

{kind=link}

(Summit Artwork Creations/Shutterstock)
Firms have lengthy dreamed of a single knowledge platform that may deal with their real-time and batch knowledge and workloads, with out some clunky interface in between. Nevertheless, until your identify is Uber or Netflix, you in all probability don’t have the engineering sources to construct a contemporary Lambda structure your self.
When he was an engineer at Confluent, Hojjat Jafarpour took a shot at making a system that moved the ball ahead on Apache co-creator Jay Kreps’ dream of a Kappa structure that solved the Lambda dilemma by reimagining every part as a stream. The consequence was the 2017 launch of kSQL, which offered a SQL interface atop knowledge flowing by way of Kafka. By itself, kSQL didn’t create a Kappa structure, however it stuffed an necessary hole.
Whereas kSQL simplified plenty of issues, it nonetheless had its limitations, mentioned Jafarpour, who was the engineering lead on the kSQL venture. For starters, it was tightly coupled to Kafka itself. For those who wished to learn and write to different streaming knowledge platforms, akin to AWS’s Amazon Kinesis, then you definately had been again to doing software program engineering and integrating a number of distributed techniques, which is difficult.
After transferring up right into a extra customer-facing position at Confluent, Jafarpour gained a brand new understanding of the forms of issues that prospects and prospects actually wished out of their knowledge infrastructure. When it got here to getting worth out of real-time processing techniques, real-world firms continued to precise frustration with the continued expense and complexity that it entailed.

DeltaStream Founder and CEO Hojjat Jafarpour
That’s what motivated Jafarpour to leap ship in 2020 and located his personal firm, known as DeltaStream. Jafarpour wasn’t prepared to surrender on SQL or Kafka, however as an alternative he wished to construct a greater abstraction for a stream processing product that rode atop present Kafka and Kinesis pipelines on the market.
To information improvement at DeltaStream, Jafarpour took his inspiration from Snowflake, which managed to offer a really clear interface for its refined cloud knowledge warehouse.
“We wish to make it tremendous easy so that you can use it, take away all the complexity of operations and infrastructure, and also you simply come and use it and get worth out of your knowledge,” Jafarpour informed BigDATAwire on the current Snowflake convention. “The concept was to construct one thing related on your streaming knowledge.”
As an alternative of reinventing the wheel, Jafarpour determined to construct DeltaStream atop the perfect stream processing engine that existed available in the market: Apache Flink.
“We get the facility of Flink, however we summary the complexity of that from the person,” Jafarpour mentioned. “So the person doesn’t should cope with the complexity, however they might be capable to get the scalability, elasticity and all the issues that Flink brings.”
Jafarpour noticed that one of the frequent use circumstances for Flink deployments is to course of fast-moving knowledge to make sure that downstream dashboards, purposes, and user-facing analytics are saved up-to-date with the freshest knowledge potential. That usually meant taking streaming knowledge and loading knowledge into some kind of analytics database, the place it may be consumed as a materialized view.
“Lots of use circumstances individuals would run Flink with one thing like Postgres, Clickhouse, or Pinot, and once more, you may have two completely different techniques to handle,” Jafarpour mentioned. “As I mentioned, we wished to construct an entire knowledge platform for streaming knowledge. We noticed that plenty of streaming use circumstances want that materialized view use case. Why not make it as a part of the platform?”![]()
So along with Apache Flink, DeltaStream additionally incorporates an OLAP database as a part of the providing. Clients are given the choice of utilizing both open supply Clickhouse or Postgres to construct materialized views to serve downstream real-time analytics use circumstances.
“The great factor is that we’re a cloud service, so underneath the hood we are able to usher in these elements and put them collectively with out prospects having to fret about it,” Jafarpour mentioned.
DeltaStream, which raised $10 million in 2022, has been adopted by organizations that must ingest massive quantities of incoming knowledge, from IoT sources or change knowledge seize (CDC) logs. The corporate has prospects in gaming, safety, and monetary providers, mentioned Jafarpour, who beforehand was an engineer at Informatica and Quantcast and has a PhD in pc science.
Earlier this month, the Menlo Park, California firm rolled out the subsequent iteration of the product: DeltaStream Fusion. The brand new version provides prospects the flexibility to land knowledge into Apache Iceberg tables, after which run queries towards these Iceberg tables.
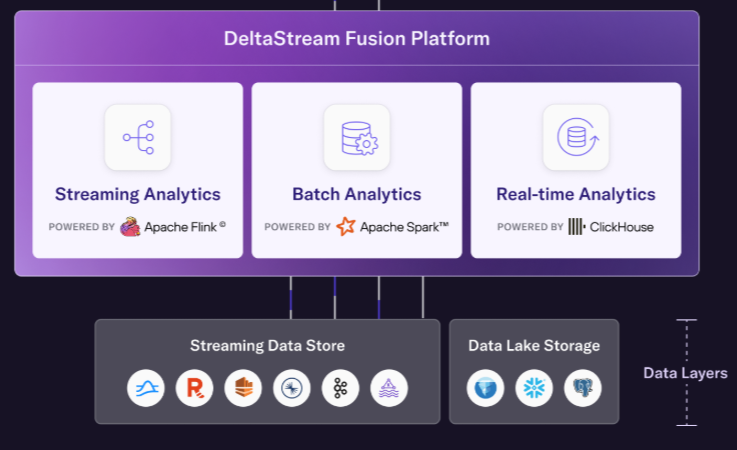
DeltaStream Fusion makes use of Flink, Spark, and Clickhouse for streaming, batch, and real-time use circumstances
To energy DeltaStream Fusion, Jafarpour surveyed the varied open supply engines out there in the marketplace, and picked the one he thought was finest fitted for the job: Apache Spark.
“Spark is the correct instrument for batch. Flink is nice for streaming, despite the fact that each of them wish to do the opposite facet,” Jafarpour mentioned. “The great factor is that we abstracted it from the person. If it’s a streaming question, it’s going to compile right into a Flink job. If it’s a question for the Iceberg tables, it’s going to make use of Spark for working that question.”
Sarcastically, Confluent itself would observe Jafarpour’s lead by adopting Flink. In 2023, it spent reported $100 million to purchase Immerok, one of many main firms behind Apache Flink into its choices. The corporate hasn’t utterly deserted kSQL (now known as ksqlDB), however it’s clear that Flink is the strategic stream processing engine at Confluent immediately. Databricks has additionally moved to assist Flink inside Delta Lake.
Jafarpour is philosophical in regards to the transfer past kSQL.
“That was one of many first merchandise in that area, and often once you construct a product the primary time, you make plenty of selections that a few of them are good, a few of them are unhealthy, relying on the scenario,” he mentioned. “And as I mentioned, as you construct issues and as you see how persons are utilizing it, you’re going to see the shortcomings and energy of the product. My conclusion was that, okay, it’s time for the subsequent technology of those techniques.”
Associated Objects:
Slicing and Dicing the Actual-Time Analytics Database Market
Confluent Expands Apache Flink Capabilities to Simplify AI and Stream Processing
5 Drivers Behind the Fast Rise of Apache Flink