

{kind=link}
It is a visitor publish by Supreet Padhi, Expertise Architect, and Manasa Ramesh, Expertise Architect at Exactly in partnership with AWS.
Enterprises depend on mainframes to run mission-critical functions and retailer important information, enabling real-time operations that assist obtain enterprise aims. These organizations face a standard problem: methods to unlock the worth of their mainframe information in right this moment’s cloud-first world whereas sustaining system stability and information high quality. Modernizing these methods is crucial for competitiveness and innovation.
The digital transformation crucial has made mainframe information integration with cloud providers a strategic precedence for enterprises worldwide. Organizations that may seamlessly bridge their mainframe environments with fashionable cloud platforms acquire important aggressive benefits by way of improved agility, lowered operational prices, and enhanced analytics capabilities. Nonetheless, implementing such integrations presents distinctive technical challenges that require specialised options. A number of the challenges embrace changing EBCDIC information to ASCII, the place the dealing with of information sorts is exclusive to the mainframe, reminiscent of binary information and COMP information. Information saved in Digital Storage Entry Methodology (VSAM) recordsdata could be fairly advanced attributable to practices to retailer a number of totally different file sorts in a single file. To deal with these challenges, Exactly—a worldwide chief in information integrity, serving over 12,000 prospects—has partnered with Amazon Internet Companies (AWS) to allow real-time synchronization between mainframe methods and Amazon Relational Database Service (Amazon RDS). For extra on this collaboration, take a look at our earlier weblog publish: Unlock Mainframe Information with Exactly Join and Amazon Aurora.
On this publish, we introduce another structure to synchronize mainframe information to the cloud utilizing Amazon Managed Streaming for Apache Kafka (Amazon MSK) for higher flexibility and scalability. This event-driven method offers extra prospects for mainframe information integration and modernization methods.
A key enhancement on this resolution is the usage of the AWS Mainframe Modernization – Information Replication for IBM z/OS Amazon Machine Picture (AMI) out there in AWS Market, which simplifies deployment and reduces implementation time.
Actual-time processing and event-driven structure advantages
Actual-time processing makes information actionable inside seconds reasonably than ready for batch processing cycles. For instance, monetary establishments reminiscent of World Funds have leveraged this resolution to modernize mission-critical banking operations, together with funds processing. By migrating these operations to the AWS Cloud, they enhanced consumer expertise, improved scalability and maintainability, whereas enabling superior fraud detection – all with out impacting the efficiency of current mainframe methods. Change information seize (CDC) allows this by figuring out database adjustments and delivering them in actual time to cloud environments.
CDC presents two key benefits for mainframe modernization:
- Incremental information motion – Eliminates disruptive bulk extracts by streaming solely modified information to cloud targets, minimizing system influence and making certain information foreign money
- Actual-time synchronization – Retains cloud functions in sync with mainframe methods, enabling fast insights and responsive operations
Answer overview
On this publish, we offer an in depth implementation information for streaming mainframe information adjustments from DB2z by way of AWS Mainframe Modernization – Information Replication for IBM z/OS AMI to Amazon MSK after which making use of these adjustments to Amazon Relational Database Service (Amazon RDS) for PostgreSQL utilizing MSK Join with the Confluent JDBC Sink Connector.
By introducing Amazon MSK into structure and streamlining deployment by way of the AWS Market AMI, we create new prospects for information distribution, transformation, and consumption that develop upon our beforehand demonstrated direct replication method. This streaming-based structure presents a number of extra advantages:
- Simplified deployment – Speed up implementation utilizing the preconfigured AWS Market AMI
- Decoupled methods – Separate the priority of information extraction from information consumption, permitting either side to scale independently
- Multi-consumer assist – Allow a number of downstream functions and providers to devour the identical information stream in accordance with their very own necessities
- Extensibility – Create a basis that may be prolonged to assist extra mainframe information sources reminiscent of IMS and VSAM, in addition to extra AWS targets utilizing MSK Join sink connectors
The next diagram illustrates the answer structure.
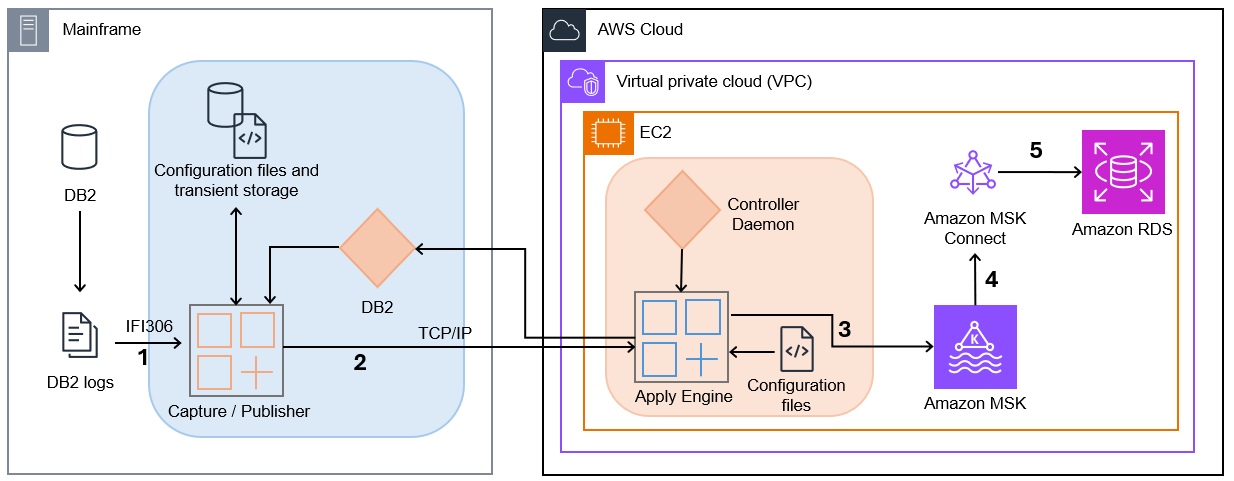
- Seize/Writer – Join CDC Seize/Writer captures Db2 adjustments from Db2 logs utilizing IFI 306 Learn and communicates captured information adjustments to a goal engine by way of TCP/IP.
- Controller Daemon – The Controller Daemon authenticates all connection requests, managing safe communication between the supply and goal environments.
- Apply Engine – The Apply Engine is a multifaceted and multifunctional element within the goal surroundings. It receives the adjustments from the Writer agent and applies the modified information to the goal Amazon MSK.
- Join CDC Single Message Rework (SMT) – Performs all vital information filtering, transformation, and augmentation required by the sink connector.
- JDBC Sink Connector – As information arrives, an occasion of the JDBC Sink Connector together with Apache Kafka writes the info to focus on tables in Amazon RDS.
This structure offers a clear separation between the info seize course of and the info consumption course of, permitting every to scale independently. The usage of MSK as an middleman allows a number of methods to devour the identical information stream, opening prospects for advanced occasion processing, real-time analytics, and integration with different AWS providers.
Conditions
To finish the answer, you want the next conditions:
- Set up AWS Mainframe Modernization – Information Replication for IBM z/OS
- Have entry to Db2z on mainframe from AWS utilizing your permitted connectivity between AWS and your mainframe
Answer walkthrough
The next code content material shouldn’t be deployed to manufacturing environments with out extra safety testing.
Configure the AWS Mainframe Modernization Information Replication with Exactly AMI on Amazon EC2
Observe the steps outlined at Exactly AWS Mainframe Modernization Information Replication. Upon the preliminary launch of the AMI, use the next command to hook up with the Amazon Elastic Compute Cloud (Amazon EC2) occasion:
Configure the serverless cluster
To create an Amazon Aurora PostgreSQL-Appropriate Version Serverless v2 cluster, full the next steps:
- Create a DB cluster through the use of the next AWS Command Line Interface (AWS CLI) command. Change the placeholder strings with values that correspond to your cluster’s subnet and subnet group IDs.
- Confirm the standing of the cluster through the use of the next command:
- Add a author DB occasion to the Aurora cluster:
- Confirm the standing of the author occasion:
Create a database within the PostgreSQL cluster
After your Aurora Serverless v2 cluster is working, it’s worthwhile to create a database in your replicated mainframe information. Observe these steps:
- Set up the psql consumer:
- Retrieve the password from secret supervisor:
- Create a brand new database in PostgreSQL:
Configure the serverless MSK cluster
To create a serverless MSK cluster, full the next steps:
- Copy the next JSON and paste it into a brand new file
create-msk-serverless-cluster.json. Change the placeholder strings with values that correspond to your cluster’s subnet and safety group IDs. - Invoke the next AWS CLI command within the folder the place you saved the JSON file within the earlier step:
- Confirm cluster standing by invoking the next AWS CLI command:
- Get the bootstrap dealer deal with by invoking the next AWS CLI command:
- Outline the surroundings variable to retailer the bootstrap servers of the MSK cluster and domestically set up Kafka within the path surroundings variable:
Create a subject on the MSK cluster
To create a Kafka matter, it’s worthwhile to set up the Kafka CLI first. Observe these steps:
- Obtain the binary distribution of Apache Kafka and extract the archive in folder
kafka: - To make use of IAM to authenticate with the MSK cluster, obtain the Amazon MSK Library for IAM and duplicate to the native Kafka library listing as proven within the following code. For full directions, seek advice from Configure shoppers for IAM entry management.
- Within the listing, create a file to configure a Kafka consumer to make use of IAM authentication for the Kafka console producer and shoppers:
- Create the Kafka matter, which you outlined within the connector config:
Configure the MSK Join plugin
Subsequent, create a {custom} plugin out there within the AMI at /decide/exactly/di/packages/sqdata-msk_connect_1.0.1.zip which incorporates the next:
- JDBC Sink Connector from Confluent
- MSK Config supplier
- AWS Mainframe Modernization – Information Repication for IBM z/OS Customized SMT
Observe these steps:
- Invoke the next to add the .zip file to an S3 bucket to which you might have entry:
- Copy the next JSON and paste it into a brand new file
create-custom-plugin.json. Change the placeholder strings with values that correspond to your bucket. - Invoke the next AWS CLI command within the folder the place you saved the JSON file within the earlier step:
- Confirm plugin standing by invoking the next AWS CLI command:
Configure the JDBC Sink Connector
To configure the JDBC Sink Connector, observe these steps:
- Copy the next JSON and paste it into a brand new file
create-connector.json. Change the placeholder strings with applicable values: - Invoke the next AWS CLI command within the folder the place you saved the JSON file within the earlier step:
- Confirm connector standing by invoking the next AWS CLI command:
Arrange Db2 Seize/Writer on Mainframe
To ascertain the Db2 Seize/Writer on the mainframe for capturing adjustments to the DEPT desk, observe these structured steps that construct upon our earlier weblog publish, Unlock Mainframe Information with Exactly Join and Amazon Aurora:
- Put together the supply desk. Earlier than configuring the Seize/Writer, make sure the DEPT supply desk exists in your mainframe Db2 system. The desk definition ought to match the construction outlined at
$SQDATA_VAR_DIR/templates/dept.ddl. If it’s worthwhile to create this desk in your mainframe, use the DDL from this file as a reference to make sure compatibility with the replication course of. - Entry the Interactive System Productiveness Facility (ISPF) interface. Check in to your mainframe system and entry the AWS Mainframe Modernization – Information Repication for IBM z/OS ISPF panels by way of the provided ISPF utility menu. Choose possibility 3 (CDC) to entry the CDC configuration panels, as demonstrated in our earlier weblog publish.
- Add supply tables for seize:
- From the CDC Major Choice Menu, select possibility 2 (Outline Subscriptions).
- Select possibility 1 (Outline Db2 Tables) so as to add supply tables.
- On the (Add DB2 Supply Desk to CAB File panel), enter a wildcard worth (%) or the precise desk identify
DEPTwithin the (Desk Title) discipline. - Press Enter to show the checklist of obtainable tables.
- Kind
Ssubsequent to theDEPTdesk to pick out it for replication, then press Enter to substantiate.
This course of is just like the desk choice course of proven in determine 3 and determine 4 of our earlier publish however now focuses particularly on the DEPT desk construction.
With the completion of each the Db2 Seize/Writer setup on the mainframe and the AWS surroundings configuration (Amazon MSK, Apply Engine, and MSK Join JDBC Sink Connector), you now have a totally practical pipeline able to seize information adjustments from the mainframe and stream them to the MSK matter. Inserts, updates, or deletions to the DEPT desk on the mainframe might be robotically captured and pushed to the MSK matter in close to actual time. From there, the MSK Join JDBC Sink Connector and the {custom} SMT will course of these messages and apply the adjustments to the PostgreSQL database on Amazon RDS, finishing the end-to-end replication stream.
Configure Apply Engine for Amazon MSK integration
Configure the AWS facet parts to obtain information from the mainframe and ahead it to Amazon MSK. Observe these steps to outline and handle a brand new CDC pipeline from DB2 z/OS to Amazon MSK:
- Use the next command to change to the
joinconsumer: - Create the apply engine directories:
- Copy the pattern script from
dept.ddl: - Copy the next content material and paste it in a brand new file
$SQDATA_VAR_DIR/apply/DB2ZTOMSK/scripts/DB2ZTOMSK.sqd. Change the placeholder strings with values that correspond to the DB2z endpoint: - Create the working listing:
- Add the next to
$SQDATA_DAEMON_DIR/cfg/sqdagents.cfg: - After the previous code is added to the
sqdagents.cfgpart, reload for the adjustments to take impact: - Validate the apply engine job script through the use of the SQData parse command to create the compiled file anticipated by the SQData engine:
The next is an instance of the output that you simply get if you invoke the command efficiently:
- Copy the next content material and paste it in a brand new file
/var/exactly/di/sqdata_logs/apply/DB2ZTOMSK/sqdata_kafka_producer.conf. Change the placeholder strings with values that correspond to your bootstrap server and AWS Area. - Begin the apply engine utilizing the controller daemon through the use of the next command:
- Monitor the apply engine by way of the controller daemon through the use of the next command:
The next is an instance of the output that you simply get if you invoke the command efficiently:
Logs can be discovered at
/var/exactly/di/sqdata_logs/apply/DB2ZTOMSK.
Confirm information within the MSK matter
Invoke the Kafka CLI command to confirm the JSON information within the MSK matter:
Confirm information within the PostgreSQL database
Invoke the next command to confirm the info within the PostgreSQL database:
With these steps accomplished, you’ve efficiently arrange end-to-end information replication from DB2z to RDS for PostgreSQL, utilizing AWS Mainframe Modernization – Information Replication for IBM z/OS AMI, Amazon MSK, MSK Join, and the Confluent JDBC Sink Connector.
Cleanup
If you’re completed testing this resolution, you may clear up the assets to keep away from incurring extra expenses. Observe these steps in sequence to make sure correct cleanup.
Step 1: Delete the MSK Join parts
Observe these steps:
- Record current connectors:
- Delete the sink connector:
- Record {custom} plugins:
- Delete the {custom} plugin:
Step 2: Delete the MSK cluster
Observe these steps:
- Record MSK clusters:
- Delete the MSK serverless cluster:
Step 3: Delete the Aurora assets
Observe these steps:
- Delete the Aurora DB occasion:
- Delete the Aurora DB cluster:
Conclusion
By capturing modified information from DB2z and streaming it to AWS targets, organizations can modernize their legacy mainframe information shops, enabling operational insights and AI initiatives. Companies can use this resolution to make the most of cloud-based functions with mainframe information to offer scalability, cost-efficiency, and enhanced efficiency.
The combination of AWS Mainframe Modernization – Information Replication for IBM z/OS AMI with Amazon MSK and RDS for PostgreSQL offers an enhanced framework for real-time information synchronization that maintains information integrity. This structure could be prolonged to assist extra mainframe information sources reminiscent of VSAM and IMS, in addition to different AWS targets. Organizations can then tailor their information integration technique to particular enterprise wants. Information consistency and latency challenges could be successfully managed by way of AWS and Exactly’s monitoring capabilities. By adopting this structure, organizations hold their mainframe information regularly out there for analytics, machine studying (ML), and different superior functions.Streaming mainframe information to AWS in close to actual time represents a strategic step towards modernizing legacy methods whereas unlocking new alternatives for innovation, with information transfers occurring in subseconds. With Exactly and AWS, organizations can successfully navigate their modernization journey and preserve their aggressive benefit.
Study extra about AWS Mainframe Modernization – Information Replication for IBM z/OS AMI within the Exactly documentation. AWS Mainframe Modernization Information Replication is offered for buy in AWS Market. For extra details about the answer or to see an illustration, contact Exactly.