

{kind=link}
Introduction
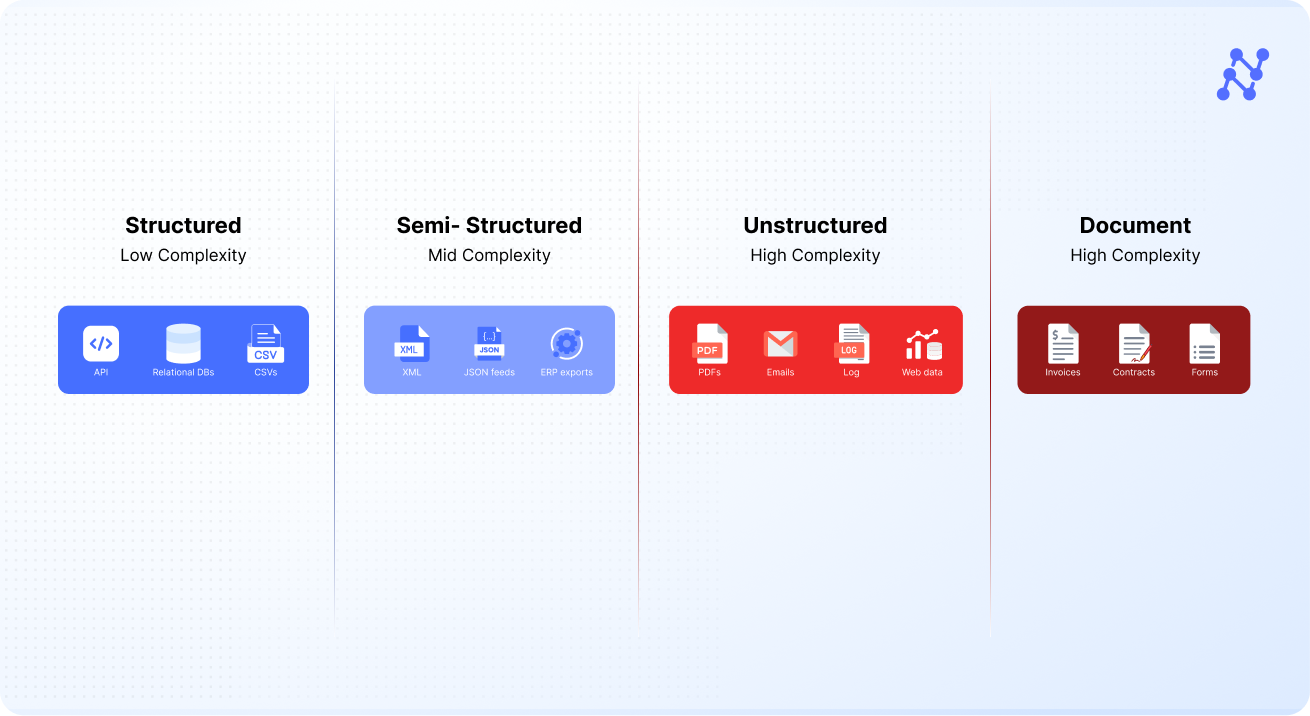
80–90% of enterprise knowledge lives in unstructured paperwork — contracts, claims, medical data, and emails. But most organizations nonetheless depend on brittle templates or guide keying to make sense of it. Knowledge sits on a spectrum — from clear, tabular codecs to messy, free-form content material. Paperwork characterize probably the most advanced and high-value finish of this continuum.
Now image this: a 60-page provider contract lands in procurement’s inbox. Historically, analysts may spend two days combing via indemnity clauses, renewal phrases, and non-standard provisions earlier than routing obligations right into a contract lifecycle administration (CLM) system. With an Clever Doc Processing (IDP) pipeline in place, the contract is parsed, key clauses are extracted, deviations are flagged, and obligations are pushed into the CLM system in beneath an hour. What was as soon as guide, error-prone, and sluggish turns into close to real-time, structured, and auditable.
IDP applies AI/ML—NLP, laptop imaginative and prescient, and supervised/unsupervised studying—to enterprise paperwork. In contrast to Automated Doc Processing (ADP), which depends on guidelines and templates, IDP adapts to unseen layouts, interprets semantic context, and improves repeatedly via suggestions loops. To know IDP’s function, consider it because the AI mind of doc automation, working in live performance with different instruments: OCR gives the eyes, RPA the fingers, and ADP the deterministic guidelines spine.
This text takes you beneath the hood of how this mind works, the applied sciences it builds on, and why enterprises can not ignore it.
IDP just isn’t a one-size-fits-all silver bullet. The suitable strategy will depend on your doc DNA. Whereas ADP could also be ample for high-volume, structured codecs, IDP is the smarter long-term play for variable or unstructured paperwork. Earlier than investing, consider your doc panorama on three axes—kind, variability, and velocity. This evaluation will information whether or not deterministic guidelines, adaptive intelligence, or a hybrid mannequin is one of the best match.
What Is Clever Doc Processing?
At its core, Clever Doc Processing (IDP) is the AI-driven transformation of paperwork into structured, validated, system-ready knowledge. The lifecycle is constant throughout industries:
Seize → Classify → Extract → Validate → Route → Be taught
In contrast to earlier generations of automation, IDP doesn’t cease at knowledge seize. It layers in machine studying fashions, NLP, and human-in-the-loop suggestions so every cycle improves accuracy.
One strategy to perceive IDP is to position it within the automation stack alongside associated instruments:
- OCR = the eyes. Optical Character Recognition converts pixels into machine-readable textual content.
- RPA = the fingers. Robotic Course of Automation mimics keystrokes and clicks.
- ADP = the foundations engine. Automated Doc Processing depends on templates and deterministic guidelines.
- IDP = the mind. Machine studying fashions interpret construction, semantics, and context.
This framing issues as a result of many enterprises conflate these instruments. In observe, they’re complementary, with IDP sitting on the intelligence layer that makes automation scalable past inflexible templates.
Why Clever Doc Processing Issues for IT, Resolution Architects, and Knowledge Scientists
- For IT leaders: IDP reduces the break/repair cycles that plague template-driven techniques. No extra firefighting each time a vendor tweaks an bill format.
- For resolution architects: IDP gives a versatile, API-first layer that scales throughout heterogeneous doc varieties — with out ballooning upkeep prices.
- For knowledge scientists: IDP formalizes a studying loop. Confidence scores, lively studying, and reviewer suggestions are baked into manufacturing pipelines, turning noisy human corrections into structured coaching alerts.
Key Phrases to Know
- Confidence scores: Every extracted area carries a chance used for routing (auto-post vs evaluation). Actual thresholds will likely be lined in a later part.
- Lively studying: A technique the place human corrections are recycled into mannequin coaching, decreasing guide effort over time.
- Structure-aware transformers (e.g., LayoutLM): Deep studying fashions that mix textual content, place, and visible cues to parse advanced layouts like invoices or kinds. (LayoutLM paper →)
- OCR-free fashions (e.g., Donut): Newer approaches that bypass OCR altogether, instantly parsing digital PDFs or pictures into structured outputs. (Donut paper →)
Briefly: IDP just isn’t “smarter OCR” or “higher RPA.” It’s the AI/ML mind that interprets paperwork, enforces context, and scales automation into domains the place templates collapse.
Subsequent, we’ll look beneath the hood on the core applied sciences — from machine studying fashions to NLP, laptop imaginative and prescient, and human-in-the-loop studying techniques — that make IDP potential at enterprise scale.
Core Applied sciences Below the Hood
IDP isn’t a single mannequin or API name. It is a layered structure combining machine studying, NLP, laptop imaginative and prescient, human suggestions, and, more and more, massive language fashions (LLMs). Every bit performs a definite function, and their orchestration is what allows IDP to scale throughout messy, high-volume enterprise doc units. As an example how these applied sciences work collectively, let’s hint a single doc—a posh customs declaration type with each typed and handwritten knowledge, a nested desk of products, and a signature.
Machine Studying Fashions: The Basis
Machine studying (ML) is the spine of IDP. In contrast to deterministic ADP techniques, IDP depends on fashions that be taught from knowledge, adapt to new codecs, and enhance repeatedly.
- Supervised Studying: The most typical strategy. Fashions are skilled on labeled samples—for our customs type, this is able to be a dataset with bounding bins round “Port of Entry,” “Worth,” and “Consignee.” This allows a supervised mannequin to acknowledge these fields with excessive accuracy on future, related kinds.
- Unsupervised/Self-Supervised Studying: Helpful when labeled knowledge is scarce. Fashions can cluster unlabeled paperwork by structure or content material similarity, grouping all customs kinds collectively earlier than a human even has to label them.
- Structure-Conscious Transformers: Fashions like LayoutLM are designed particularly for paperwork. They mix the extracted textual content with its spatial coordinates and visible cues. On our customs type, this mannequin understands not simply the phrases “Whole Worth,” but additionally that they’re positioned subsequent to a selected field and above a line of numbers, guaranteeing right knowledge extraction even when the shape structure varies barely.
| Doc Sort | Really useful Tech | Rationale |
|---|---|---|
| Fastened-format invoices | Supervised ML + light-weight OCR | Excessive throughput, low price |
| Receipts / cell captures | Structure-aware transformers | Strong to variable fonts, noise |
| Contracts | NLP-heavy + structure transformers | Captures clauses throughout pages |
Pure Language Processing (NLP): Understanding the Textual content
Whereas ML handles construction, NLP offers IDP semantic understanding. This issues most when the content material isn’t simply numbers and bins, however text-heavy narratives.
- Named Entity Recognition (NER): After the ML mannequin identifies the products desk on the customs type, NER extracts particular entities like “Amount” and “Description” from every line merchandise.
- Semantic Similarity: If the shape has a “Particular Directions” part with free-form textual content, NLP fashions can learn it to detect clauses associated to dealing with or transport dangers, guaranteeing a human flag is raised if the language is advanced.
- Multilingual Capabilities: For worldwide kinds, fashionable transformer fashions can course of languages from Spanish to Arabic, guaranteeing a single IDP system can deal with world paperwork with out guide language switching.
Pc Imaginative and prescient (CV): Seeing the Particulars
Paperwork aren’t at all times pristine PDFs. Scanned faxes, cell uploads, and stamped kinds introduce noise. CV layers in preprocessing and construction detection to stabilize downstream fashions.
- Pre-processing: If our customs type is a blurry fax, CV methods like de-skewing and binarization clear up the picture, making the textual content clearer for extraction.
- Construction Detection: CV fashions can exactly section the shape, figuring out separate zones for the typed desk, the handwritten signature, and any stamps, permitting specialised fashions to course of every space accurately. This ensures the handwritten signature is not misinterpreted as a part of the typed knowledge.
Human-in-the-Loop (HITL) + Lively Studying: Steady Enchancment
Even one of the best fashions aren’t 100% correct. HITL closes the hole by routing unsure fields to human reviewers—after which utilizing these corrections to enhance the mannequin. On our customs type, a really low confidence rating on the handwritten signature may set off an computerized escalation to a reviewer for verification. That correction then feeds again into the lively studying system, serving to the mannequin get higher at studying related handwriting over time.
LLM Augmentation (Rising Layer): The Last Semantic Layer
LLMs are the most recent frontier, including a layer of semantic depth. As soon as the customs type is processed, an LLM can present a fast abstract of the products, spotlight any uncommon objects, and even draft an e-mail to the logistics workforce based mostly on the extracted knowledge. This isn’t a alternative for IDP, however an augmentation that gives deeper, extra human-like interpretation.
How an IDP Workflow Truly Runs
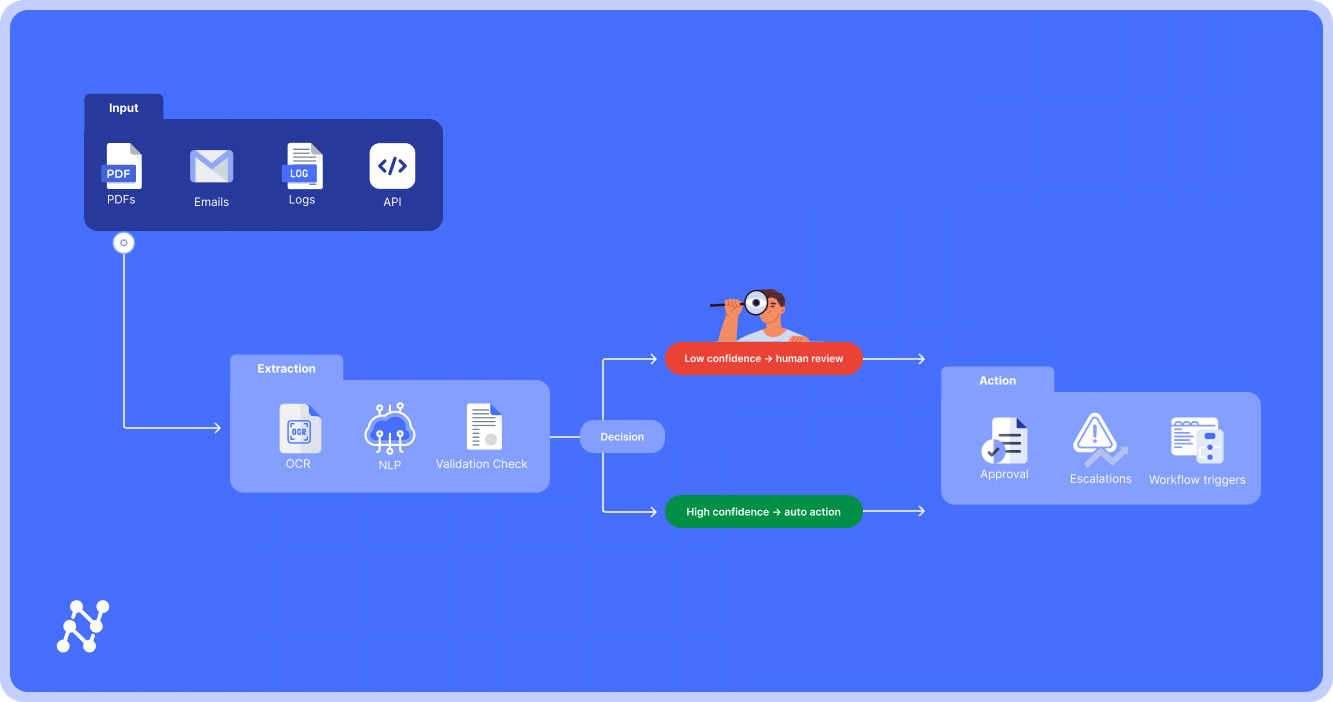
In observe, IDP isn’t a single “black field” AI—it’s a fastidiously orchestrated pipeline the place machine studying, enterprise guidelines, and human oversight interlock to ship dependable outcomes.
Enterprises care much less about mannequin structure and extra about whether or not paperwork circulate end-to-end with out fixed firefighting. That requires not solely extraction accuracy but additionally governance, validations, and workflows that stand as much as real-world quantity, range, and compliance.
Beneath, we break down an IDP workflow step-by-step—with technical particulars for IT and knowledge science, and operational advantages for finance, claims, and provide chain leaders.
Step 1. Ingestion Mesh — Getting Paperwork In Cleanly
- Channels supported: e-mail attachments, SFTP batch drops, API/webhooks, buyer/provider portals, cell seize apps.
- Pre-processing duties: MIME normalization, duplicate detection, virus scanning, metadata tagging.
- Governance hooks: idempotency keys (keep away from duplicates), retries with exponential backoff, DLQs (dead-letter queues) for failed paperwork.
- Personas impacted:
- IT → safety, authentication (SSO, MFA).
- Ops → throughput, SLA monitoring.
- Architects → resilience beneath peak load.
💡
Why it issues: With out sturdy consumption, you find yourself with fragmented workflows—one set of invoices in e-mail, one other on a portal, nonetheless one other coming through API. An ingestion mesh ensures each doc—whether or not 1 or 100,000—flows into the identical ruled pipeline.
Step 2. Classification — Realizing What You’re Wanting At
- Strategies: hybrid classifiers mixing structure options (type geometry) and semantic options (key phrases, embeddings).
- Confidence thresholds: high-confidence classifications route straight to extraction; low-confidence circumstances set off HITL evaluation.
- Restoration actions:
- Mis-routed doc → auto-reclassification engine.
- Unknown doc kind → tagged by reviewers, feeding lively studying.
💡
Instance: A customs declaration mis-sent as a “invoice of lading” is routinely corrected by the classifier after just a few coaching examples. Over time, the system’s taxonomy expands organically.
Step 3. Knowledge Extraction — Pulling Fields and Buildings
- Scope: key-value pairs (bill quantity, declare ID), tabular knowledge (line objects, shipments), signatures, and stamps.
- Enterprise guidelines: normalization of dates, tax percentages, foreign money codecs; per-line merchandise checks for totals.
- HITL UI: per-field confidence scores, color-coded, with keyboard-first navigation to reduce correction time.
💡
Why it issues: Extraction is the place most legacy OCR-based techniques break down. IDP’s edge lies in parsing variable layouts (multi-vendor invoices, multilingual contracts) whereas surfacing solely unsure fields for evaluation.
Step 4. Validation & Enterprise Guidelines — Implementing Coverage
- Cross-system checks:
- ERP: PO/bill matching, vendor grasp validation.
- CRM: buyer ID verification.
- HRIS: worker ID affirmation.
- Coverage enforcement: dual-sign approvals for high-value invoices, segregation of duties (SoD), SOX audit logging.
- Tolerance guidelines: e.g., settle for ±2% tax deviation, auto-flag >$10k transactions.
Persona lens:
- CFO → diminished duplicate funds, compliance assurance.
- COO → predictable throughput, fewer escalations.
- IT → integration stability through API-first design.
Step 5. Routing & Orchestration — Getting Clear Knowledge to the Proper Place
- Workflows supported:
- Finance → auto-post bill to ERP.
- Insurance coverage → open a declare in TPA system.
- Logistics → set off customs clearance workflow.
- Integrations: API/webhooks most well-liked; RPA as fallback solely when APIs are absent.
- Governance options: SLA timers on exception queues, escalation chains to approvers, Slack/Groups notifications for human motion.
💡
Key precept: Orchestration turns “extracted knowledge” into enterprise affect. With out routing, even 99% correct extraction is simply numbers sitting in a JSON file.
Step 6. Suggestions Loop — Making the System Smarter Over Time
- Confidence funnel: ≥0.95 → auto-post; 0.80–0.94 → HITL evaluation; <0.80 → escalate or reject. Granular thresholds may also be utilized per area (e.g., stricter for bill totals than for vendor addresses).
- Studying cycle: reviewer corrections are logged as coaching alerts, feeding lively studying pipelines.
- Ops guardrails: A/B testing new fashions earlier than manufacturing rollout; regression monitoring to forestall accuracy drops.
💡
Enterprise worth: That is the place IDP outpaces ADP. As an alternative of static templates that degrade over time, IDP learns from each exception—pushing first-pass yield larger month after month.
An IDP workflow is not only AI—it’s a ruled pipeline. It ingests paperwork from each channel, classifies them accurately, extracts fields with ML, validates in opposition to insurance policies, routes to core techniques, and repeatedly improves via suggestions. This mixture of machine studying, controls, and human evaluation is what makes IDP scalable in messy, high-stakes enterprise environments.
IDP vs Different Approaches — Drawing the Proper Boundaries
Clever Doc Processing (IDP) isn’t a alternative for OCR, RPA, or Automated Doc Processing (ADP). As an alternative, it acts because the orchestrator that makes them clever, complementing them by doing what they can not: studying, generalizing, and deciphering paperwork past templates. The danger in lots of enterprise packages is assuming these instruments are interchangeable—a class mistake that results in brittle, costly automation.
On this part, we’ll make clear their distinct roles and illustrate what occurs when these boundaries blur.
IDP vs. OCR
Whereas OCR gives the foundational “eyes” by changing pixels to textual content, it stays blind to which means or context. IDP builds on this textual content layer by including construction and semantics. It makes use of machine studying and laptop imaginative and prescient to know that “12345” is not only textual content, however a selected bill quantity linked to a vendor and due date. With out IDP, OCR-only techniques collapse in variable environments like multi-vendor invoices.
IDP vs. RPA
RPA serves because the “fingers,” automating keystrokes and clicks to bridge legacy techniques with out APIs. It’s quick to deploy however fragile when UIs change and essentially lacks an understanding of the info it is dealing with. Utilizing RPA for doc interpretation is a class mistake; IDP’s function is to extract and validate the info, guaranteeing the RPA bot solely pushes clear, enriched inputs into downstream techniques.
IDP vs. Generic Automation (BPM)
Enterprise Course of Administration (BPM) engines are the “visitors lights” of a workflow, orchestrating which duties are routed the place and when. They depend on fastened, static guidelines. IDP gives the adaptive “intelligence” inside these workflows by making sense of contracts, claims, or multilingual invoices earlier than the BPM engine routes them. With out IDP, BPM routes unverified, “blind” knowledge.
IDP with ADP
ADP (Automated Doc Processing) gives the deterministic spine, finest fitted to high-volume, low-variance paperwork like standardized kinds. It ensures auditability and throughput stability. IDP handles the variability that may break ADP’s templates, adapting to new bill layouts and unstructured contracts. Each are required at enterprise scale: ADP for determinism and stability, IDP for managing ambiguity and adaptation.
Errors to Keep away from in Doc Automation
The most typical mistake is assuming these instruments are interchangeable. The mistaken selection results in pricey, fragile options.
- Overinvesting in IDP for steady codecs: In case your invoices are from a single vendor, deterministic ADP guidelines will ship quicker ROI than ML-heavy IDP.
- Utilizing RPA for interpretation: Let IDP deal with which means; RPA ought to solely bridge techniques with out APIs.
- Treating OCR as a full resolution: OCR captures textual content however doesn’t perceive it, permitting errors to leak into core enterprise techniques.
✅ Rule of thumb: Map your doc DNA first (quantity, variability, velocity). Then determine what mixture of OCR, RPA, ADP, BPM, and IDP suits finest.
IDP in Observe: Actual-World Use Instances & Enterprise Outcomes
Clever Doc Processing (IDP) proves its value within the messy actuality of contracts, invoices, claims, and affected person data. What makes it enterprise-ready is not simply its extraction accuracy, however the way in which it enforces validations, triggers approvals, and integrates into downstream workflows to ship measurable enhancements in accuracy, scalability, compliance, and price effectivity.
In contrast to conventional OCR or ADP, IDP would not simply digitize—it learns, validates, and scales throughout unstructured inputs, decreasing exception overhead whereas strengthening governance. In contrast, template-based techniques usually plateau at round 70–80% field-level accuracy. IDP packages, nonetheless, persistently obtain 90–95%+ accuracy throughout various doc units as soon as human-in-the-loop (HITL) suggestions is embedded, with some benchmarks reporting as much as ~99% accuracy in narrowly outlined contexts. This accuracy just isn’t static; IDP pipelines compound accuracy over time as corrections feed again into fashions.
The transformation is finest seen in a side-by-side comparability of key operational metrics.
Advantages (Expertise Outcomes)
| Metric | Earlier than (ADP / Guide) | After (IDP-enabled) |
|---|---|---|
| Subject-level accuracy | 70–80% (template-driven, brittle) | 90–95%+ (compounding through HITL suggestions) |
| First-pass yield (FPY) | 50–60% paperwork circulate via untouched | 80–90% paperwork auto-processed |
| Bill processing price | $11–$13 per bill (guide/AP averages) | $2–$3 per bill (IDP-enabled) |
| Cycle time | Days (guide routing & approvals) | Minutes → Hours (with validation + SLA timers) |
| Compliance | Audit trails fragmented; dangerous exception dealing with | Immutable occasion logs; per-field confidence scores |
Let’s discover how this performs out throughout 5 key doc households.
Contracts: Clause Extraction and Obligation Administration
Contract processing is the place static automation usually breaks. A 60-page provider settlement might include indemnity clauses, renewal phrases, or legal responsibility caps buried throughout sections and in inconsistent codecs. With IDP, contracts are ingested from PDFs or scans, categorised and parsed with layout-aware NLP, and validated for required clauses. Counterparties are checked in opposition to vendor masters, deviations past thresholds (e.g., indemnity >$1M) set off escalations, and obligations circulate seamlessly into the CLM. Non-standard language would not sit unnoticed—it triggers an alert to Authorized Ops, whereas LLM summarization gives digestible clause evaluations grounded in supply textual content.
Final result: Obligations are tracked on time, non-standard clauses are flagged immediately, and authorized threat publicity is considerably lowered.
Monetary Paperwork: Invoices, Financial institution Statements, and KYC
Finance is commonly the primary area the place brittle automation hurts. Bill codecs fluctuate, IBANs get miskeyed, and KYC packs include a number of IDs. Right here, IDP extracts totals and line objects, however extra importantly, it enforces finance coverage: cross-checks invoices in opposition to POs and items receipts, validates vendor knowledge in opposition to grasp data, and screens KYC paperwork in opposition to sanctions lists. Excessive-value invoices set off twin approvals, whereas segregation-of-duties guidelines block conflicts. Clear invoices auto-post into ERP; mismatches circulate into dispute queues. Business analysis places guide bill dealing with round $11–$13 per bill, whereas automation reduces this to ~$2–$3, yielding financial savings at scale. A Harvard Enterprise Faculty/BCG examine discovered that AI instruments boosted productiveness by 12.2% and minimize job time by 25.1% in information work, mirroring what IDP delivers in document-heavy workflows.
Final result: Cheaper invoices, quicker closes, and stronger compliance—all backed by measurable ROI.
Insurance coverage: FNOL Packets and Coverage Paperwork
A single insurance coverage declare may bundle a type, a coverage doc, and a medical report—every with distinctive codecs. The place ADP thrives in finance/AP, IDP scales horizontally throughout domains like insurance coverage, the place doc range is the rule, not the exception. IDP parses and classifies every doc, validating protection, checking ICD/CPT codes, and recognizing crimson flags equivalent to duplicate VINs. Low-value claims circulate straight via, whereas high-value or suspicious ones path to adjusters or SIU. Structured knowledge feeds actuaries for fraud analytics, whereas LLM summaries give adjusters fast narratives backed by IDP outputs.
Final result: Quicker claims triage, diminished leakage from fraud, and an improved policyholder expertise.
Healthcare: Affected person Data and Referrals
Healthcare paperwork mix messy inputs with strict compliance. Affected person IDs and NPIs should match, consent kinds have to be current, and codes should align with payer insurance policies. IDP parses scans and notes, flags lacking consent kinds, validates therapy codes, and routes prior-auth requests into payer techniques. Each motion is logged for HIPAA compliance. Handwriting fashions seize doctor notes, whereas PHI redaction ensures secure downstream LLM use.
Final result: Quicker prior-auth approvals, decrease clerical load, and regulatory compliance by design.
Logistics: Payments of Lading and Customs Paperwork
International provide chains are document-heavy, and a single error in a invoice of lading or customs declaration can cascade into detention and demurrage charges. These prices aren’t theoretical: a container held at a port for lacking or inconsistent paperwork can run a whole bunch of {dollars} per day in penalties. With IDP, logistics groups can automate classification and validation throughout multilingual transport manifests, payments of lading, and customs kinds. Knowledge is cross-checked in opposition to tariff codes, service databases, and cargo data. Incomplete or mismatched paperwork are flagged earlier than they attain customs clearance, decreasing pricey delays. Approvals are triggered for high-risk shipments (e.g., hazardous items, dual-use exports) whereas compliant paperwork circulate straight via.
Final result: Quicker clearance, fewer fines, improved visibility, and diminished working capital tied up in delayed shipments.
Why IDP Issues for IT, Resolution Architects & Knowledge Scientists
Clever Doc Processing (IDP) isn’t simply an operations win—it reshapes how IT leaders, resolution architects, and knowledge scientists design, run, and enhance enterprise doc workflows.
Every function faces totally different pressures: stability and safety for IT, flexibility and time-to-change for architects, and mannequin lifecycle rigor for knowledge scientists. IDP issues as a result of it unifies these priorities right into a system that’s each adaptable and ruled.
| Function | High Priorities | How IDP Helps | Dangers With out IDP |
|---|---|---|---|
| IT Leaders | API-first integration, RBAC, audit logs, HA/DR, observability | Reduces reliance on fragile RPA, enforces compliance through immutable logs, scales predictably with infra sizing | Safety gaps, brittle workflows, downtime beneath peak load |
| Resolution Architects | Reusable patterns, quick onboarding of latest doc varieties, orchestration flexibility | Gives sample libraries, reduces template creation time, blends guidelines (ADP) with studying (IDP) | Weeks of rework for brand spanking new docs, brittle workflows that collapse beneath variability |
| Knowledge Scientists | Annotation technique, lively studying, drift detection, rollback security | Focuses labeling effort through lively studying, improves repeatedly, ensures secure deployments with rollback paths | Fashions degrade as codecs drift, excessive labeling prices, ungoverned ML lifecycles |
For IT Leaders — Stability, Safety, and Scale
IT leaders are tasked with constructing platforms that don’t simply work right this moment however scale reliably for tomorrow. In document-heavy enterprises, the query isn’t whether or not to automate—it’s the way to do it with out compromising safety, compliance, and resilience.
- API-first integration: Fashionable IDP stacks expose clear APIs that plug instantly into ERP, CRM, and content material administration techniques, decreasing reliance on brittle RPA scripts. When APIs are absent, RPA can nonetheless be used—however as a fallback, not the spine.
- Safety and governance: Function-based entry management (RBAC) ensures delicate knowledge (like PII or PHI) is barely seen to approved customers. Immutable audit logs monitor each extraction, correction, and approval, which is vital for compliance frameworks equivalent to SOX, HIPAA, and GDPR.
- Infrastructure readiness: IDP brings workloads which are GPU-heavy in coaching however CPU-efficient at inference. IT should measurement infrastructure for peak throughput, provision excessive availability (HA), and catastrophe restoration (DR), and implement observability layers (metrics, traces, logs) to detect bottlenecks.
Backside line for IT: IDP reduces fragility by minimizing RPA dependence, strengthens compliance via auditable pipelines, and scales predictably with the fitting infra sizing and observability in place.
For Resolution Architects — Designing for Variability
Resolution architects dwell within the area between enterprise necessities and technical realities. Their mandate: design automation that adapts as doc varieties evolve.
- Sample libraries: IDP permits architects to outline reusable ingestion, classification, validation, and routing patterns. As an alternative of one-off templates, they create modular constructing blocks that deal with households of paperwork.
- Time-to-change: In rule-based techniques, including a brand new doc kind may take weeks of template design. With IDP, supervised fashions fine-tuned on annotated samples cut back onboarding to days. Lively studying additional accelerates this by letting fashions enhance repeatedly with human suggestions.
- Orchestration flexibility: Architects can embed enterprise guidelines the place determinism issues (e.g., approvals, segregation of duties) and let IDP deal with variability the place templates fail (e.g., new bill layouts, contract clauses).
Backside line for architects: IDP extends their toolkit from inflexible guidelines to adaptive intelligence. This stability means fewer brittle workflows and quicker responses to altering doc ecosystems.
For Knowledge Scientists — A Residing ML System
In contrast to static analytics initiatives, IDP techniques are dwell ML ecosystems that should be taught, enhance, and be ruled in manufacturing. Knowledge scientists in IDP packages face a really totally different actuality than in conventional mannequin deployments.
- Annotation technique: Excessive-quality coaching knowledge is the only most vital issue for IDP accuracy. DS groups should stability annotation throughput with high quality, usually utilizing weak supervision or lively studying to maximise effectivity.
- Lively studying queues: As an alternative of labeling paperwork at random, IDP techniques prioritize “onerous” circumstances (low-confidence, unseen layouts) for human evaluation. This ensures mannequin enhancements the place they matter most.
- MLOps lifecycle: IDP requires sturdy launch and rollback methods. Fashions have to be evaluated offline on validation units, then on-line with A/B testing to make sure accuracy doesn’t regress.
- Drift detection: Doc codecs evolve consistently—new distributors, new clause language, new healthcare kinds. Steady monitoring for distributional drift is obligatory to maintain fashions performant over time.
Backside line for DS groups: IDP just isn’t a one-time deployment—it’s an evolving ML program. Success will depend on robust annotation pipelines, lively studying methods, and mature MLOps practices.
The Balancing Act: IDP and ADP Collectively
Enterprises usually fall into the lure of asking: “Ought to we use ADP or IDP?” The fact is that each are required at scale.
- ADP (Automated Doc Processing) gives the deterministic spine—guidelines, validations, and routing. It ensures compliance and repeatability.
- IDP (Clever Doc Processing) gives the adaptive mind—machine studying that handles unstructured and variable codecs.
“With out ADP’s determinism, IDP can not scale. With out IDP’s intelligence, ADP collapses beneath variability.”
Every persona sees IDP in a different way: IT leaders concentrate on safety and stability, architects on adaptability, and knowledge scientists on steady studying. However the convergence is evident: IDP is the ML mind that, mixed with ADP’s guidelines spine, makes enterprise automation each resilient and scalable.
Construct vs Purchase — A Technical Resolution Lens
When you’ve audited your doc DNA and decided that IDP is the fitting match, the following query is evident: do you construct in-house fashions, purchase a vendor platform, or pursue a hybrid strategy? The suitable selection will depend on the way you stability management, time-to-value, and compliance in opposition to the realities of knowledge labeling, mannequin upkeep, and safety posture.
When to Construct — Management and Customized IP
Constructing your individual IDP stack appeals to groups that worth management and differentiation. By coaching customized fashions, you personal the mental property, tune efficiency for domain-specific edge circumstances, and retain full visibility into the ML lifecycle.
However management comes at a price:
- Knowledge/labeling burden: Excessive-quality labeled datasets are the bedrock of IDP efficiency. Constructing requires sustained funding in annotation pipelines, tooling, and workforce administration.
- MLOps lifecycle: You inherit duty for versioning, rollback methods, monitoring for drift, and refreshing fashions at an everyday cadence (usually quarterly or quicker in dynamic domains).
- Compliance overhead: In regulated industries (finance, healthcare, insurance coverage), self-built options should obtain certifications (SOC 2, HIPAA, ISO) and stand up to audits—burdens normally absorbed by distributors.
Construct is smart for organizations with robust ML groups, distinctive doc varieties (e.g., specialised underwriting packs), and strategic curiosity in proudly owning IP.
When to Purchase — Accelerators and Assurance
Shopping for from an IDP vendor gives velocity and assurance. Fashionable platforms ship with pre-trained accelerators for frequent doc households: invoices, POs, IDs, KYC paperwork, contracts. They usually arrive with:
- Certifications baked in: SOC 2, ISO, HIPAA compliance frameworks already validated.
- Connectors and APIs: Prepared-made integrations for ERP (SAP, Oracle), CRM (Salesforce), and storage techniques (SharePoint, S3).
- Assist for HITL workflows: Configurable reviewer consoles, audit logs, and approval chains.
The trade-off is opacity and suppleness. Some platforms act as black bins—you possibly can’t see mannequin internals or adapt coaching past predefined accelerators. For enterprises needing explainability, this may restrict adoption.
Purchase is smart once you want speedy time-to-value, trade certifications, and protection for frequent doc varieties.
When to Go Hybrid — Better of Each Worlds
In observe, many enterprises find yourself with a hybrid mannequin:
- Use vendor platforms for the 80% of paperwork that match frequent accelerators.
- Construct customized fashions for area of interest, high-value doc households (e.g., mortgage origination packs, insurance coverage bordereaux, affected person referral bundles).
This strategy reduces time-to-market whereas nonetheless letting inner knowledge science groups apply domain-specific carry. Distributors more and more assist this mannequin with bring-your-own-model (BYOM) choices—the place customized ML fashions can plug into their ingestion and workflow engines.
Hybrid is smart when enterprises need vendor reliability with out giving up management over specialised circumstances.
Resolution Matrix — Construct vs Purchase vs Hybrid
| Standards | Construct | Purchase | Hybrid |
|---|---|---|---|
| Time-to-value | Sluggish (months for knowledge & infra) | Quick (weeks with pre-trained accelerators) | Reasonable (weeks for core, months for customized) |
| Mannequin possession | Full management & IP | Vendor-owned, black-box threat | Cut up (vendor core + customized fashions) |
| Labeling overhead | Excessive (guide + lively studying required) | Low (pre-trained units included) | Medium (low for traditional docs, excessive for area of interest) |
| Change velocity | Quick for customized fashions, however useful resource heavy | Restricted flexibility; vendor launch cycles | Balanced—vendor updates core, groups adapt area of interest |
| Safety posture | Customized certifications required; heavy burden | Certifications pre-included (SOC 2, ISO, HIPAA) | Combined—vendor covers core; groups certify area of interest |
Sensible Steering
Most enterprises overestimate their capability to maintain a pure-build strategy. Knowledge labeling, compliance, and MLOps burdens develop quicker than anticipated. Essentially the most pragmatic path is normally:
- Begin buy-first → leverage vendor accelerators for frequent paperwork.
- Show worth in 4–6 weeks with invoices, POs, or KYC packs.
- Prolong with in-house fashions solely the place domain-specific carry issues
The Highway Forward for IDP — Future Instructions & Sensible Subsequent Steps
Clever Doc Processing (IDP) has matured into the AI/ML mind of enterprise doc workflows. It enhances ADP’s guidelines spine and RPA’s execution bridge, however its subsequent evolution goes additional: including semantic understanding, autonomous brokers, and enterprise-grade governance.
The chance is big—and organizations don’t want to attend to begin benefiting.
From Capturing Fields to Understanding Which means
For many of the final decade, IDP success was measured by way of accuracy and throughput: how nicely may techniques classify a doc and extract key fields? That downside isn’t going away, however the bar is transferring larger.
The brand new wave of IDP is about semantics, not simply syntax. Giant Language Fashions (LLMs) can now sit on prime of structured IDP outputs to:
- Summarize lengthy contracts into digestible threat experiences.
- Flag uncommon indemnity clauses or lacking obligations.
- Flip unstructured affected person notes into structured medical codes plus a story abstract.
Crucially, these insights may be grounded with RAG (retrieval-augmented era) so that each AI-generated abstract factors again to authentic textual content. That’s not simply helpful—it’s important for audits, authorized evaluation, and compliance-heavy industries.
From Inflexible Workflows to Autonomous Brokers
In the present day’s IDP techniques route structured knowledge into ERPs, CRMs, claims platforms, or TMS portals. Tomorrow, that’s only the start.
We’re coming into the period of multi-agent orchestration, the place AI brokers eat IDP knowledge and carry processes additional on their very own:
- Retriever brokers fetch the fitting paperwork from repositories.
- Validator brokers verify in opposition to insurance policies or threat thresholds.
- Executor brokers carry out actions in techniques of file—posting entries, triggering funds, or updating claims.
Consider claims triage, accounts payable reconciliation, or customs clearance working agentically, with people stepping in just for oversight or exception dealing with.
The Governance Crucial
However better autonomy brings better threat. As LLMs and brokers enter doc workflows, enterprises face questions on reliability, security, and accountability.
Mitigating that threat requires new disciplines:
- Analysis harnesses to stress-test workflows earlier than launch.
- Pink-team prompting to uncover weaknesses in mannequin habits.
- Charge limiters and price screens to maintain operations steady and predictable.
- Immutable audit trails to fulfill regulators and guarantee inner stakeholders.
The successful IDP packages will likely be those who mix innovation with governance—pushing towards new capabilities with out sacrificing management.
What Enterprises Ought to Do Now
The long run is thrilling, however the true query for many leaders is: what ought to we do right this moment?
The playbook is easy:
- Audit your doc DNA. What varieties dominate your enterprise? How variable are they? What’s the speed? This tells you whether or not ADP, IDP, or each are wanted.
- Choose one household for a pilot. Invoices, contracts, claims—select one thing high-volume and pain-heavy.
- Run a 4–6 week pilot. Monitor 4 metrics: accuracy (F1 rating), first-pass yield, exception price, and cycle time.
- Scale with intent. Broaden to adjoining doc varieties. Layer ADP for compliance, IDP for variability, and use RPA solely the place APIs aren’t accessible.
- Construct future hooks. Even when you don’t deploy LLMs or brokers right this moment, design workflows that might accommodate them later. That method, you’re not re-architecting in two years.
The purpose isn’t to leap straight into futuristic agent-driven workflows—it’s to begin measuring and capturing worth now whereas making ready for what’s subsequent.
FAQs
1. What do analyst corporations say in regards to the IDP market?
Analyst corporations usually place Clever Doc Processing (IDP) throughout the broader “clever automation” or “hyperautomation” stack alongside RPA, BPM/workflow, and analytics. Whereas terminology varies (e.g., “doc AI,” “content material intelligence,” “clever automation platforms”), the consensus is that IDP gives the studying and interpretation layer that makes automation resilient when doc codecs fluctuate.
They consider distributors on ingestion, classification, extraction, HITL evaluation, workflow depth, platform qualities, and time-to-value. Enterprises ought to map their doc DNA (quantity, variability, velocity) in opposition to vendor strengths and validate through time-boxed pilots measuring F1, FPY, exception charges, and cycle instances.
2. What’s RAG (retrieval-augmented era) in IDP, and the way is it wired into the pipeline?
Retrieval-augmented era (RAG) grounds LLM outputs in retrieved supply paperwork, decreasing hallucinations and guaranteeing traceability. In IDP pipelines, RAG sits after extraction to allow summaries and explanations that cite authentic textual content.
Typical circulate:
- IDP extracts structured fields/tables with confidence scores.
- Textual content chunks + metadata (web page, part, doc kind) are embedded right into a vector index.
- A retriever selects related chunks, that are appended to the LLM immediate.
- The LLM generates grounded outputs (summaries, threat flags, obligation lists) with citations.
- Outputs, retrieval units, and mannequin variations are logged for audit.
3. What dangers include LLMs in doc workflows, and the way will we mitigate them?
Key dangers embrace hallucinations, knowledge leakage, immediate injection, compliance gaps, price/latency spikes, and explainability calls for.
Mitigation methods:
- Hallucinations: Use RAG grounding, “answer-from-context” prompting, factuality testing.
- Knowledge leakage: Redact PII, implement personal deployments, encrypt retention.
- Immediate injection: Sanitize retrieved textual content, limit software calls, red-team for assaults.
- Compliance gaps: Log all prompts/outputs, implement RBAC, pin mannequin variations.
- Price/latency: Use smaller fashions for routine duties, cache embeddings, batch jobs.
- Explainability: Drive LLMs to quote web page/part; present retrieval set to reviewers.
Rule of thumb: Deal with the LLM as a semantic assistant layered on IDP outputs, not the ultimate authority.
4. How ought to enterprises measure IDP success?
IDP success needs to be measured throughout accuracy, throughput, price, and governance:
- Accuracy: F1 rating per area, actual match %, exception price, confidence-based auto-post price.
- Throughput: First-pass yield (FPY), cycle instances (P50/P95), reviewer minutes per doc.
- Price: Price per doc together with compute + human evaluation, scalability at peak hundreds.
- Governance: Audit completeness, drift alerts resolved, rollback readiness.
Run a 4–6 week pilot to baseline these metrics, then monitor month-to-month. Success = larger F1/FPY, decrease exceptions and price/doc, and steady auditability.
5. Can IDP deal with handwriting reliably? What ought to we count on?
Sure—fashionable IDP platforms can deal with handwriting, however reliability will depend on scan high quality, script, and language. Anticipate robust outcomes on brief structured fields (names, dates, quantities) if scans are clear (≥300 DPI).
Challenges come up with cursive scripts, noisy cell captures, and non-Latin handwriting with out domain-specific coaching.
Finest practices embrace:
- Pre-process scans (de-skew, distinction enhance).
- Zone handwriting individually from typed sections.
- Implement area constraints (e.g., date codecs).
- Apply confidence funnels (≥0.95 auto, 0.80–0.94 evaluation, <0.80 escalate).
- Feed reviewer corrections again into coaching.
Expectation: Combined-type paperwork can obtain 95%+ accuracy with HITL. Handwriting-heavy kinds should still want selective evaluation at first.