

{kind=link}
Unlocking highly effective search capabilities for thousands and thousands of things must be quick, correct, and easy whereas sustaining excessive relevance. Relational databases are a well-liked storage technique for structured information, and organizations use them extensively to retailer their core enterprise info. Though relational databases excel at storing and retrieving structured information, they usually wrestle with looking out via massive blocks of unstructured textual content and, for efficiency causes, sometimes don’t index all columns.
In distinction, serps similar to OpenSearch index all fields, enabling wealthy search capabilities, together with semantic search, and highly effective aggregations for summarizing and analyzing numeric information. Historically, organizations have managed advanced, inefficient, and costly information synchronization processes, together with extract, rework, and cargo (ETL) pipelines, to maintain their search indices updated with their databases. These seeking to improve their purposes with superior search options want an easier answer that may preserve search index synchronization with their databases with out the overhead of managing customized information sync processes.
We’re blissful to announce the final availability of the combination of Amazon OpenSearch Service with Amazon Relational Database Service (Amazon RDS) and Amazon Aurora. This new integration eliminates advanced information pipelines and permits close to real-time information synchronization between Amazon Aurora (together with Amazon Aurora MySQL-Suitable Version and Amazon Aurora PostgreSQL-Suitable Version) and Amazon RDS databases (together with Amazon RDS for MySQL and Amazon RDS for PostgreSQL), and Amazon OpenSearch Service, unlocking superior search capabilities similar to hybrid search, ranked outcomes, and faceted search on transactional databases. Now you can ship low-latency, high-throughput search outcomes, dwell stock updates, and customized suggestions whereas specializing in creating distinctive buyer experiences as a substitute of managing information synchronization. This integration reduces the operational burden of sustaining advanced ETL pipelines, decreasing prices whereas offering on the spot information availability for search operations.
Amazon OpenSearch Ingestion supplies close to real-time information synchronization between Amazon Aurora or Amazon RDS and OpenSearch Service. Choose your Aurora or RDS database, and OpenSearch Ingestion handles the remaining, supporting each Aurora MySQL or RDS for MySQL (8.0 and above) and Aurora PostgreSQL or RDS for PostgreSQL (16 and above).
Answer overview
Right here’s how these providers work collectively:
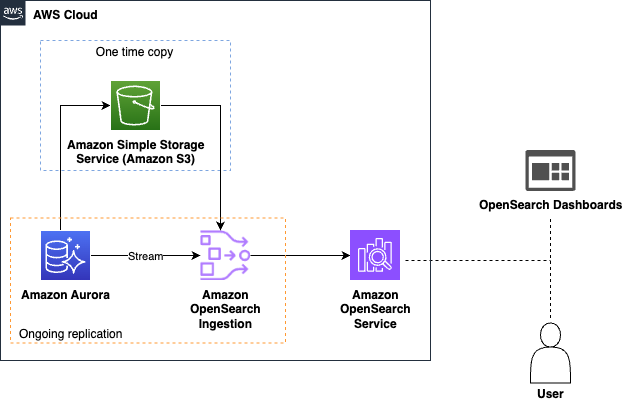
- Knowledge ingestion – OpenSearch Ingestion first hundreds your database snapshot from Amazon Easy Storage Service (Amazon S3), the place Aurora or Amazon RDS has exported the preliminary information. It then makes use of Aurora or Amazon RDS change information seize (CDC) streams to copy additional adjustments in close to actual time and indexes them into OpenSearch Service. This automated course of retains your information is constantly updated in OpenSearch, making it available for search and evaluation with out guide intervention.
- Actual-time querying – OpenSearch Service presents highly effective question capabilities that allow you to carry out advanced searches and aggregations in your information. Whether or not you must analyze tendencies, detect anomalies, or carry out search queries to return related outcomes on your utility, OpenSearch Service supplies the instruments you want.
The next diagram illustrates the answer structure for Amazon Aurora as a supply:
Getting Began
Configuring Your Database Supply
Earlier than organising synchronization, you must configure your supply database’s logging settings. For Aurora MySQL, configure your cluster parameter group with enhanced binary log settings. For Amazon RDS, allow primary binary logging or logical replication via your occasion parameter group settings. These logging configurations allow OpenSearch Ingestion to seize and replicate information adjustments out of your database.
The pattern HR database with Aurora MySQL is an effective instance to point out how this integration works.
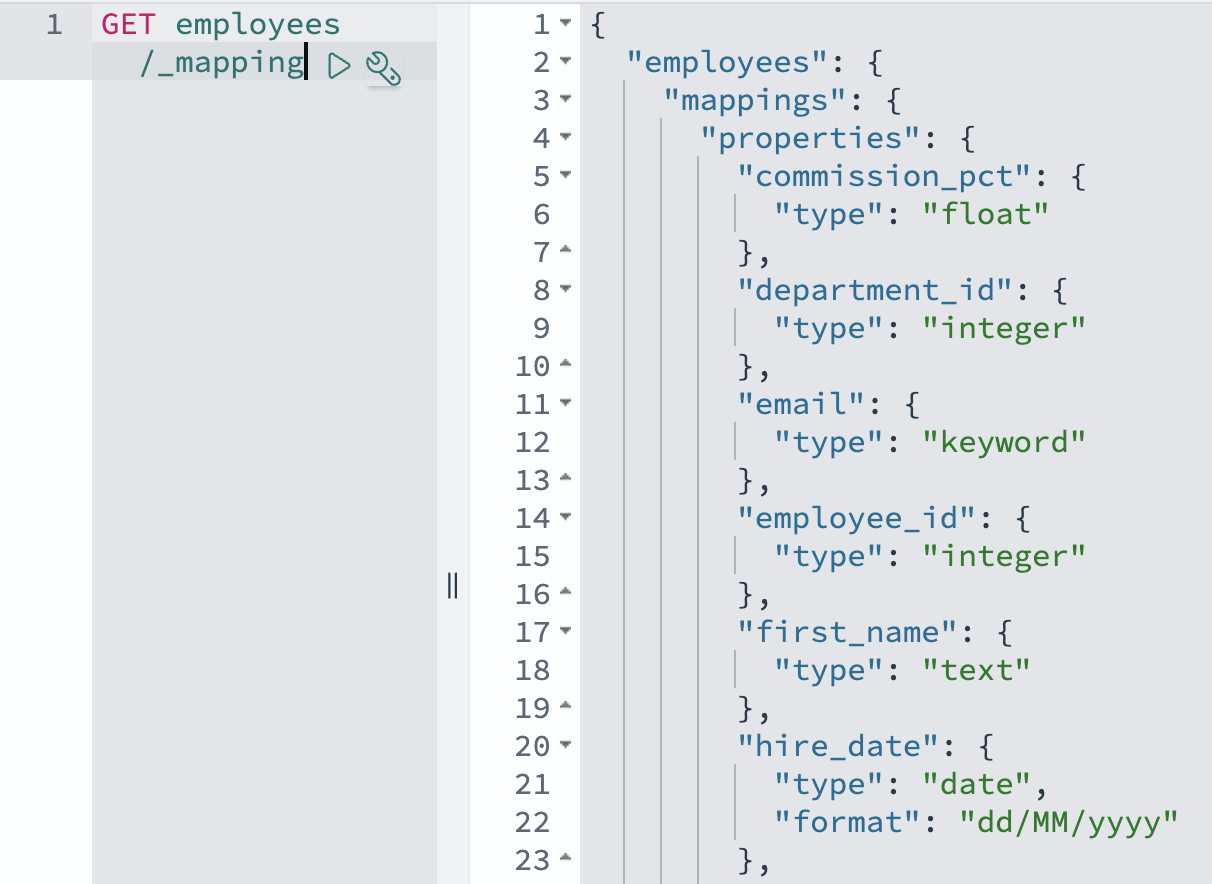
Earlier than creating the view, we now clarify how OpenSearch will symbolize this information. OpenSearch mappings outline how paperwork and their fields are saved and listed, much like how a database schema defines tables and columns. The OpenSearch Ingestion pipeline makes use of dynamic mappings by default, robotically changing Aurora or Amazon RDS information varieties to acceptable OpenSearch subject varieties. For instance, database DATE fields turn out to be OpenSearch date varieties, and numeric fields are mapped to corresponding OpenSearch numeric varieties. Though you possibly can customise these mappings utilizing index templates, the default mappings sometimes deal with widespread information varieties accurately, together with dates, numbers, and textual content fields.
GET staff/_mapping
To reveal the combination’s means to deal with advanced information relationships, we now study how OpenSearch Ingestion handles joined information. We create a view within the pattern HR database that mixes info from a number of associated tables right into a single, searchable doc in OpenSearch. This method reveals how one can rework normalized database buildings into denormalized paperwork which can be optimized for search operations.
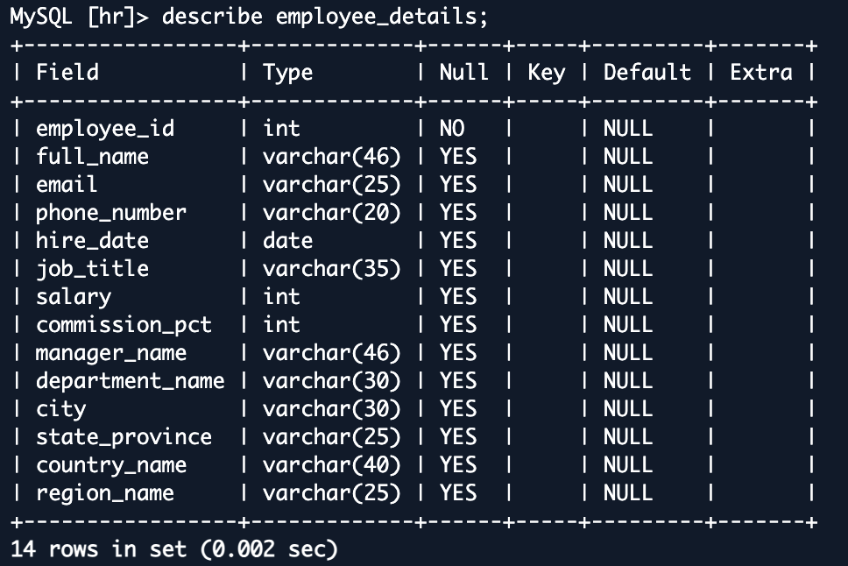
This employee_details view combines information from a number of tables, making a wealthy, denormalized illustration of worker info. When replicated to OpenSearch, this view turns into a single, complete doc for every worker. This construction is good for search operations, permitting for quick and complicated queries throughout what have been initially separate tables. For instance, you may simply seek for staff in a particular division and nation or analyze wage distributions throughout areas—queries that may be extra advanced and probably slower within the unique normalized database construction.
Within the pipeline configuration proven within the following screenshot, you possibly can verify how OpenSearch Ingestion connects to the HR database. The configuration identifies the supply database and the precise tables we need to replicate. Whereas we created a view to grasp the information relationships, the pipeline tracks adjustments from the underlying base tables (staff, departments, areas, and areas). OpenSearch Ingestion robotically maintains these relationships, which implies that adjustments to those tables are correctly mirrored in your OpenSearch index, protecting your search information constant together with your supply database.
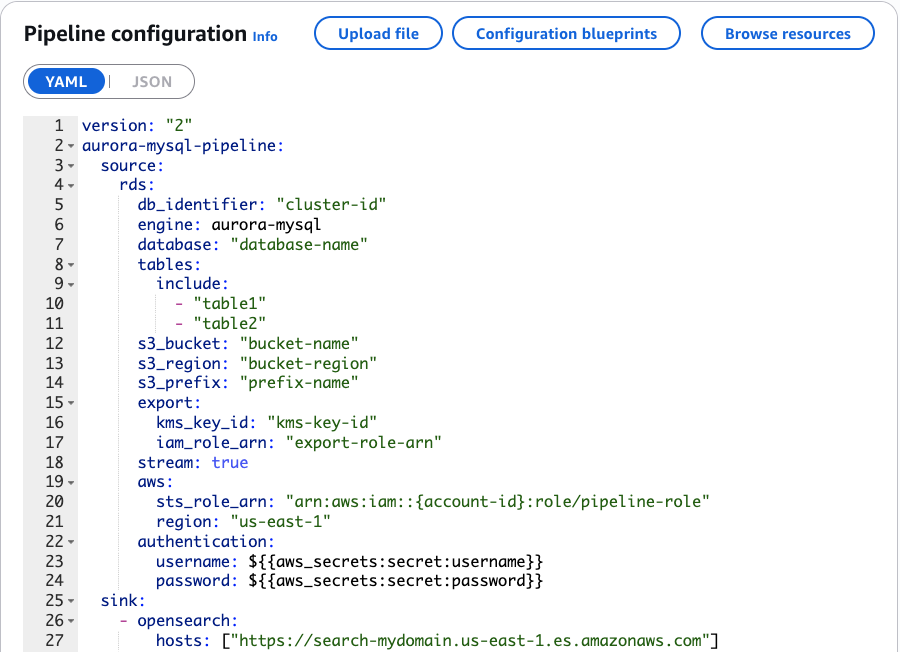
Within the gif proven under, you possibly can see a demo of organising this integration utilizing the visible editor of OpenSearch Ingestion.
You may as well specify index mapping templates to map your Aurora or Amazon RDS fields to the proper fields in your OpenSearch Service indexes.
For a complete overview of configuration settings for the pipeline, seek advice from the OpenSearch Knowledge Prepper documentation. You could arrange AWS Identification and Entry Administration (IAM) roles for the pipeline. For directions, seek advice from Configure the pipeline function.
After you configure the combination in OpenSearch Ingestion, the pipeline robotically creates indexes which you can view in OpenSearch Dashboards. OpenSearch Ingestion first triggers an automated export of your Aurora or Amazon RDS database to Amazon S3, then hundreds this snapshot information from S3 into your OpenSearch cluster to create the preliminary indices. After this preliminary load, OpenSearch Ingestion frequently captures adjustments utilizing binary logs (binlog) for MySQL-based databases or write-ahead logs (WAL) for PostgreSQL-based databases. This fashion, your OpenSearch indices keep synchronized together with your supply database in close to actual time. You may view your indices in OpenSearch Dashboards by invoking:
GET _cat/indices
Instance response:

Demonstrating close to actual time information synchronization
Take into account the primary 5 entries within the worker desk:

If you make adjustments to your database, OpenSearch Ingestion updates Amazon OpenSearch Service with the change information. For instance, the next code updates an worker’s wage:
UPDATE hr.staff SET SALARY = 26000 WHERE EMPLOYEE_ID = 100;

Amazon Aurora sends out a change discover, your OpenSearch Ingestion pipeline picks it up, and OpenSearch Ingestion sends the modified file to OpenSearch in close to actual time. You may confirm this with an OpenSearch question:
GET staff/_search
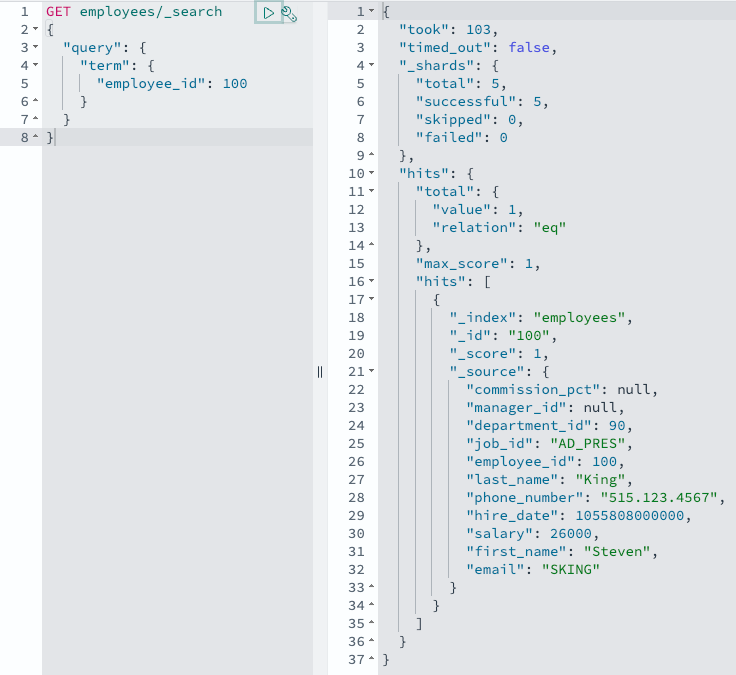
Essential particulars about this function:
- Monitoring – Monitor pipeline efficiency and information synchronization via CloudWatch metrics and the OpenSearch Ingestion dashboard
- Limitations – Requires same-Area and same-account deployment, main keys for optimum synchronization, and presently has no information definition language (DDL) assertion assist
Conclusion
Amazon Aurora or Amazon RDS integration with Amazon OpenSearch Service is now typically accessible in all AWS Areas the place OpenSearch Ingestion is offered.
To study extra, seek advice from the AWS documentation for Aurora or Amazon RDS integration with Amazon OpenSearch Service:
In regards to the authors
 Michael Torio is an Affiliate Specialist Options Architect at AWS targeted on Amazon OpenSearch Service primarily based out of Mountain View, CA. Michael enjoys serving to prospects leverage cloud applied sciences to resolve their enterprise challenges.
Michael Torio is an Affiliate Specialist Options Architect at AWS targeted on Amazon OpenSearch Service primarily based out of Mountain View, CA. Michael enjoys serving to prospects leverage cloud applied sciences to resolve their enterprise challenges.
 Sohaib Katariwala is a Senior Specialist Options Architect at AWS targeted on Amazon OpenSearch Service primarily based out of Chicago, IL. His pursuits are in all issues information and analytics. Extra particularly he loves to assist prospects use AI of their information technique to resolve modern-day challenges.
Sohaib Katariwala is a Senior Specialist Options Architect at AWS targeted on Amazon OpenSearch Service primarily based out of Chicago, IL. His pursuits are in all issues information and analytics. Extra particularly he loves to assist prospects use AI of their information technique to resolve modern-day challenges.
 Arjun Nambiar is a Product Supervisor with Amazon OpenSearch Service. He focuses on ingestion applied sciences that allow ingesting information from all kinds of sources into Amazon OpenSearch Service at scale. Arjun is occupied with large-scale distributed techniques and cloud-centered applied sciences, and relies out of Seattle, Washington.
Arjun Nambiar is a Product Supervisor with Amazon OpenSearch Service. He focuses on ingestion applied sciences that allow ingesting information from all kinds of sources into Amazon OpenSearch Service at scale. Arjun is occupied with large-scale distributed techniques and cloud-centered applied sciences, and relies out of Seattle, Washington.