
: Self-Enhancing LLMs by way of Evolving Contexts, Not Advantageous-Tuning")
{kind=link}
TL;DR: A staff of researchers from Stanford College, SambaNova Techniques and UC Berkeley introduce ACE framework that improves LLM efficiency by modifying and rising the enter context as an alternative of updating mannequin weights. Context is handled as a dwelling “playbook” maintained by three roles—Generator, Reflector, Curator—with small delta gadgets merged incrementally to keep away from brevity bias and context collapse. Reported positive factors: +10.6% on AppWorld agent duties, +8.6% on finance reasoning, and ~86.9% common latency discount vs robust context-adaptation baselines. On the AppWorld leaderboard snapshot (Sept 20, 2025), ReAct+ACE (59.4%) ≈ IBM CUGA (60.3%, GPT-4.1) whereas utilizing DeepSeek-V3.1.
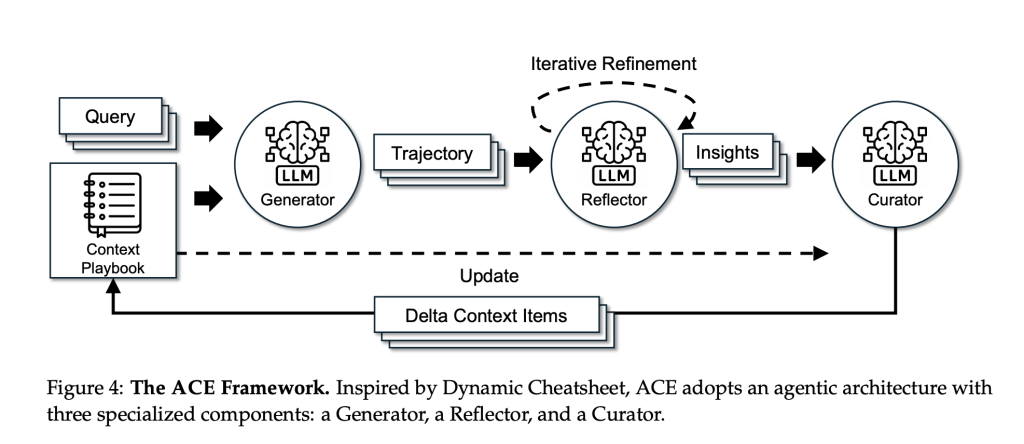
What ACE modifications?
ACE positions “context engineering” as a first-class various to parameter updates. As a substitute of compressing directions into brief prompts, ACE accumulates and organizes domain-specific ways over time, arguing that greater context density improves agentic duties the place instruments, multi-turn state, and failure modes matter.
Methodology: Generator → Reflector → Curator
- Generator executes duties and produces trajectories (reasoning/device calls), exposing useful vs dangerous strikes.
- Reflector distills concrete classes from these traces.
- Curator converts classes into typed delta gadgets (with useful/dangerous counters) and merges them deterministically, with de-duplication and pruning to maintain the playbook focused.
Two design decisions—incremental delta updates and grow-and-refine—protect helpful historical past and stop “context collapse” from monolithic rewrites. To isolate context results, the analysis staff fixes the identical base LLM (non-thinking DeepSeek-V3.1) throughout all three roles.
Benchmarks
AppWorld (brokers): Constructed on the official ReAct baseline, ReAct+ACE outperforms robust baselines (ICL, GEPA, Dynamic Cheatsheet), with +10.6% common over chosen baselines and ~+7.6% over Dynamic Cheatsheet in on-line adaptation. On the Sept 20, 2025 leaderboard, ReAct+ACE 59.4% vs IBM CUGA 60.3% (GPT-4.1); ACE surpasses CUGA on the tougher test-challenge cut up, whereas utilizing a smaller open-source base mannequin.
Finance (XBRL): On FiNER token tagging and XBRL Formulation numerical reasoning, ACE studies +8.6% common over baselines with ground-truth labels for offline adaptation; it additionally works with execution-only suggestions, although high quality of indicators issues.
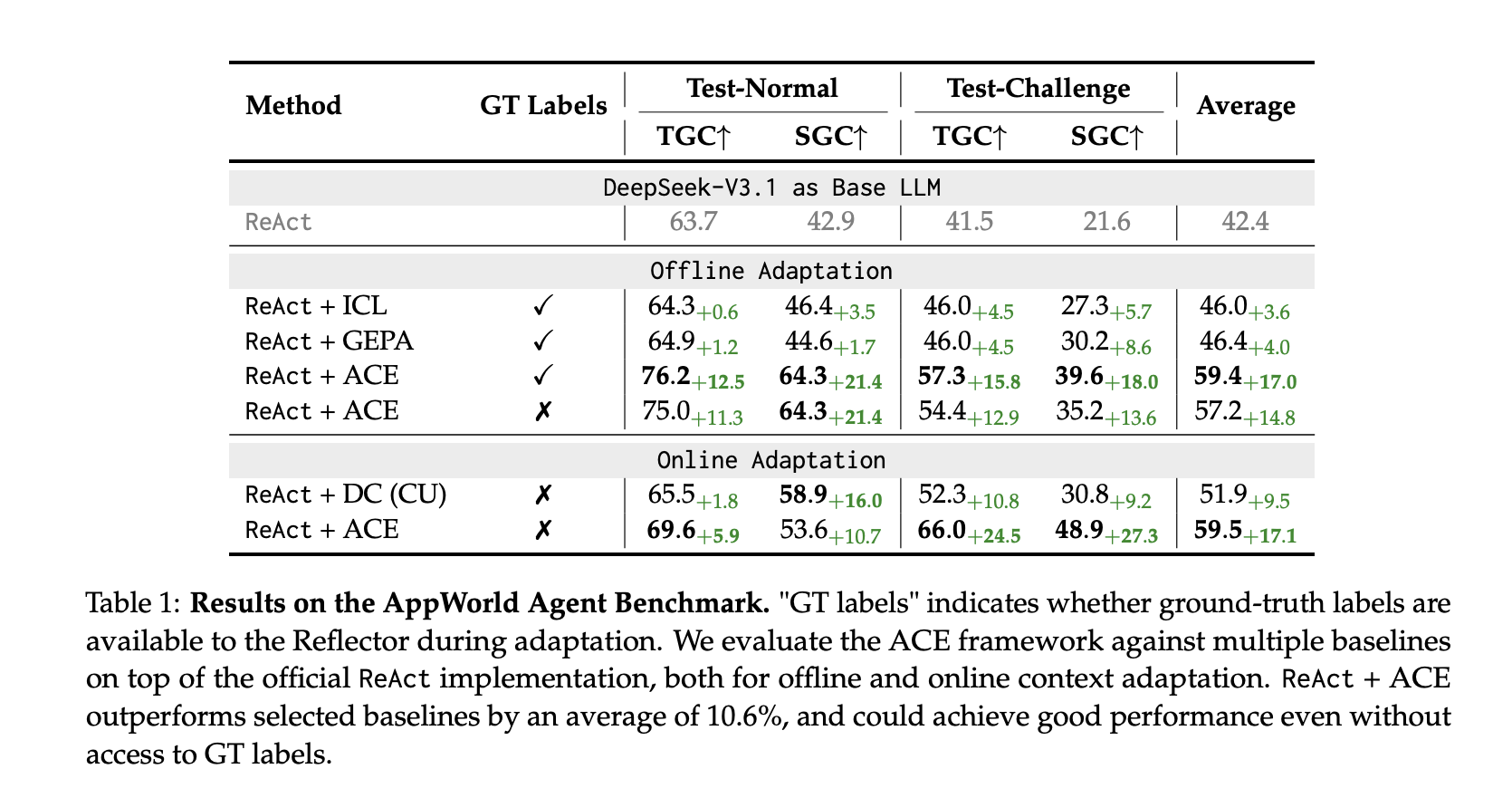
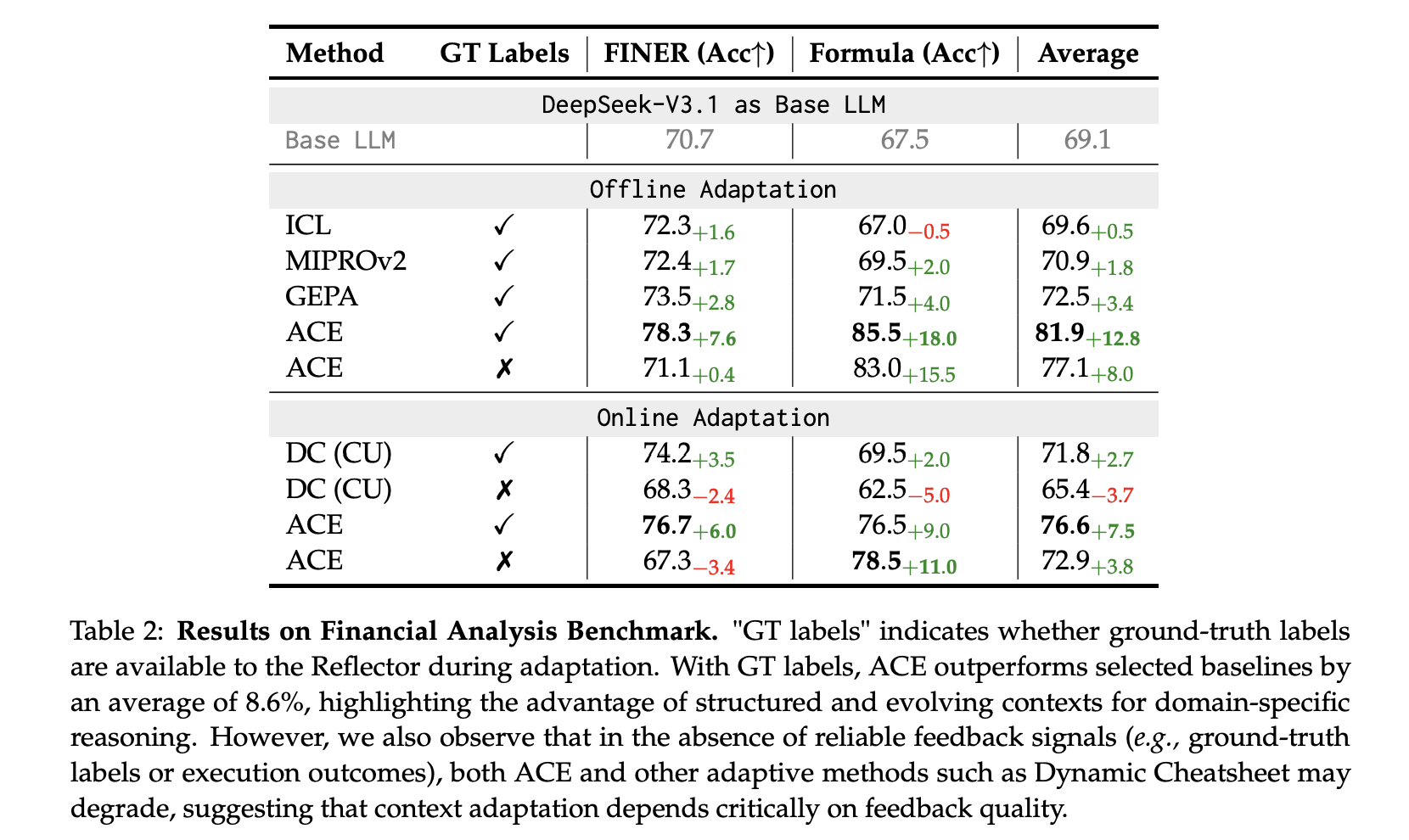
Value and latency
ACE’s non-LLM merges plus localized updates cut back adaptation overhead considerably:
- Offline (AppWorld): −82.3% latency and −75.1% rollouts vs GEPA.
- On-line (FiNER): −91.5% latency and −83.6% token price vs Dynamic Cheatsheet.
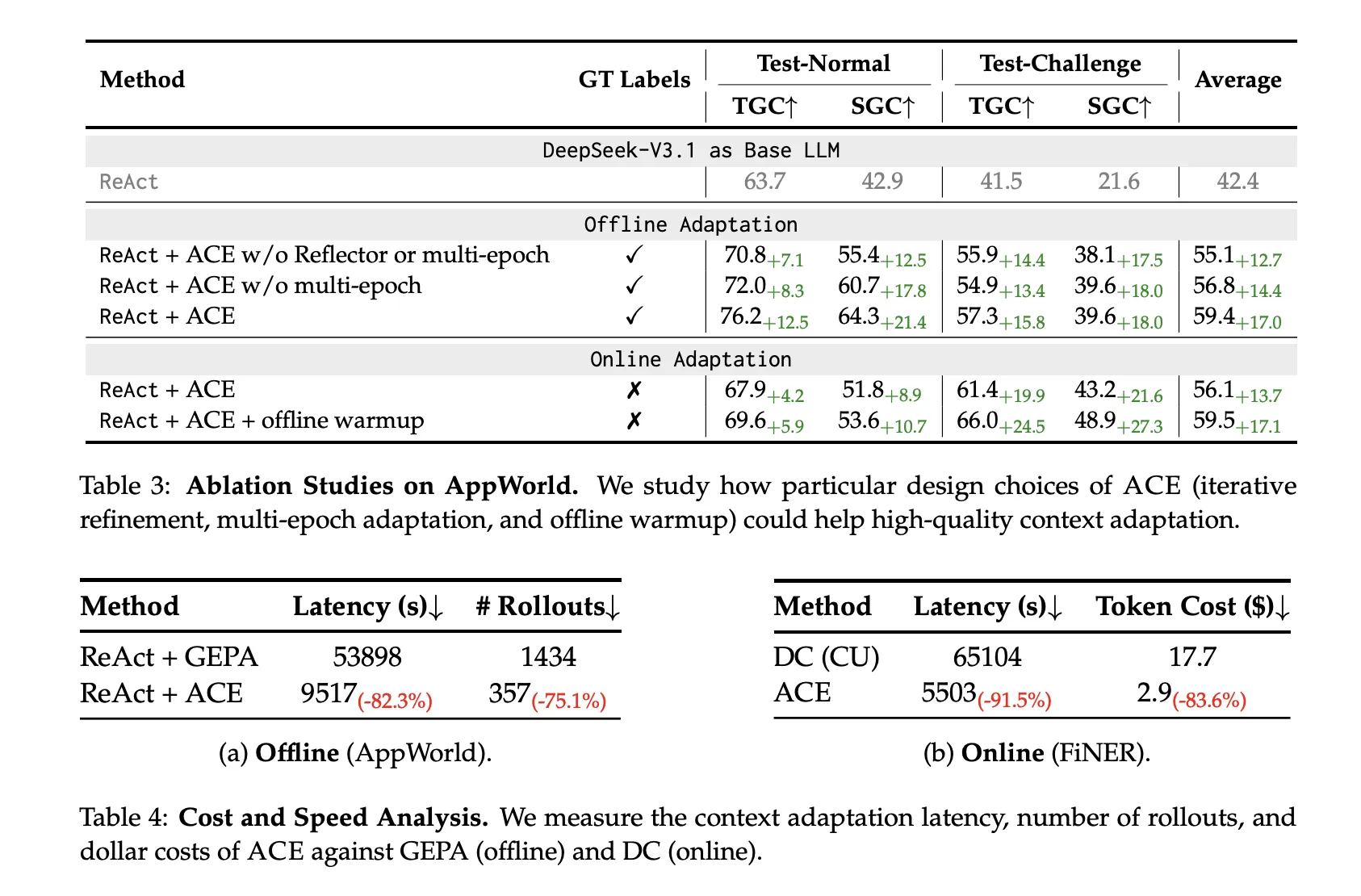
Key Takeaways
- ACE = context-first adaptation: Improves LLMs by incrementally modifying an evolving “playbook” (delta gadgets) curated by Generator→Reflector→Curator, utilizing the similar base LLM (non-thinking DeepSeek-V3.1) to isolate context results and keep away from collapse from monolithic rewrites.
- Measured positive factors: ReAct+ACE studies +10.6% over robust baselines on AppWorld and achieves 59.4% vs IBM CUGA 60.3% (GPT-4.1) on the Sept 20, 2025 leaderboard snapshot; finance benchmarks (FiNER + XBRL Formulation) present +8.6% common over baselines.
- Decrease overhead than reflective-rewrite baselines: ACE reduces adaptation latency by ~82–92% and rollouts/token price by ~75–84%, contrasting with Dynamic Cheatsheet’s persistent reminiscence and GEPA’s Pareto immediate evolution approaches.
Conclusion
ACE positions context engineering as a first-class various to weight updates: keep a persistent, curated playbook that accumulates task-specific ways, yielding measurable positive factors on AppWorld and finance reasoning whereas slicing adaptation latency and token rollouts versus reflective-rewrite baselines. The strategy is sensible—deterministic merges, delta gadgets, and long-context–conscious serving—and its limits are clear: outcomes monitor suggestions high quality and process complexity. If adopted, agent stacks might “self-tune” primarily by way of evolving context slightly than new checkpoints.
Take a look at the PAPER right here. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our E-newsletter. Wait! are you on telegram? now you possibly can be a part of us on telegram as effectively.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.