human specialists then grade the survivors on solvability, resolution correctness, high quality, novelty, issue. After filtering, 61.6% are usable for mannequin coaching, 76.3% for human coaching, and 3.2% are ICPC/IOI-level issues. Problem sometimes will increase relative to the seed, and issue acquire correlates with perceived high quality.
Understanding the outcomes
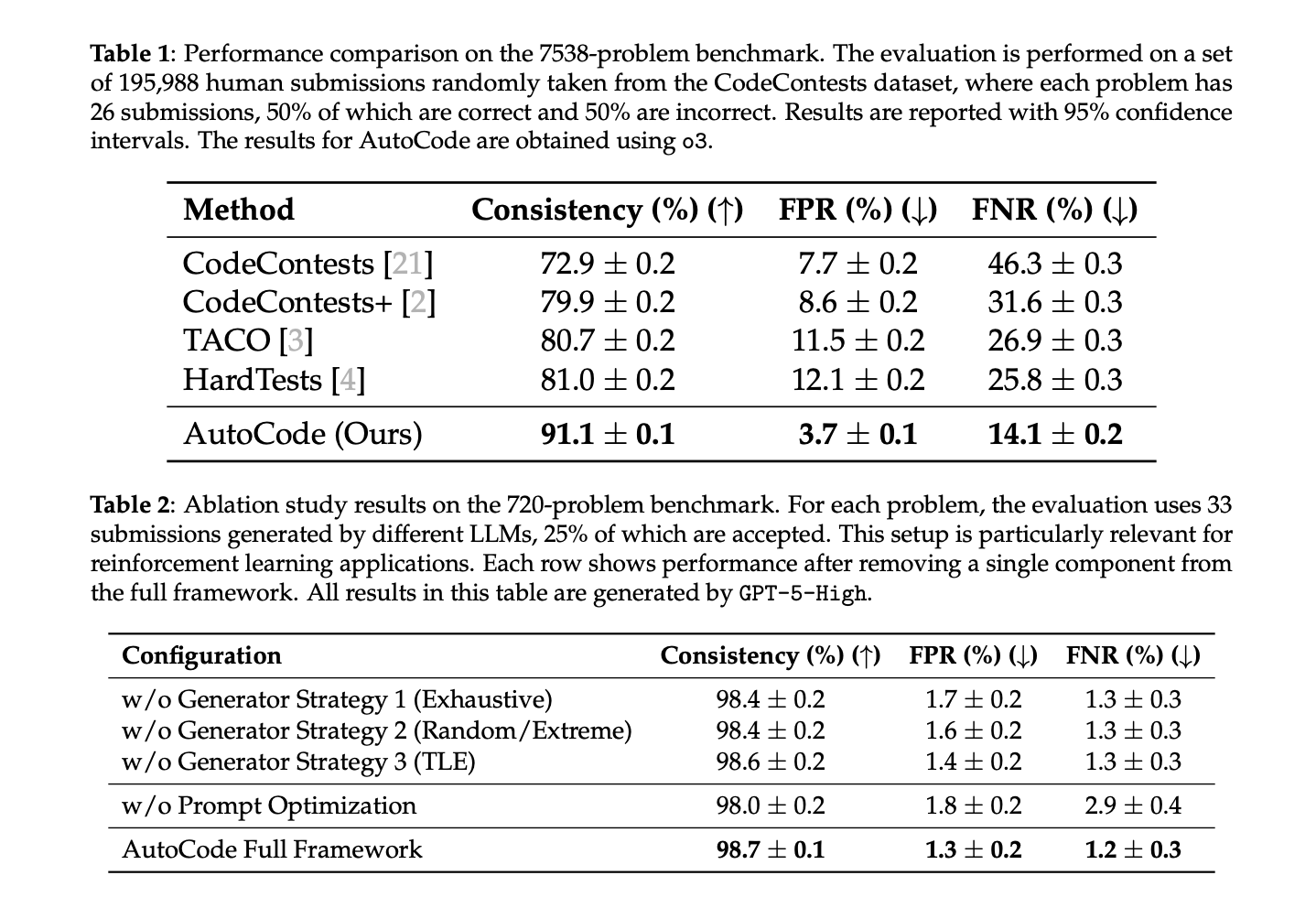
Current issues (7,538 complete; 195,988 human submissions). AutoCode: 91.1% consistency, 3.7% FPR, 14.1% FNR, vs 72.9–81.0% consistency for prior turbines (CodeContests, CodeContests+, TACO, HardTests).
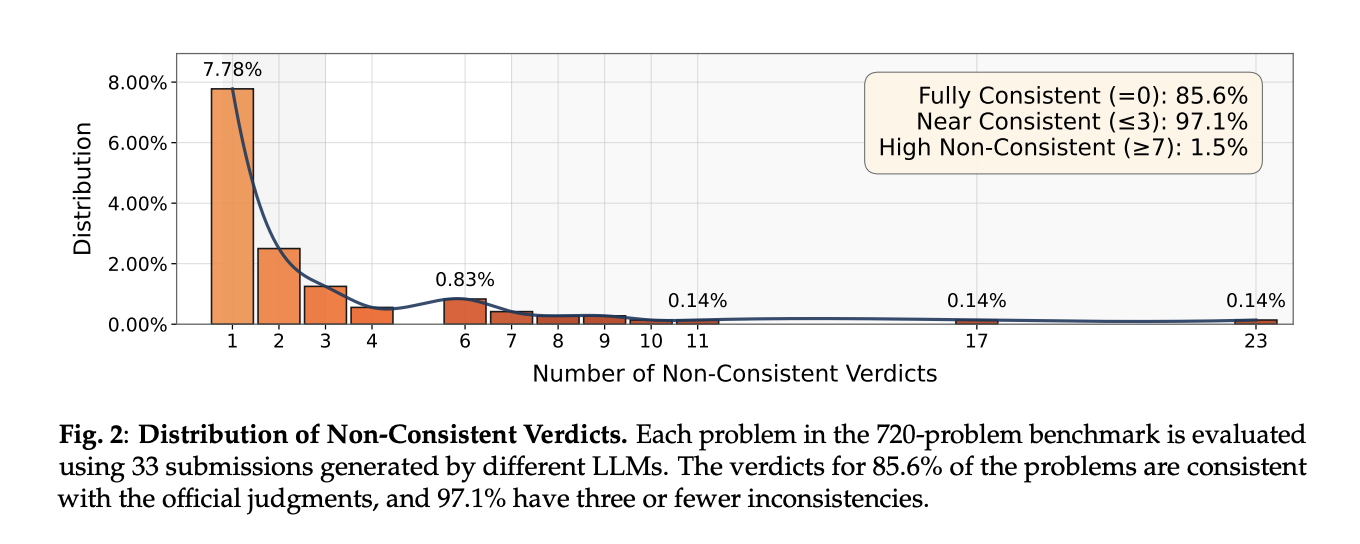
Current Codeforces issues (720, unfiltered; contains interactives). AutoCode: 98.7% consistency, 1.3% FPR, 1.2% FNR. Ablations present all three generator methods and immediate optimization contribute: eradicating immediate optimization drops consistency to 98.0% and greater than doubles FNR to 2.9%.
Key Takeaways
- AutoCode {couples} a Validator–Generator–Checker (+Interactor) loop with twin verification (reference vs. brute-force) to construct contest-grade check suites and new issues.
- On held-out issues, AutoCode’s check suites attain ~99% consistency with official judges, surpassing prior turbines like HardTests (<81%).
- For latest Codeforces duties (together with interactives), the total framework reviews ~98.7% consistency with ~1.3% FPR and ~1.2% FNR.
- The mutant-based interactor reliably accepts the true resolution whereas rejecting mutated variants, bettering analysis for interactive issues.
- Human specialists charge a large fraction of AutoCode-generated objects as training-usable and a non-trivial share as contest-quality, aligning with the LiveCodeBench Professional program’s goals.
AutoCode is a sensible repair for present code benchmarks. It facilities downside setting and makes use of a closed-loop Validator–Generator–Checker (+Interactor) pipeline with twin verification (reference vs. brute-force). This construction reduces false positives/negatives and yields judge-aligned consistency (≈99% on held-out issues; 98.7% on latest Codeforces, together with interactives). The method standardizes constraint legality, adversarial protection, and protocol-aware judging, which makes downstream RL reward alerts cleaner. Its placement underneath LiveCodeBench Professional matches a hallucination-resistant analysis program that emphasizes expert-checked rigor.
Take a look at the Paper and Venture. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you’ll be able to be part of us on telegram as nicely.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.