

{kind=link}
A crew of researchers from MBZUAI’s Institute of Basis Fashions and G42 launched K2 Assume, is a 32B-parameter open reasoning system for superior AI reasoning. It pairs lengthy chain-of-thought supervised fine-tuning with reinforcement studying from verifiable rewards, agentic planning, test-time scaling, and inference optimizations (speculative decoding + wafer-scale {hardware}). The result’s frontier-level math efficiency with markedly decrease parameter rely and aggressive outcomes on code and science—along with a clear, absolutely open launch spanning weights, knowledge, and code.
System overview
K2 Assume is constructed by post-training an open-weight Qwen2.5-32B base mannequin and including a light-weight test-time compute scaffold. The design emphasizes parameter effectivity: a 32B spine is intentionally chosen to allow quick iteration and deployment whereas leaving headroom for post-training positive factors. The core recipe combines six “pillars”: (1) Lengthy chain-of-thought (CoT) supervised fine-tuning; (2) Reinforcement Studying with Verifiable Rewards (RLVR); (3) agentic planning earlier than fixing; (4) test-time scaling through best-of-N choice with verifiers; (5) speculative decoding; and (6) inference on a wafer-scale engine.
The objectives are easy: increase move@1 on competition-grade math benchmarks, keep sturdy code/science efficiency, and preserve response size and wall-clock latency beneath management by plan-before-you-think prompting and hardware-aware inference.
Pillar 1: Lengthy CoT SFT
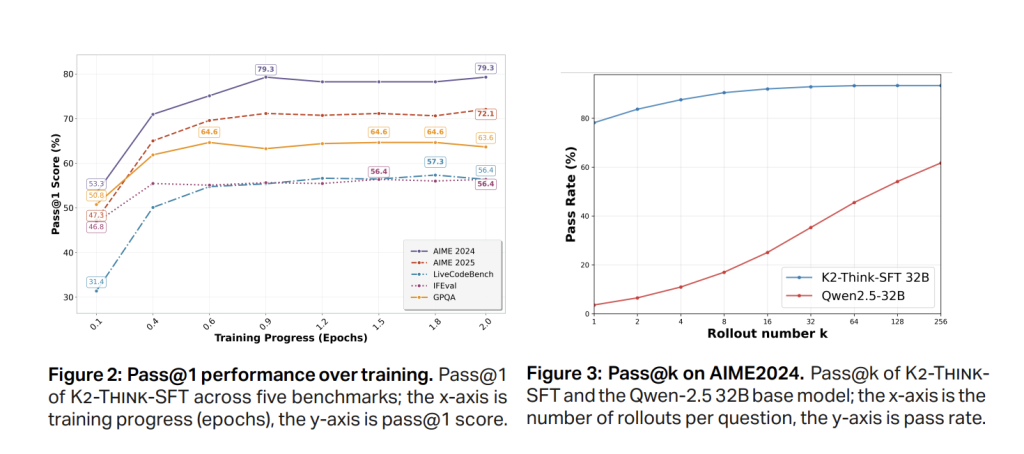
Section-1 SFT makes use of curated, lengthy chain-of-thought traces and instruction/response pairs spanning math, code, science, instruction following, and normal chat (AM-Pondering-v1-Distilled). The impact is to show the bottom mannequin to externalize intermediate reasoning and undertake a structured output format. Speedy move@1 positive factors happen early (≈0.5 epoch), with AIME’24 stabilizing round ~79% and AIME’25 round ~72% on the SFT checkpoint earlier than RL, indicating convergence.
Pillar 2: RL with Verifiable Rewards
K2 Assume then trains with RLVR on Guru, a ~92k-prompt, six-domain dataset (Math, Code, Science, Logic, Simulation, Tabular) designed for verifiable end-to-end correctness. The implementation makes use of the verl library with a GRPO-style policy-gradient algorithm. Notable statement: beginning RL from a sturdy SFT checkpoint yields modest absolute positive factors and may plateau/degenerate, whereas making use of the identical RL recipe immediately on the bottom mannequin exhibits massive relative enhancements (e.g., ~40% on AIME’24 over coaching), supporting a trade-off between SFT power and RL headroom.
A second ablation exhibits multi-stage RL with a diminished preliminary context window (e.g., 16k → 32k) underperforms—failing to get well the SFT baseline—suggesting that decreasing max sequence size beneath the SFT regime can disrupt realized reasoning patterns.
Pillars 3–4: Agentic “Plan-Earlier than-You-Assume” and Check-time Scaling
At inference, the system first elicits a compact plan earlier than producing a full resolution, then performs best-of-N (e.g., N=3) sampling with verifiers to pick out probably the most likely-correct reply. Two results are reported: (i) constant high quality positive factors from the mixed scaffold; and (ii) shorter remaining responses regardless of the added plan—common token counts drop throughout benchmarks, with reductions as much as ~11.7% (e.g., Omni-HARD), and general lengths corresponding to a lot bigger open fashions. This issues for each latency and value.
Desk-level evaluation exhibits K2 Assume’s response lengths are shorter than Qwen3-235B-A22B and in the identical vary as GPT-OSS-120B on math; after including plan-before-you-think and verifiers, K2 Assume’s common tokens fall versus its personal post-training checkpoint (e.g., AIME’24 −6.7%, AIME’25 −3.9%, HMMT25 −7.2%, Omni-HARD −11.7%, LCBv5 −10.5%, GPQA-D −2.1%).
Pillars 5–6: Speculative decoding and wafer-scale inference
K2 Assume targets Cerebras Wafer-Scale Engine inference with speculative decoding, promoting per-request throughput upwards of 2,000 tokens/sec, which makes the test-time scaffold sensible for manufacturing and analysis loops. The hardware-aware inference path is a central a part of the discharge and aligns with the system’s “small-but-fast” philosophy.
Analysis protocol
Benchmarking covers competition-level math (AIME’24, AIME’25, HMMT’25, Omni-MATH-HARD), code (LiveCodeBench v5; SciCode sub/fundamental), and science data/reasoning (GPQA-Diamond; HLE). The analysis crew stories a standardized setup: max era size 64k tokens, temperature 1.0, top-p 0.95, cease marker </reply>, and every rating as a median of 16 unbiased move@1 evaluations to cut back run-to-run variance.
Outcomes
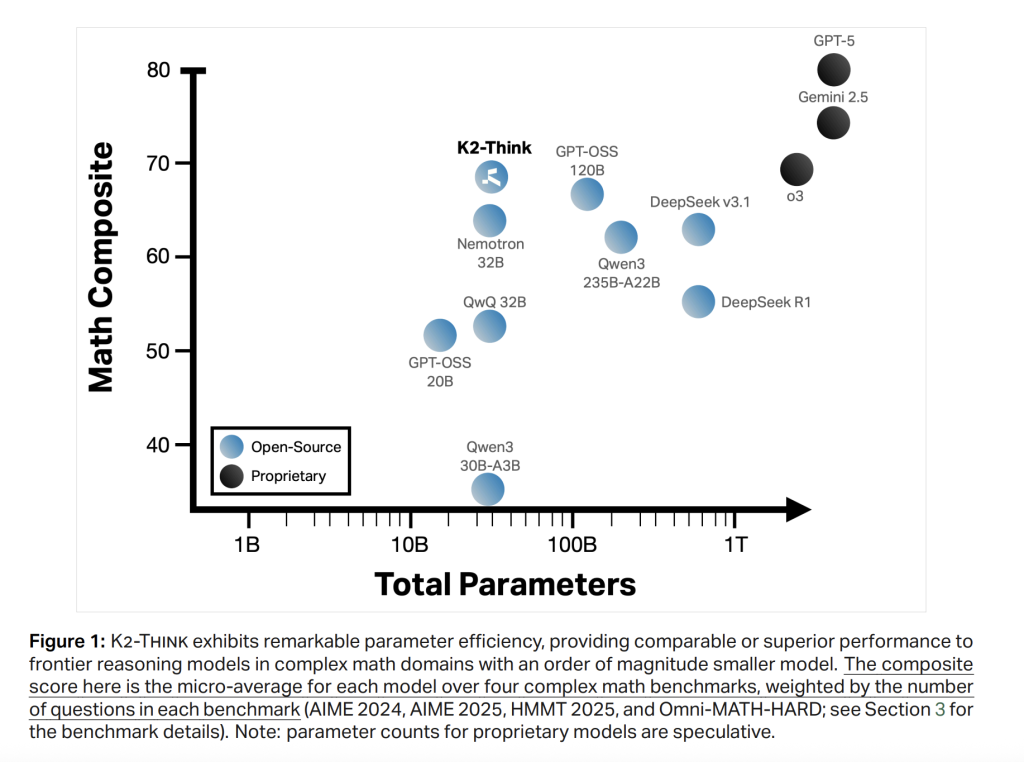
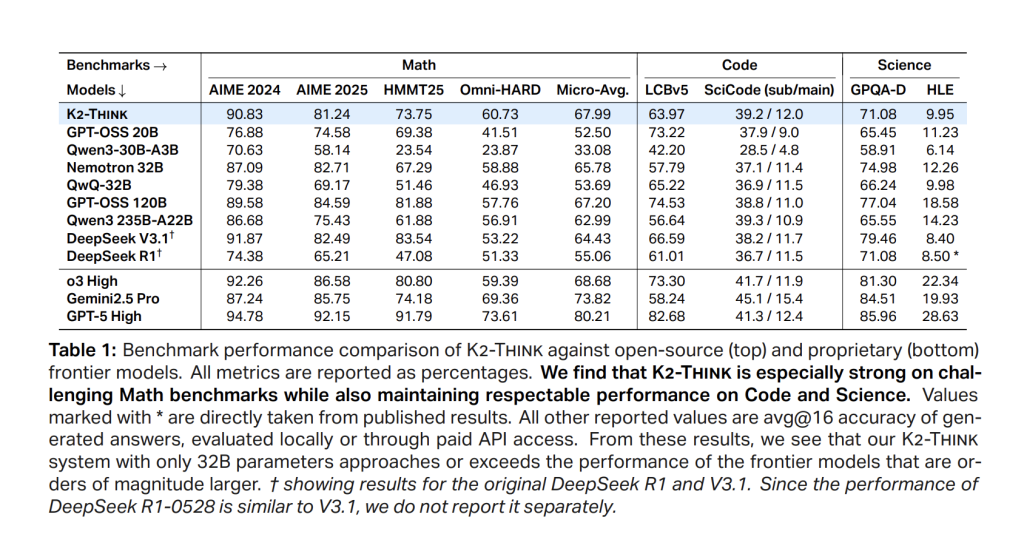
Math (micro-average throughout AIME’24/’25, HMMT25, Omni-HARD). K2 Assume reaches 67.99, main the open-weight cohort and evaluating favorably even to a lot bigger techniques; it posts 90.83 (AIME’24), 81.24 (AIME’25), 73.75 (HMMT25), and 60.73 on Omni-HARD—the latter being probably the most troublesome cut up. The positioning is in step with sturdy parameter effectivity relative to DeepSeek V3.1 (671B) and GPT-OSS-120B (120B).
Code. LiveCodeBench v5 rating is 63.97, exceeding equally sized friends and even bigger open fashions (e.g., > Qwen3-235B-A22B at 56.64). On SciCode, K2 Assume is 39.2/12.0 (sub/fundamental), monitoring one of the best open techniques carefully on sub-problem accuracy.
Science. GPQA-Diamond reaches 71.08; HLE is 9.95. The mannequin is not only a math specialist: it stays aggressive throughout knowledge-heavy duties.

Key numbers at a look
- Spine: Qwen2.5-32B (open weight), post-trained with lengthy CoT SFT + RLVR (GRPO through verl).
- RL knowledge: Guru (~92k prompts) throughout Math/Code/Science/Logic/Simulation/Tabular.
- Inference scaffold: Plan-before-you-think + BoN with verifiers; shorter outputs (e.g., −11.7% tokens on Omni-HARD) at larger accuracy.
- Throughput goal: ~2,000 tok/s on Cerebras WSE with speculative decoding.
- Math micro-avg: 67.99 (AIME’24 90.83, AIME’25 81.24, HMMT’25 73.75, Omni-HARD 60.73).
- Code/Science: LCBv5 63.97; SciCode 39.2/12.0; GPQA-D 71.08; HLE 9.95.
- Security-4 macro: 0.75 (Refusal 0.83, Conv. Robustness 0.89, Cybersecurity 0.56, Jailbreak 0.72).
Abstract
K2 Assume demonstrates that integrative post-training + test-time compute + hardware-aware inference can shut a lot of the hole to bigger, proprietary reasoning techniques. At 32B, it’s tractable to fine-tune and serve; with plan-before-you-think and BoN-with-verifiers, it controls token budgets; with speculative decoding on wafer-scale {hardware}, it reaches ~2k tok/s per request. K2 Assume is introduced as a absolutely open system—weights, coaching knowledge, deployment code, and test-time optimization code.
Take a look at the Paper, Mannequin on Hugging Face, GitHub and Direct Entry. Be at liberty to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.