

Through the years, organizations have invested in constructing purpose-built cloud-based knowledge warehouses which might be siloed from each other. One of many main challenges these organizations encounter right this moment is enabling cross-organization discovery and entry to knowledge throughout these siloed knowledge warehouses constructed utilizing completely different know-how stacks. The knowledge mesh sample addresses these points, based in 4 rules: domain-oriented decentralized knowledge possession and structure, treating knowledge as a product, offering self-serve knowledge infrastructure as a platform, and implementing federated governance. The information mesh sample helps organizations mimic their organizational construction into knowledge domains and makes it attainable to share the information throughout the group and past to enhance their enterprise fashions.
In 2019, Volkswagen AG and Amazon Net Companies (AWS) began their collaboration to co-develop the Digital Manufacturing Platform (DPP), with the aim of enhancing manufacturing and logistics effectivity by 30% whereas lowering manufacturing prices by the identical margin. The DPP was developed to streamline entry to knowledge from store flooring gadgets and manufacturing methods by dealing with integrations and offering a spread of standardized interfaces. Nonetheless, as purposes and use instances advanced on the platform, a big problem emerged: the power to share knowledge throughout purposes saved in remoted knowledge warehouses (inside Amazon Redshift in remoted AWS accounts designated for particular use instances), with out the necessity to consolidate knowledge right into a central knowledge warehouse. One other problem was discovering all of the obtainable knowledge saved throughout a number of knowledge warehouses and facilitating a workflow to request entry to knowledge throughout enterprise domains inside every plant. The widespread technique used was largely handbook, counting on emails and normal communication (by way of tickets and emails). The handbook method not solely elevated the overhead but in addition different from one use case to a different by way of knowledge governance.
On this publish, we introduce Amazon DataZone and discover how Volkswagen used Amazon DataZone to construct their knowledge mesh, sort out the challenges encountered, and break the information silos. A key facet of the answer was enabling knowledge suppliers to robotically publish their knowledge merchandise to Amazon DataZone, serving as a central knowledge mesh for enhanced knowledge discoverability. Moreover, we offer code to information you thru the deployment and implementation course of.
Introduction to Amazon DataZone
Amazon DataZone is a knowledge administration service that makes it quicker and easy to catalog, uncover, share, and govern knowledge saved throughout AWS, on-premises, and third-party sources. Key options of Amazon DataZone embody the enterprise knowledge catalog, with which customers can seek for printed knowledge, request entry, and begin engaged on knowledge in days as an alternative of weeks. As well as, the service facilitates collaboration throughout groups and helps them handle and monitor knowledge belongings throughout completely different organizational models. The service additionally consists of the Amazon DataZone portal, which provides a personalised analytics expertise for knowledge belongings by way of a web-based software or API. Lastly, Amazon DataZone provides ruled knowledge sharing, which makes certain the appropriate knowledge is accessed by the appropriate consumer for the appropriate objective with a ruled workflow.
Resolution overview
The next structure diagram represents a high-level design that’s constructed on high of the information mesh sample. It separates supply methods, knowledge area producers (knowledge publishers), knowledge area subscribers (knowledge shoppers), and central governance to spotlight the important thing points. This knowledge mesh structure is specifically tailor-made for cross-AWS account utilization. The target of this method is to create a basis for constructing knowledge governance on a scale, supporting the goals of knowledge producers and shoppers with sturdy and constant governance.
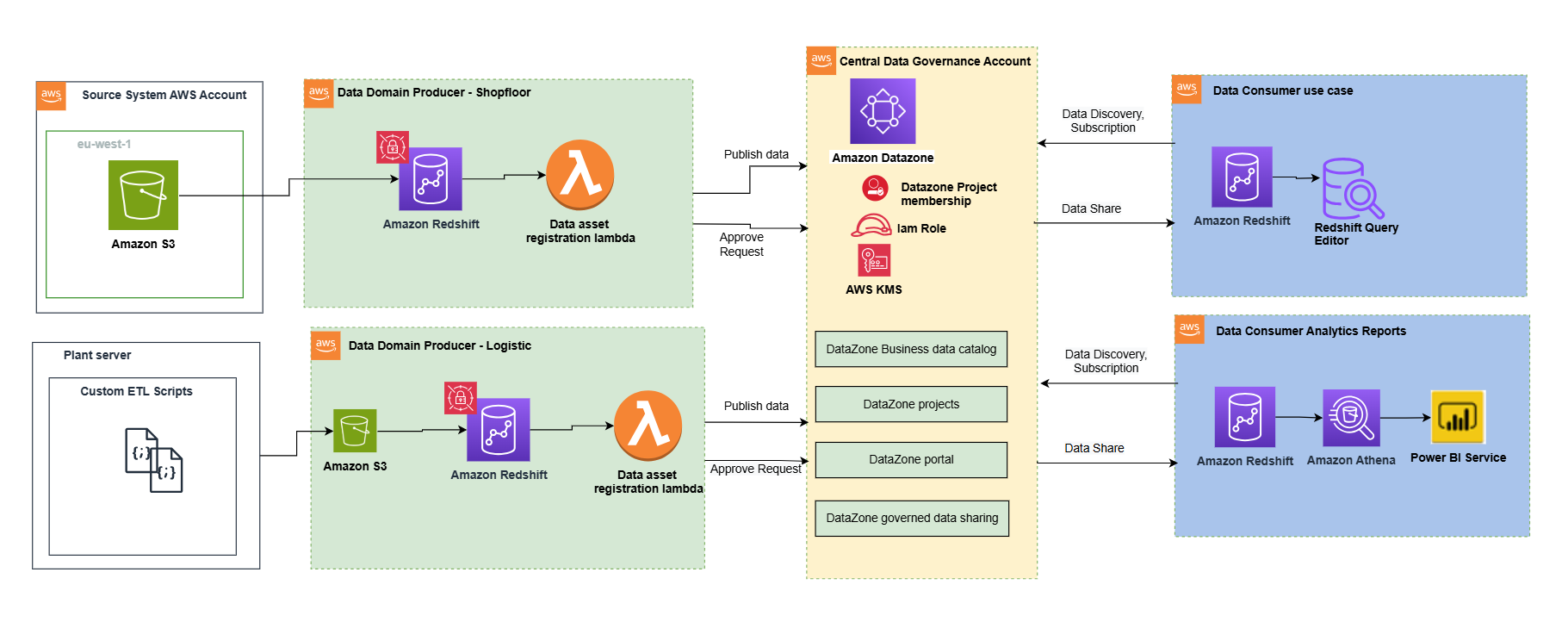
This structure permits for the mixing of a number of knowledge warehouses right into a centralized governance account that shops all of the metadata from every setting.
An information area producer makes use of Amazon Redshift as their analytical knowledge warehouse to retailer, course of, and handle structured and semi-structured knowledge. The information area producers load knowledge into their respective Amazon Redshift clusters by way of extract, rework, and cargo (ETL) pipelines they handle, personal, and function. The producers preserve management over their knowledge by way of Amazon Redshift safety features, together with column-level entry controls and dynamic knowledge masking, supporting knowledge governance on the supply. An information area producer makes use of Amazon Redshift ETL and Amazon Redshift Spectrum to course of and rework uncooked knowledge into consumable knowledge merchandise. The information merchandise might be Amazon Redshift tables, views, or materialized views.
Knowledge area producers expose datasets to the remainder of the group by registering them to Amazon DataZone service, which acts as a central knowledge catalog. They’ll select what knowledge belongings to share, for a way lengthy, and the way shoppers can work together with these. They’re additionally chargeable for sustaining the information and ensuring it’s correct and present.
The information belongings from the producers are then printed utilizing the information supply run to Amazon DataZone within the central governance account. This course of populates the technical metadata into the enterprise knowledge catalog for every knowledge asset. The enterprise metadata could be added by enterprise customers (knowledge analysts) to supply enterprise context, tags, and knowledge classification for the datasets. This method offers the required options to permit producers to create catalog entries with Amazon Redshift from all their knowledge warehouses in-built with Redshift clusters. As well as, the central knowledge governance account is used to share datasets securely between producers and shoppers. It’s essential to notice that sharing is completed by way of metadata linking alone. No knowledge (besides logs) exists within the governance account. The information isn’t copied to the central account; only a reference to the information is used, in order that the information possession stays with the producer.
Amazon DataZone offers a streamlined technique to seek for knowledge. The Amazon DataZone knowledge portal offers a personalised view for customers to find and search knowledge belongings. An Amazon DataZone consumer (shopper) with permissions to entry the information portal can seek for belongings and submit requests for subscription of knowledge belongings utilizing a web-based software. An approver can then approve or reject the subscription request.
When a knowledge area shopper has entry to an asset within the catalog, they will eat it (question and analyze) utilizing the Amazon Redshift question editor. Every shopper runs their very own workload primarily based on their use case. On this method, the crew can select the instruments for the job to carry out analytics and machine studying actions in its AWS shopper setting.
Publishing and registering knowledge belongings to Amazon DataZone
To publish a knowledge asset from the producer account, every asset have to be registered in Amazon DataZone for shopper subscription. For extra data, discuss with Create and run an Amazon DataZone knowledge supply for Amazon Redshift. Within the absence of an automatic registration course of, required duties have to be accomplished manually for every knowledge asset.
Utilizing the automated registration workflow, the handbook steps could be automated for the Amazon Redshift knowledge asset (Redshift desk or view) that must be printed in an Amazon DataZone area or when there’s a schema change in an already printed knowledge asset.
The next structure diagram represents how knowledge belongings from Amazon Redshift knowledge warehouses have been robotically printed to the information mesh created with Amazon DataZone.
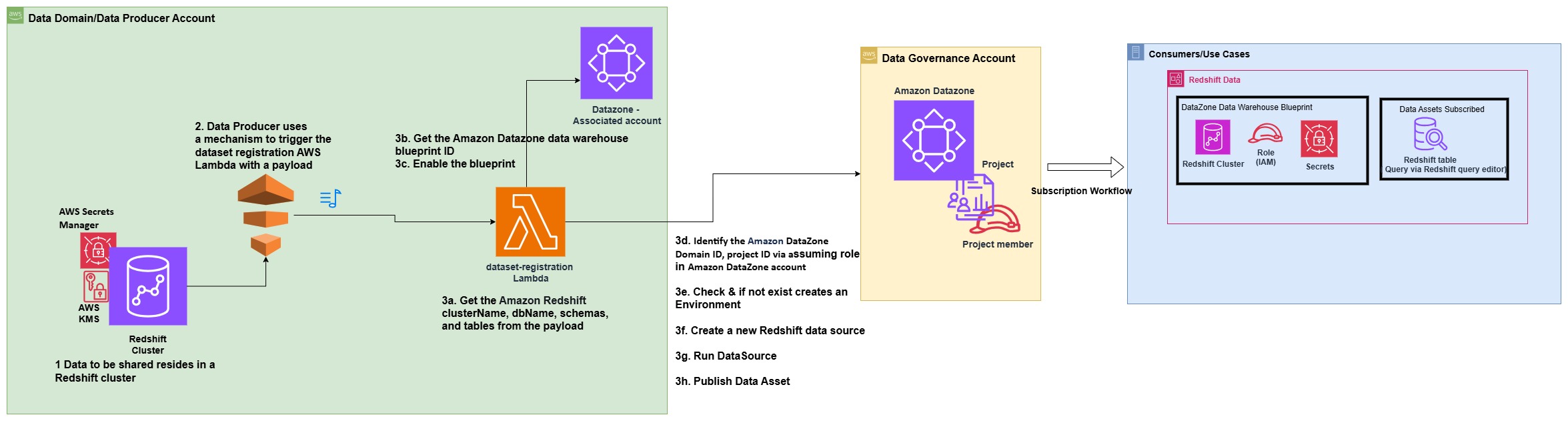
The method consists of the next steps:
- Within the producer account (Account B), the information to be shared resides in a Redshift cluster.
- The producer account (Account B) makes use of a mechanism to set off the dataset registration AWS Lambda operate with a selected payload containing the knowledge and title of the database, schema, desk, or view that has a change in metadata.
- The Lambda operate performs the steps to robotically register and publish the dataset in Amazon DataZone:
- Get the Amazon Redshift clusterName, dbName, schemas, and tables from the JSON payload, which is used because the occasion to set off the Lambda operate.
- Get the Amazon DataZone knowledge warehouse blueprint ID.
- Allow the blueprint within the knowledge producer account.
- Determine the Amazon DataZone Area ID and challenge ID for the producer through assuming position in Amazon DataZone account (Account A).
- Verify if an setting already exists within the challenge. If not, create an setting.
- Create a brand new Redshift knowledge supply by offering the proper Redshift database data within the newly created setting.
- Provoke a knowledge supply run request within the knowledge supply to make the Redshift tables or views obtainable in Amazon DataZone.
- Publish the tables or views within the Amazon DataZone catalog.
Conditions
The next conditions are required earlier than beginning:
- Two AWS accounts to implement the answer have been described on this publish. Nonetheless, it’s also possible to use Amazon DataZone to publish knowledge inside a single account or throughout a number of accounts.
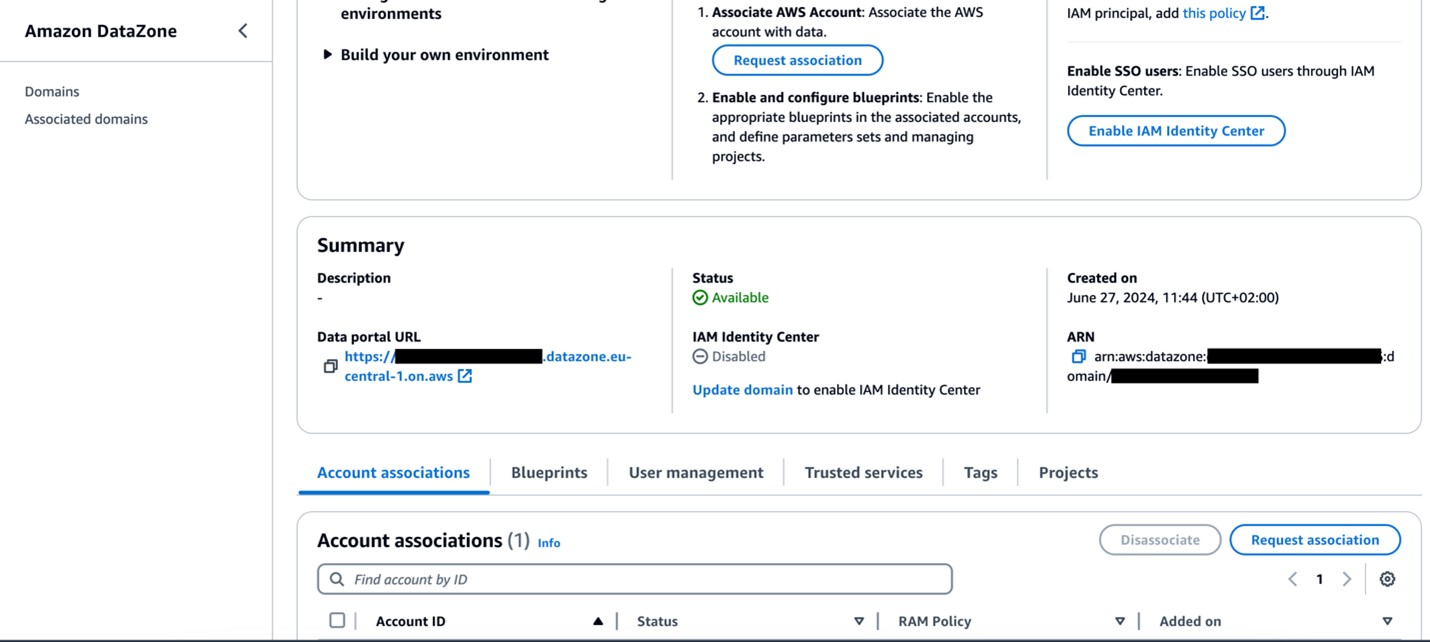
- Amazon DataZone account (Account A) – That is the central knowledge governance account, which could have the Amazon DataZone area and challenge.
- Knowledge area producer account (Account B) – This account acts as the information area producer. It has been added as an related account to Account A.
Conditions in knowledge area producer account (Account B)
As a part of this publish, we wish to publish belongings and subscribe to belongings from a Redshift cluster that already exists. Full the next prerequisite steps to arrange Account B:
- Arrange the Redshift cluster, together with database, schema, tables, and views (non-compulsory). The node sort have to be from the RA3 household. For extra data, see Amazon Redshift provisioned clusters.
Create a superuser in Amazon Redshift for Amazon DataZone. For the Redshift cluster, the database consumer you present in AWS Secrets and techniques Supervisor will need to have superuser permissions. For reference please see the notice part on this QuickStart information with pattern Amazon Redshift knowledge

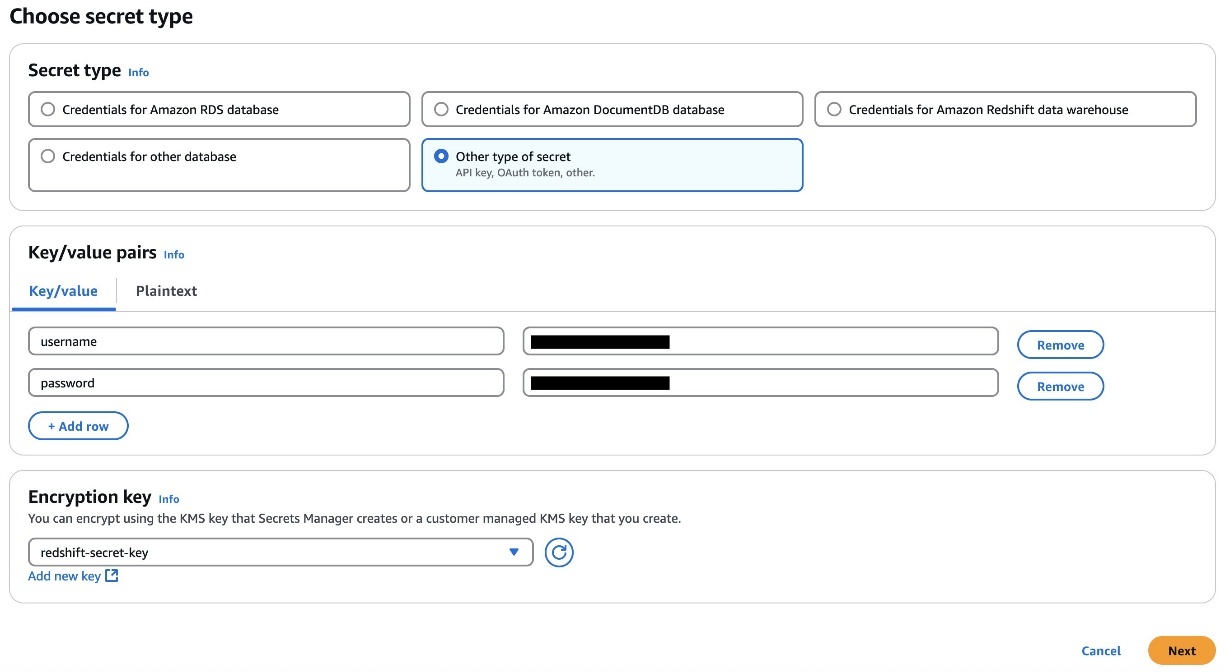
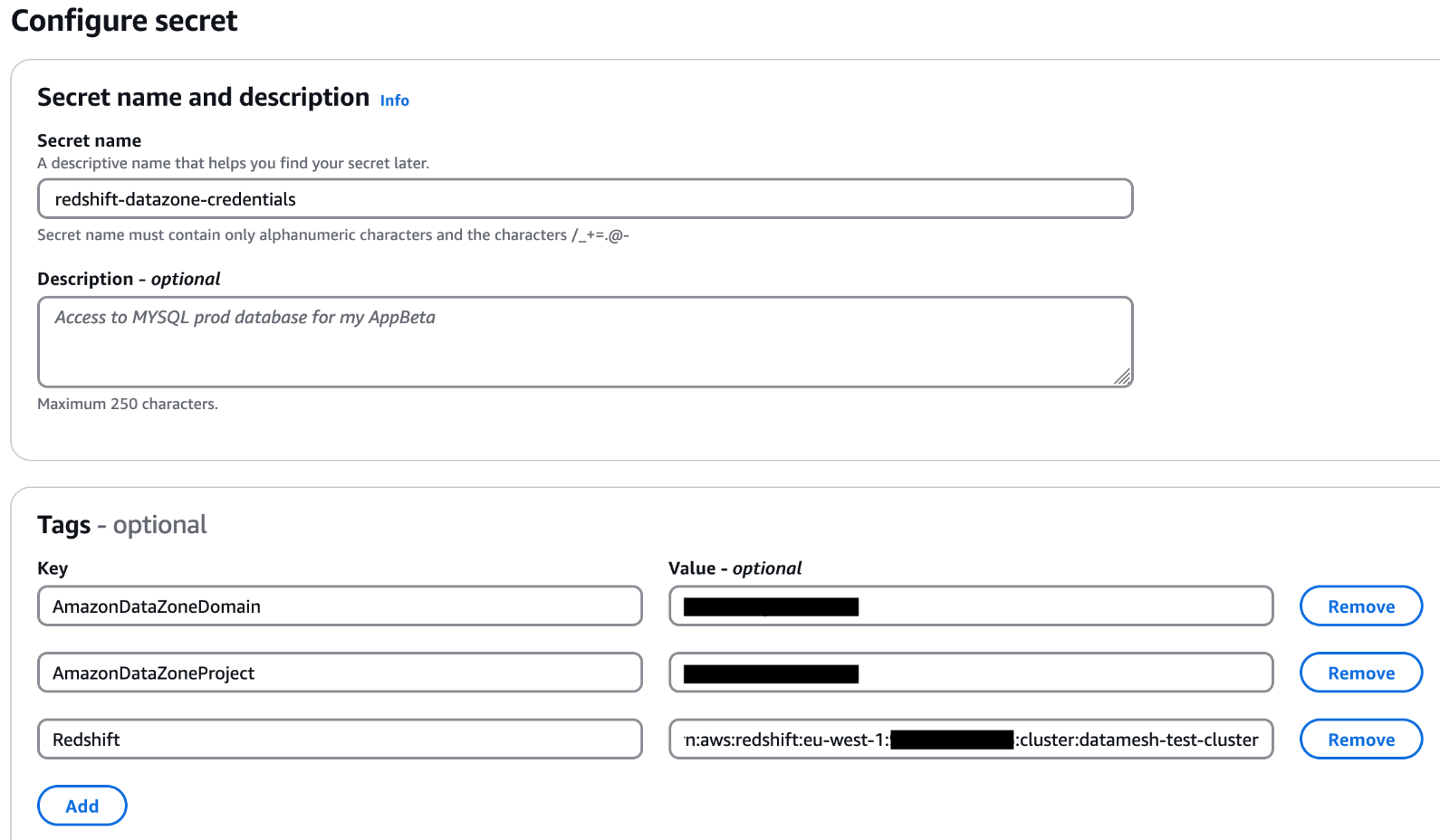
- Retailer the consumer’s credentials in Secrets and techniques Supervisor. Choose the credential sort, enter the credential values, and select the AWS Key Administration Service (AWS KMS) key with which to encrypt the key.

- Add the tags to the Secret Supervisor secret to permit Amazon DataZone to seek out this secret and restrict the entry to a specific Amazon DataZone area and Amazon DataZone challenge. The Redshift cluster Amazon Useful resource Title (ARN) have to be added as a tag so it may be utilized by Amazon Redshift as a legitimate credential. For reference please see the notice part on this QuickStart information with pattern Amazon Redshift knowledge

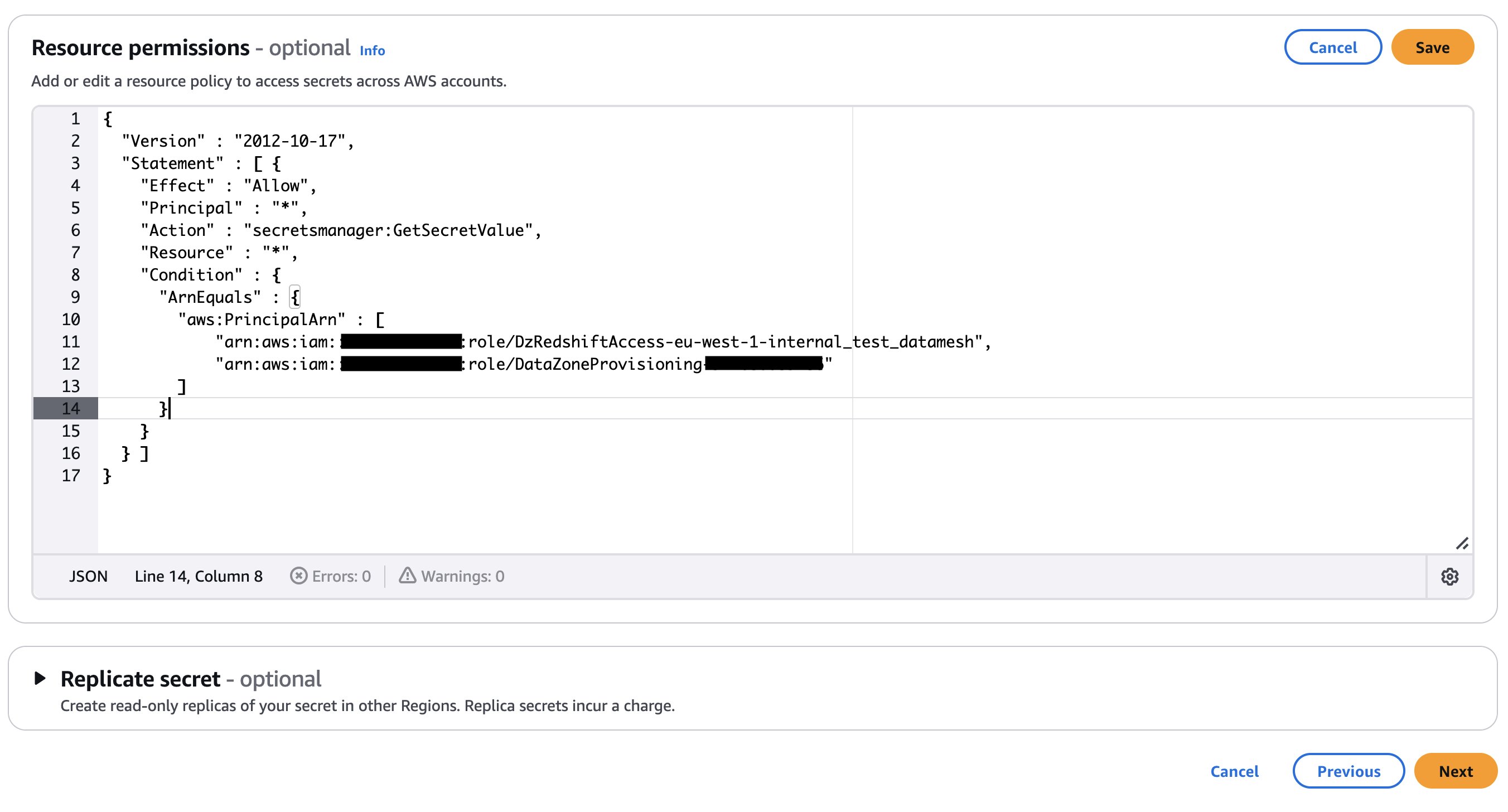
- Add an Amazon DataZone provisioning IAM position and Amazon Redshift handle entry IAM position within the secret’s useful resource coverage. The AWS Identification and Entry Administration (IAM) roles are created as a part of the AWS Cloud Growth Equipment (AWS CDK) deployment (mentioned later on this publish). The next code exhibits an instance of the Secrets and techniques Supervisor secret’s useful resource coverage. Retailer the key ARN in an AWS Methods Supervisor parameter.
 In case your secret is encrypted with a customized KMS key, append the important thing coverage with the next assertion and add a tag to the important thing:
In case your secret is encrypted with a customized KMS key, append the important thing coverage with the next assertion and add a tag to the important thing: AmazonDatazoneEnvironment = All. You possibly can skip this step for those who’re utilizing an AWS managed KMS key. - Place a mechanism to generate the next payload to set off the dataset registration Lambda operate. The payload should comprise the related Redshift database, schema, and desk or view that you simply wish to publish within the Amazon DataZone area. The next instance code assumes you could have three databases in your Redshift cluster and inside these databases you could have completely different schemas, tables, and views. It is best to regulate the payload primarily based in your use case.
 In case your secret is encrypted with a customized KMS key, append the important thing coverage with the next assertion and add a tag to the important thing:
In case your secret is encrypted with a customized KMS key, append the important thing coverage with the next assertion and add a tag to the important thing: Conditions in Amazon DataZone account (Account A)
Full the next steps to arrange your Amazon DataZone account (Account A):
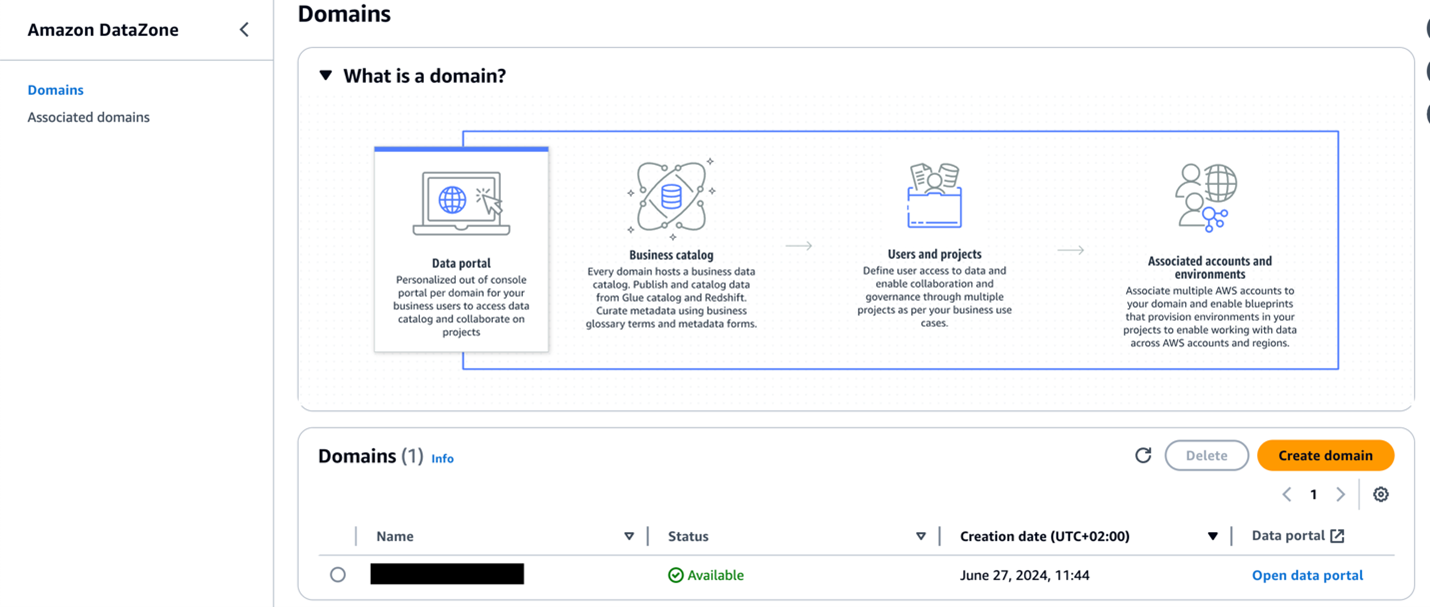
- Sign up to Account A and be sure you have already deployed an Amazon DataZone area and a challenge inside that area. Check with Create Amazon DataZone domains for directions to create a site.
- In case your Amazon DataZone area is encrypted with a KMS key, add the information area account (Account B) to the KMS key coverage with the next actions:
- Create an IAM position that’s assumable by Account B and ensure the position has a following coverage connected and is a member (as contributor) of your Amazon DataZone challenge. For this publish, we name the position
dz-assumable-env-dataset-registration-role. By including this position, you’ll be able to efficiently run the registration Lambda operate.- Within the following coverage, present the AWS Area and account ID comparable to the place your Amazon DataZone area is created, and the KMS key ARN used to encrypt the area:
- Add Account B within the belief relationship of this position with the next belief relationship:
- Add the position as a member of the Amazon DataZone challenge by which you wish to register your knowledge sources. For extra data, see Add members to a challenge.
Extra instruments
The next instruments are wanted to deploy the answer utilizing the AWS CDK:
Deploy the answer
After you full the conditions, use the AWS CDK stack supplied on the GitHub repo to deploy the answer for automated registration of knowledge belongings into the Amazon DataZone area. Full the next steps:
- Clone the repository from GitHub to your most popular built-in improvement setting (IDE) utilizing the next instructions:
- On the base of the repository folder, run the next instructions to construct and deploy sources to AWS:
- Sign up to Account B (the information area producer account) utilizing the AWS CLI along with your profile title.
- Be sure you have configured the Area in your credential’s configuration file.
- Bootstrap the AWS CDK setting with the next instructions on the base of the repository folder. Present the profile title of your deployment account (Account B). Bootstrapping is a one-time exercise and isn’t wanted in case your AWS account is already bootstrapped.
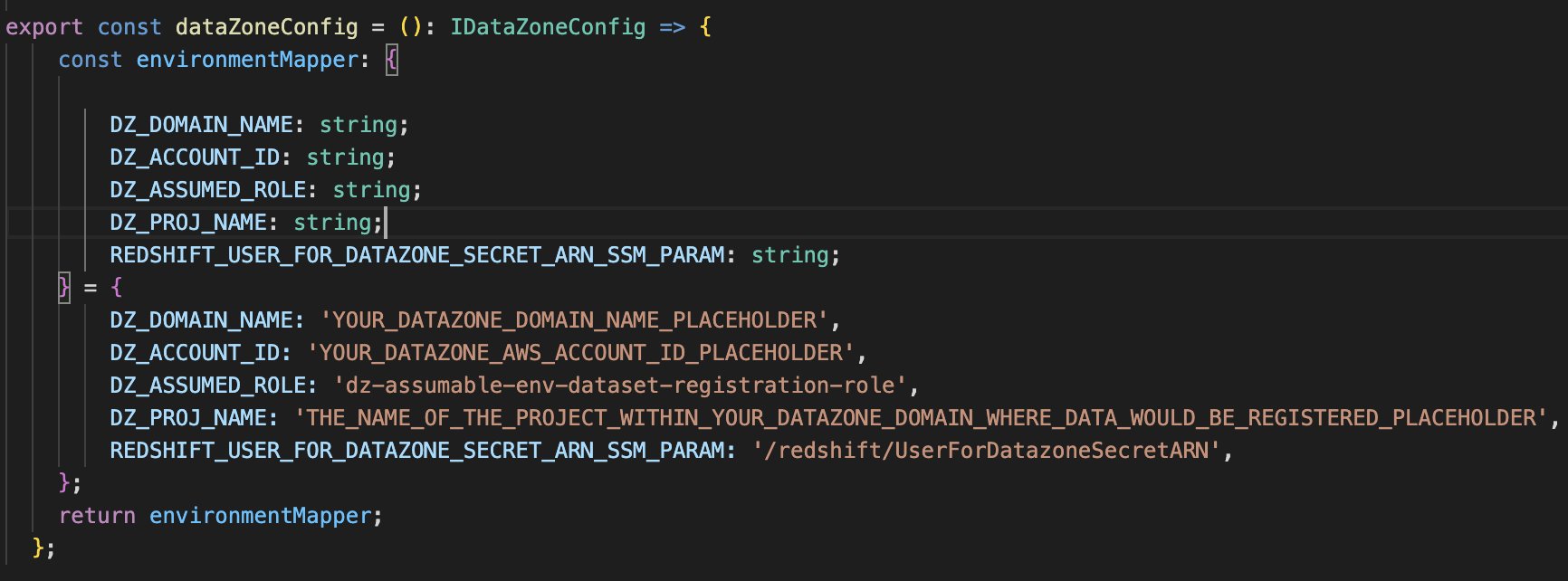
- Substitute the placeholder parameters (marked with the suffix
_PLACEHOLDER) within the fileconfig/DataZoneConfig.ts:- Amazon DataZone area and challenge title of your Amazon DataZone occasion. Make sure that all names are in lowercase.
- The AWS account ID of the Amazon DataZone account (Account A).
- The assumable IAM position from the conditions.
- The AWS Methods Supervisor parameter title containing the Secrets and techniques Supervisor secret ARN of the Amazon Redshift credentials.

- Use the next command within the base folder to deploy the AWS CDK resolution. Throughout deployment, enter
yif you wish to deploy the modifications for some stacks if you see the immediateDo you want to deploy these modifications (y/n)? - After the deployment is full, check in to Account B and open the AWS CloudFormation console to confirm that the infrastructure was deployed.

Check automated knowledge registration to Amazon DataZone
Full the next steps to check the answer:
- Sign up to Account B (producer account).
- On the Lambda console, open the
datazone-redshift-dataset-registrationoperate. - Below TEST EVENTS, select Create new take a look at occasion.
- For Occasion title, enter
Redshift, and for Occasion JSON, enter the next JSON construction (change the cluster, schema, database, and desk names in response to your setting): - Select Save.
- Select Invoke.
- Open the Amazon DataZone console in Account A the place you deployed the sources.
- Select Domains within the navigation pane, then open your area.

- On the area particulars web page, find the Amazon DataZone knowledge portal URL within the Abstract part. Select the hyperlink to the information portal.
For extra particulars about accessing Amazon DataZone, discuss with How can I entry Amazon DataZone?

- Within the knowledge portal, open your challenge and select the Knowledge tab.

- Within the navigation pane, select Knowledge sources and discover the newly created knowledge supply for Amazon Redshift.

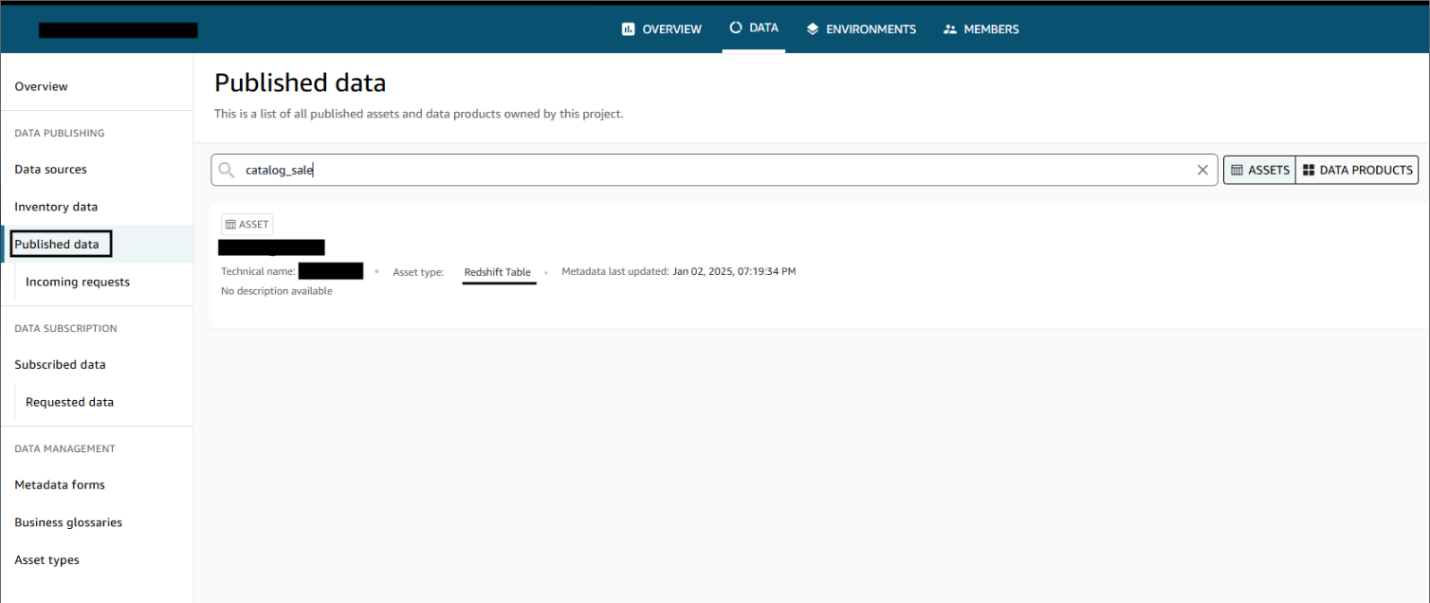
- Confirm that the information supply has been efficiently printed.


{kind=link}
After the information sources are printed, customers can uncover the printed knowledge and submit a subscription request. The information producer can approve or reject requests. Upon approval, customers can eat the information by querying the information within the Amazon Redshift question editor. The next screenshot illustrates knowledge discovery within the Amazon DataZone knowledge portal.

Clear up
Full the next steps to wash up the sources deployed by way of the AWS CDK:
- Sign up to Account B, go to the Amazon DataZone area portal, and test there is no such thing as a subscription to your printed knowledge asset. If there’s a subscription, both ask the subscriber to unsubscribe or revoke the subscription request.
- Delete the printed knowledge belongings that had been created within the Amazon DataZone challenge by the dataset registration Lambda operate.
- Delete the remaining sources created utilizing the next command within the base folder:
Conclusion
Amazon DataZone provides a seamless integration with AWS providers, offering a robust resolution for organizations like Volkswagen to interrupt down their knowledge silos and implement efficient knowledge mesh architectures by way of an easy implementation highlighted on this publish. Through the use of Amazon DataZone, Volkswagen addressed its speedy knowledge sharing hurdles and laid the groundwork for a extra agile, data-driven future in automotive manufacturing. The automated knowledge publishing from numerous warehouses, coupled with standardized governance workflows, has considerably lowered the handbook overhead that when slowed down Volkswagen’s knowledge engineering groups. Now, as an alternative of navigating a labyrinth of emails, tickets, and communication, Volkswagen’s knowledge engineers and knowledge scientists can shortly uncover and entry the information they want, all whereas sustaining their safety and compliance requirements.
Through the use of Amazon DataZone, organizations can carry their remoted knowledge collectively in ways in which make it less complicated for groups to collaborate whereas sustaining safety and compliance at scale. This method not solely addresses present knowledge governance challenges but in addition creates a extremely scalable basis for future data-driven improvements. For steerage on establishing your group’s knowledge mesh with Amazon DataZone, contact your AWS crew right this moment.