

{kind=link}
Understanding implicit which means is a elementary side of human communication. But, present Pure Language Inference (NLI) fashions wrestle to acknowledge implied entailments—statements which can be logically inferred however not explicitly acknowledged. Most present NLI datasets are targeted on express entailments, making the fashions insufficiently outfitted to cope with eventualities the place which means is not directly expressed. This limitation bars the event of functions equivalent to conversational AI, summarization, and context-sensitive decision-making, the place the flexibility to deduce unstated implications is essential. To mitigate this shortcoming, a dataset and method that systematically incorporates implied entailments in NLI duties are wanted.
Present NLI benchmarks like SNLI, MNLI, ANLI, and WANLI are largely dominated by express entailments, with implied entailments making up a negligible proportion of the dataset. Subsequently, state-of-the-art fashions educated on these datasets are likely to mislabel implied entailments as impartial or contradictory. Earlier efforts in introducing an understanding of implicature have been targeted on structured inputs like oblique question-answering or pre-defined logical relations, which don’t generalize to free-form reasoning settings. Even giant fashions like GPT-4 exhibit a big efficiency hole between express and implicit entailment detection, which requires a extra complete method.
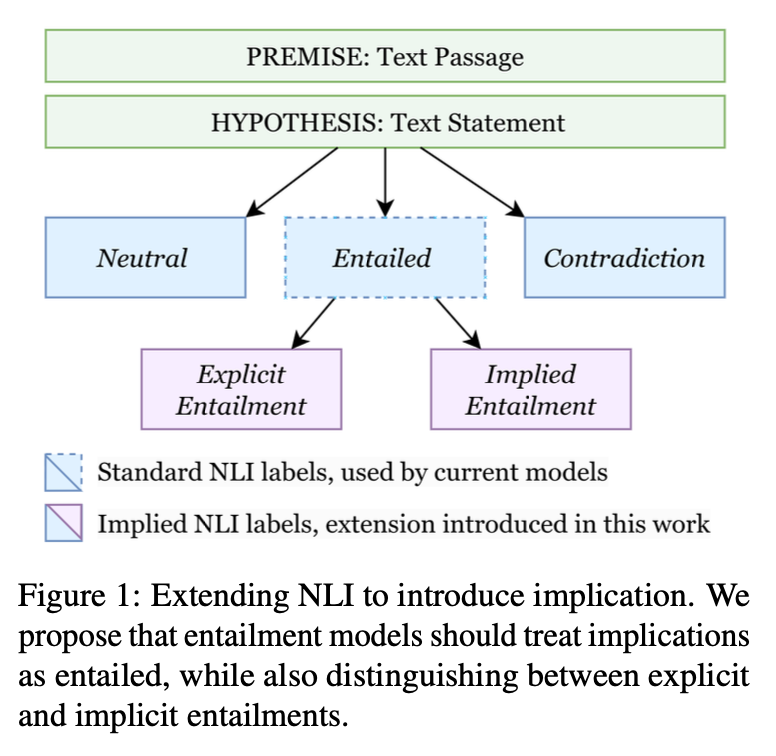
Google Deepmind and College of Pennsylvania researchers have proposed the Implied NLI (INLI) dataset to bridge the hole between the express and implicit entailments in pure language inference (NLI) fashions. Their paper proposes a scientific methodology of incorporating implied which means in NLI coaching utilizing structured implicature frameworks from present datasets equivalent to LUDWIG, CIRCA, NORMBANK, and SOCIALCHEM to rework these frameworks into pairs of ⟨premise, implied entailment⟩. As well as, every premise can also be paired with express entailments, impartial hypotheses, and contradictions to create an inclusive dataset for mannequin coaching. A groundbreaking few-shot prompting methodology utilizing Gemini-Professional ensures the era of high-quality implicit entailments whereas, concurrently, lowering annotation bills and making certain information integrity. Incorporating implicit which means in NLI duties permits the differentiation between express and implicit entailments by fashions with larger precision.
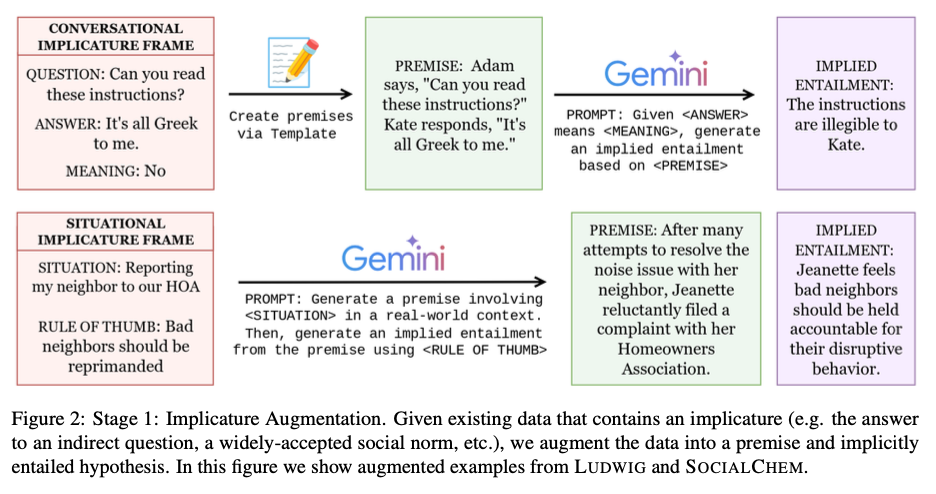

The creation of the INLI dataset is a two-stage process. First, present structured datasets with implicatures equivalent to oblique replies and social norms are restructured into an ⟨implied entailment, premise⟩ format. In stage two, to make sure the power of the dataset, express entailments, impartial statements, and contradictions are generated via managed manipulation of the implied entailments. The dataset contains 40,000 hypotheses (implied, express, impartial, and contradictory) for 10,000 premises, providing a various and balanced coaching set. Advantageous-tuning experiments utilizing T5-XXL fashions make use of a variety of studying charges (1e-6, 5e-6, 1e-5) over 50,000 coaching steps to enhance the identification of implicit entailments.
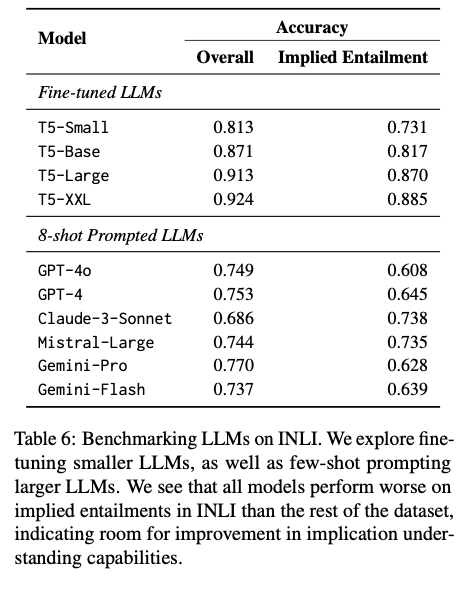
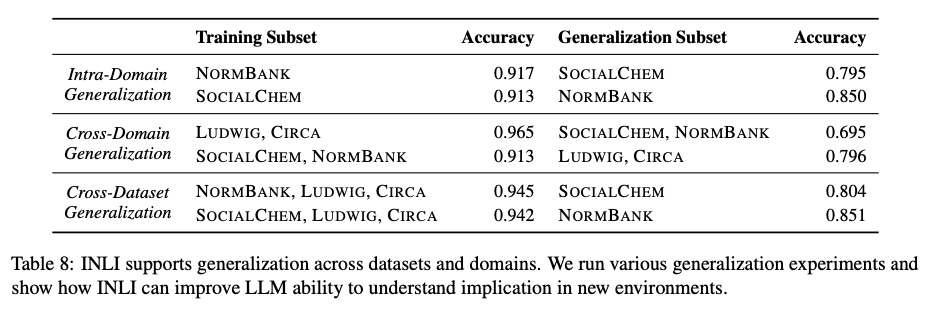
Fashions fine-tuned on INLI present a dramatic enchancment in detecting implied entailments, with an optimum accuracy of 92.5% in comparison with 50–71% accuracy for fashions fine-tuned on typical NLI datasets. Advantageous-tuned fashions generalize nicely to unseen datasets with excessive accuracy, scoring 94.5% on NORMBANK and 80.4% on SOCIALCHEM, establishing the robustness of INLI on assorted domains. Moreover, hypothesis-only baselines show that fashions fine-tuned on INLI leverage each premise and speculation for inference, reducing the chance of shallow sample studying. These outcomes set up the robustness of INLI in bridging express and implicit entailments, and in flip, considerably bettering AI’s capability for refined human communication.
This paper makes vital contributions to NLI by proposing the Implied NLI (INLI) dataset, which systematically introduces implied which means to inference duties. Using structured implicature frames and various speculation era, this method improves mannequin accuracy for detecting implicit entailments and facilitates improved generalization throughout domains. With sturdy empirical proof to determine its robustness, INLI establishes a brand new benchmark for coaching AI fashions to establish implicit which means, resulting in extra nuanced and context-aware pure language understanding.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 70k+ ML SubReddit.
🚨 Meet IntellAgent: An Open-Supply Multi-Agent Framework to Consider Advanced Conversational AI System (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.