

{kind=link}
Forecasting fashions are essential for a lot of companies to foretell future developments, however their accuracy relies upon closely on the standard of the enter information. Poor high quality information can result in inaccurate forecasts that end in suboptimal selections. That is the place Databricks Lakehouse Monitoring is available in – it gives a unified resolution to watch each the standard of knowledge flowing into forecasting fashions in addition to the mannequin efficiency itself.
Monitoring is very essential for forecasting fashions. Forecasting offers with time sequence information, the place the temporal part and sequential nature of the information introduce further complexities. Points like information drift, the place the statistical properties of the enter information change over time, can considerably degrade forecast accuracy if not detected and addressed promptly.
Moreover, the efficiency of forecasting fashions is commonly measured by metrics like Imply Absolute Share Error (MAPE) that examine predictions to precise values. Nonetheless, floor reality values will not be instantly accessible, solely arriving after the forecasted time interval has handed. This delayed suggestions loop makes proactive monitoring of enter information high quality and mannequin outputs much more essential to establish potential points early.
Frequent retraining of statistical forecasting fashions utilizing latest information is frequent, however monitoring stays worthwhile to detect drift early and keep away from pointless computational prices. For complicated fashions like PatchTST, which use deep studying and require GPUs, retraining could also be much less frequent resulting from useful resource constraints, making monitoring much more essential.
With computerized hyperparameter tuning, you may introduce skew and inconsistent mannequin efficiency throughout runs. Monitoring helps you shortly establish when a mannequin’s efficiency has degraded and take corrective motion, comparable to manually adjusting the hyperparameters or investigating the enter information for anomalies. Moreover, monitoring may help you strike the precise stability between mannequin efficiency and computational price. Auto-tuning could be resource-intensive, particularly if it is blindly working on each retraining cycle. By monitoring the mannequin’s efficiency over time, you may decide if the auto-tuning is definitely yielding important enhancements or if it is simply including pointless overhead. This perception permits you to optimize your mannequin coaching pipeline.
Databricks Lakehouse Monitoring is constructed to watch the statistical properties and high quality of knowledge throughout all tables, but it surely additionally contains particular capabilities tailor-made for monitoring the efficiency of machine studying fashions through monitoring inference tables containing mannequin inputs and predictions. For forecasting fashions, this enables:
- Monitoring information drift in enter options over time, evaluating to a baseline
- Monitoring prediction drift and distribution of forecasts
- Measuring mannequin efficiency metrics like MAPE, bias, and so on as actuals develop into accessible
- Setting alerts if information high quality or mannequin efficiency degrades
Creating Forecasting Fashions on Databricks
Earlier than we focus on easy methods to monitor forecasting fashions, let’s briefly cowl easy methods to develop them on the Databricks platform. Databricks gives a unified setting to construct, prepare, and deploy machine studying fashions at scale, together with time sequence forecasting fashions.
There are a number of in style libraries and methods you should utilize to generate forecasts, comparable to:
- Prophet: An open-source library for time sequence forecasting that’s straightforward to make use of and tune. It excels at dealing with information with sturdy seasonal results and works effectively with messy information by smoothing out outliers. Prophet’s easy, intuitive API makes it accessible to non-experts. You need to use PySpark to parallelize Prophet mannequin coaching throughout a cluster to construct 1000’s of fashions for every product-store mixture. Weblog
- ARIMA/SARIMA: Traditional statistical strategies for time sequence forecasting. ARIMA fashions intention to explain the autocorrelations within the information. SARIMA extends ARIMA to mannequin seasonality. In a latest benchmarking research, SARIMA demonstrated sturdy efficiency on retail gross sales information in comparison with different algorithms. Weblog
Along with in style libraries like Prophet and ARIMA/SARIMA for producing forecasts, Databricks additionally gives AutoML for Forecasting. AutoML simplifies the method of making forecasting fashions by robotically dealing with duties like algorithm choice, hyperparameter tuning, and distributed coaching. With AutoML, you may:
- Shortly generate baseline forecasting fashions and notebooks by a user-friendly UI
- Leverage a number of algorithms like Prophet and Auto-ARIMA below the hood
- Robotically deal with information preparation, mannequin coaching and tuning, and distributed computation with Spark
You’ll be able to simply combine fashions created utilizing AutoML with MLflow for experiment monitoring and Databricks Mannequin Serving for deployment and monitoring. The generated notebooks present code that may be personalized and included into manufacturing workflows.
To streamline the mannequin growth workflow, you may leverage MLflow, an open-source platform for the machine studying lifecycle. MLflow helps Prophet, ARIMA and different fashions out-of-the-box to allow experiment monitoring which is good for time sequence experiments, permitting for the logging of parameters, metrics, and artifacts. Whereas this simplifies mannequin deployment and promotes reproducibility, utilizing MLflow is elective for Lakehouse Monitoring – you may deploy fashions with out it and Lakehouse Monitoring will nonetheless have the ability to observe them.
Upon getting a skilled forecasting mannequin, you will have flexibility in the way you deploy it for inference relying in your use case. For real-time forecasting, you should utilize Databricks Mannequin Serving to deploy the mannequin as a low-latency REST endpoint with only a few traces of code. When a mannequin is deployed for real-time inference, Databricks robotically logs the enter options and predictions to a managed Delta desk known as an inference log desk. This desk serves as the muse for monitoring the mannequin in manufacturing utilizing Lakehouse Monitoring.
Nonetheless, forecasting fashions are sometimes utilized in batch scoring situations, the place predictions are generated on a schedule (e.g. producing forecasts each evening for the following day). On this case, you may construct a separate pipeline that scores the mannequin on a batch of knowledge and logs the outcomes to a Delta desk. It is less expensive to load the mannequin instantly in your Databricks cluster and rating the batch of knowledge there. This strategy avoids the overhead of deploying the mannequin behind an API and paying for compute sources in a number of locations. The logged desk of batch predictions can nonetheless be monitored utilizing Lakehouse Monitoring in the identical approach as a real-time inference desk.
When you do require each real-time and batch inference to your forecasting mannequin, you may think about using Mannequin Serving for the real-time use case and loading the mannequin instantly on a cluster for batch scoring. This hybrid strategy optimizes prices whereas nonetheless offering the mandatory performance. You’ll be able to leverage Lakeview dashboards to construct interactive visualizations and share insights in your forecasting studies. You may as well arrange e mail subscriptions to robotically ship out dashboard snapshots on a schedule.
Whichever strategy you select, by storing the mannequin inputs and outputs within the standardized Delta desk format, it turns into simple to watch information drift, observe prediction adjustments, and measure accuracy over time. This visibility is essential for sustaining a dependable forecasting pipeline in manufacturing.
Now that we have coated easy methods to construct and deploy time sequence forecasting fashions on Databricks, let’s dive into the important thing points of monitoring them with Lakehouse Monitoring.
Monitor Knowledge Drift and Mannequin Efficiency
To make sure your forecasting mannequin continues to carry out effectively in manufacturing, it is essential to watch each the enter information and the mannequin predictions for potential points. Databricks Lakehouse Monitoring makes this straightforward by permitting you to create displays in your enter characteristic tables and inference log tables. Lakehouse Monitoring is constructed on prime of Unity Catalog as a unified strategy to govern and monitor your information, and requires Unity Catalog to be enabled in your workspace.
Create an Inference Profile Monitor
To watch a forecasting mannequin, create an inference profile monitor on the desk containing the mannequin’s enter options, predictions, and optionally, floor reality labels. You’ll be able to create the monitor utilizing both the Databricks UI or the Python API.
Within the UI, navigate to the inference desk and click on the “High quality” tab. Click on “Get began” and choose “Inference Profile” because the monitor sort. Then configure the next key parameters:
- Drawback Kind: Choose regression for forecasting fashions
- Timestamp Column: The column containing the timestamp of every prediction. It’s the timestamp of the inference, not the timestamp of the information itself.
- Prediction Column: The column containing the mannequin’s forecasted values
- Label Column (elective): The column containing the precise values. This may be populated later as actuals arrive.
- Mannequin ID Column: The column figuring out the mannequin model that made every prediction
- Granularities: The time home windows to mixture metrics over, e.g. every day or weekly
Optionally, you too can specify:
- A baseline desk containing reference information, just like the coaching set, to check information drift towards
- Slicing expressions to outline information subsets to watch, like completely different product classes
- Customized metrics to calculate, outlined by a SQL expression
- Arrange a refresh schedule
Utilizing the Python REST API, you may create an equal monitor with code like:
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import MonitorInferenceLog,
MonitorInferenceLogProblemType, MonitorMetric, MonitorMetricType
from pyspark.sql import varieties as T
w = WorkspaceClient()
w.quality_monitors.create(
table_name=f"{catalog}.{schema}.{table_name}",
inference_log=MonitorInferenceLog(
timestamp_col="ts",
model_id_col="model_version",
prediction_col="prediction",
label_col="precise",
problem_type=MonitorInferenceLogProblemType.PROBLEM_TYPE_REGRESSION,
granularities=["1 day", "1 week"]
),
output_schema_name=f"{catalog}.{schema}",
assets_dir= f"/Workspace/Customers/{user_email}/databricks_lakehouse
_monitoring/{catalog}.{schema}.{table_name}",
baseline_table="my_training_table",
slicing_exprs=["product_category"],
custom_metrics=[
MonitorMetric(
type=MonitorMetricType.CUSTOM_METRIC_TYPE_AGGREGATE,
name="pct_within_tolerance",
input_columns=[":table"],
definition="100.0 * sum(case when abs(prediction - precise) /
precise <= 0.1 then 1 else 0 finish) / depend(*)"
output_data_type=T.StructField("output", T.DoubleType()).json(),
),
MonitorMetric(
sort=MonitorMetricType.CUSTOM_METRIC_TYPE_AGGREGATE,
title="weighted_mae",
input_columns=[":table"],
definition="sum(abs(prediction - precise) * product_value) /
sum(product_value)"
output_data_type=T.StructField("output", T.DoubleType()).json(),
),
MonitorMetric(
sort=MonitorMetricType.CUSTOM_METRIC_TYPE_AGGREGATE,
title="qoq_pct_change",
input_columns=[":table"],
definition="""
(sum(case when extract(quarter from ts) = extract(quarter
from current_timestamp) and extract(yr from ts) = extract(
yr from current_timestamp) then precise else 0 finish) /
nullif(sum(case when extract(quarter from ts) = extract(
quarter from current_timestamp) - 1 and extract(yr from
ts) = extract(yr from current_timestamp) then precise else
0 finish), 0) - 1) * 100
"""
output_data_type=T.StructField("output", T.DoubleType()).json(),
),
]
)Baseline desk is an elective desk containing a reference dataset, like your mannequin’s coaching information, to check the manufacturing information towards. Once more, for forecasting fashions, they’re ceaselessly retrained, so the baseline comparability is commonly not crucial because the mannequin will ceaselessly change. Chances are you’ll do the comparability to a earlier time window and if baseline comparability is desired, solely replace the baseline when there’s a larger replace, like hyperparameter tuning or an replace to the actuals.
Monitoring in forecasting is beneficial even in situations the place the retraining cadence is pre-set, comparable to weekly or month-to-month. In these instances, you may nonetheless interact in exception-based forecast administration when forecast metrics deviate from actuals or when actuals fall out of line with forecasts. This lets you decide if the underlying time sequence must be re-diagnosed (the formal forecasting language for retraining, the place developments, seasonality, and cyclicity are individually recognized if utilizing econometric fashions) or if particular person deviations could be remoted as anomalies or outliers. Within the latter case, you would not re-diagnose, however mark the deviation as an outlier and doubtlessly connect a calendar occasion or an exogenous variable to the mannequin sooner or later.
Lakehouse Monitoring will robotically observe statistical properties of the enter options over time and alert if important drift is detected relative to the baseline or earlier time home windows. This lets you establish information high quality points that would degrade forecast accuracy. For instance:
- Monitor the distribution of key enter options like gross sales quantities. If there’s a sudden shift, it might point out information high quality points that will degrade forecast accuracy.
- Observe the variety of lacking or outlier values. A rise in lacking information for latest time durations might skew forecasts.
Along with the default metrics, you may outline customized metrics utilizing SQL expressions to seize business-specific logic or complicated comparisons. Some examples related to forecasting:
- Evaluating metrics throughout seasons or years, e.g. calculating the % distinction in common gross sales between the present quarter and the identical quarter final yr
- Weighting errors in a different way based mostly on the merchandise being forecasted, e.g. penalizing errors on high-value merchandise extra closely
- Monitoring the share of forecasts inside an appropriate error tolerance
Customized metrics could be of three varieties:
- Combination metrics calculated from columns within the inference desk
- Derived metrics calculated from different mixture metrics
- Drift metrics evaluating an mixture or derived metric throughout time home windows or to a baseline
Examples of those customized metrics are proven within the Python API instance above. By incorporating customized metrics tailor-made to your particular forecasting use case, you may achieve deeper, extra related insights into your mannequin’s efficiency and information high quality.
The important thing thought is to carry your mannequin’s enter options, predictions, and floor reality labels collectively in a single inference log desk. Lakehouse Monitoring will then robotically observe information drift, prediction drift, and efficiency metrics over time and by the scale you specify.
In case your forecasting mannequin is served exterior of Databricks, you may ETL the request logs right into a Delta desk after which apply monitoring on it. This lets you centralize monitoring even for exterior fashions.
It is essential to notice that once you first create a time sequence or inference profile monitor, it analyzes solely information from the 30 days previous to the monitor’s creation. As a result of this cutoff, the primary evaluation window is perhaps partial. For instance, if the 30-day restrict falls in the midst of per week or month, the total week or month won’t be included.
This 30-day lookback limitation solely impacts the preliminary window when the monitor is created. After that, all new information flowing into the inference desk will probably be absolutely processed in accordance with the required granularities.
Refresh Displays to Replace Metrics
After creating an inference profile monitor to your forecasting mannequin, you’ll want to periodically refresh it to replace the metrics with the most recent information. Refreshing a monitor recalculates the profile and drift metrics tables based mostly on the present contents of the inference log desk. It is best to refresh a monitor when:
- New predictions are logged from the mannequin
- Precise values are added for earlier predictions
- The inference desk schema adjustments, comparable to including a brand new characteristic column
- You modify the monitor settings, like including further customized metrics
There are two methods to refresh a monitor: on a schedule or manually.
To arrange a refresh schedule, specify the schedule parameter when creating the monitor utilizing the UI, or with the Python API:
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import MonitorInferenceLog,
MonitorInferenceLogProblemType, MonitorCronSchedule
w = WorkspaceClient()
w.quality_monitors.create(
table_name=f"{catalog}.{schema}.{table_name}",
inference_log=MonitorInferenceLog(...),
schedule=MonitorCronSchedule(quartz_cron_expression="0 0 * * *")
# every day at midnight
skip_builtin_dashboard=False # set to True if dashboard is
already created
output_schema_name=f"{catalog}.{schema}",
assets_dir= f"/Workspace/Customers/{user_email}/databricks_lakehouse
_monitoring/{catalog}.{schema}.{table_name}",
)The `CronSchedule` permits you to present a cron expression to outline the refresh frequency, comparable to every day, hourly, and so on. You’ll be able to set `skip_builtin_dashboard` to True, which is able to skip producing a brand new dashboard for the monitor. That is particularly helpful when you will have already constructed a dashboard or have customized charts within the dashboard you need to preserve and do not want a brand new one.
Alternatively, you may manually refresh a monitor utilizing the UI or Python API. Within the Databricks UI, go to the “High quality” tab on the inference desk, choose the monitor, and click on “Refresh metrics”.
Utilizing Python API, you may create a pipeline that refreshes a monitor in order that it is action-driven, for instance, after retraining a mannequin. To refresh a monitor in a pocket book, use the run_refresh perform:
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
w.quality_monitors.run_refresh(
table_name=f"{catalog}.{schema}.{table_name}"
)This submits a serverless job to replace the monitor metrics tables. You’ll be able to proceed to make use of the pocket book whereas the refresh runs within the background.
After a refresh completes, you may question the up to date profile and drift metrics tables utilizing SQL. Nonetheless, notice that the generated dashboard is up to date individually, which you are able to do so by clicking on the “Refresh” button within the DBSQL dashboard itself. Equally, once you click on Refresh on the dashboard, it does not set off monitor calculations. As an alternative, it runs the queries over the metric tables that the dashboard makes use of to generate visualizations. To replace the information within the tables used to create the visualizations that seem on the dashboard, it’s essential to refresh the monitor after which refresh the dashboard.
Understanding the Monitoring Output
Whenever you create an inference profile monitor to your forecasting mannequin, Lakehouse Monitoring generates a number of key belongings that will help you observe information drift, mannequin efficiency, and total well being of your pipeline.
Profile and Drift Metrics Tables
Lakehouse Monitoring creates two major metrics tables:
- Profile metrics desk: Comprises abstract statistics for every characteristic column and the predictions, grouped by time window and slice. For forecasting fashions, this contains metrics like:
- depend, imply, stddev, min, max for numeric columns
- depend, variety of nulls, variety of distinct values for categorical columns
- depend, imply, stddev, min, max for the prediction column
- Drift metrics desk: Tracks adjustments in information and prediction distributions over time in comparison with a baseline. Key drift metrics for forecasting embody:
- Wasserstein distance for numeric columns, measuring the distinction in distribution form, and for the prediction column, detecting shifts within the forecast distribution
- Jensen-Shannon divergence for categorical columns, quantifying the distinction between chance distributions
You’ll be able to question them instantly utilizing SQL to research particular questions, comparable to:
- What’s the common prediction and the way has it modified week-over-week?
- Is there a distinction in mannequin accuracy between product classes?
- What number of lacking values have been there in a key enter characteristic yesterday vs the coaching information?
Mannequin Efficiency Dashboard
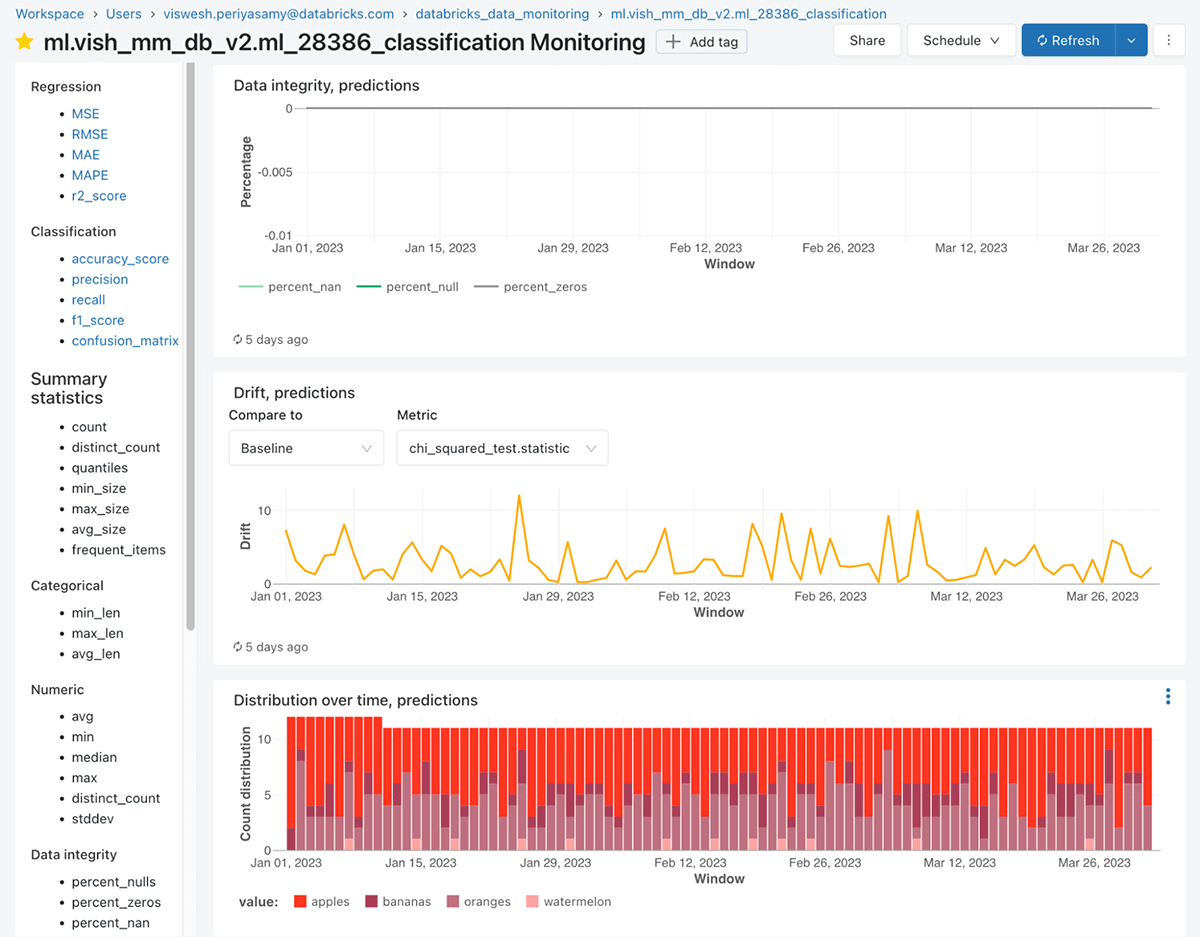
Along with the metrics tables, Lakehouse Monitoring robotically generates an interactive dashboard to visualise your forecasting mannequin’s efficiency over time. The dashboard contains a number of key parts:
- Mannequin Efficiency Panel: Shows key accuracy metrics to your forecasting mannequin, comparable to MAPE, RMSE, bias, and so on. These metrics are calculated by evaluating the predictions to the precise values, which could be supplied on a delay (e.g. every day actuals for a every day forecast). The panel exhibits the metrics over time and by essential slices like product class or area.
- Drift Metrics Panel: Visualizes the drift metrics for chosen options and the prediction column over time.
- Knowledge High quality Panel: Exhibits numerous metrics comparable to % of lacking values, % of nas, numerous statistics comparable to depend, imply, min and max, and different information anomalies for each numeric options and categorical options over time. This helps you shortly spot information high quality points that would degrade forecast accuracy.
The dashboard is extremely interactive, permitting you to filter by time vary, choose particular options and slices, and drill down into particular person metrics. The dashboard is commonly personalized after its creation to incorporate any views or charts your group is used to taking a look at. Queries which are used on the dashboard could be personalized and saved, and you’ll add alerts from any of the views by clicking on “view question” after which clicking on “create alert”. On the time of writing, a personalized template for the dashboard will not be supported.
It is a worthwhile software for each information scientists to debug mannequin efficiency and enterprise stakeholders to keep up belief within the forecasts.
Leveraging Actuals for Accuracy Monitoring
To calculate mannequin efficiency metrics like MAPE, the monitoring system wants entry to the precise values for every prediction. Nonetheless, with forecasting, actuals are sometimes not accessible till a while after the prediction is made.
One technique is to arrange a separate pipeline that appends the precise values to the inference log desk after they develop into accessible, then refresh the monitor to replace the metrics. For instance, when you generate every day forecasts, you might have a job that runs every evening so as to add the precise values for the day prior to this’s predictions.
By capturing actuals and refreshing the monitor frequently, you may observe forecast accuracy over time and establish efficiency degradation early. That is essential for sustaining belief in your forecasting pipeline and making knowledgeable enterprise selections.
Furthermore, monitoring actuals and forecasts individually permits highly effective exception administration capabilities. Exception administration is a well-liked approach in demand planning the place important deviations from anticipated outcomes are proactively recognized and resolved. By establishing alerts on metrics like forecast accuracy or bias, you may shortly spot when a mannequin’s efficiency has degraded and take corrective motion, comparable to adjusting mannequin parameters or investigating enter information anomalies.
Lakehouse Monitoring makes exception administration simple by robotically monitoring key metrics and offering customizable alerting. Planners can focus their consideration on essentially the most impactful exceptions slightly than sifting by mountains of knowledge. This focused strategy improves effectivity and helps preserve excessive forecast high quality with minimal handbook intervention.
In abstract, Lakehouse Monitoring gives a complete set of instruments for monitoring your forecasting fashions in manufacturing. By leveraging the generated metrics tables and dashboard, you may proactively detect information high quality points, observe mannequin efficiency, diagnose drift, and handle exceptions earlier than they affect your corporation. The power to slice and cube the metrics throughout dimensions like product, area, and time allows you to shortly pinpoint the basis explanation for any points and take focused motion to keep up the well being and accuracy of your forecasts.
Set Alerts on Mannequin Metrics
Upon getting an inference profile monitor arrange to your forecasting mannequin, you may outline alerts on key metrics to proactively establish points earlier than they affect enterprise selections. Databricks Lakehouse Monitoring integrates with Databricks SQL to help you create alerts based mostly on the generated profile and drift metrics tables.
Some frequent situations the place you’ll need to arrange alerts for a forecasting mannequin embody:
- Alert if the rolling 7-day common prediction error (MAPE) exceeds 10%. This might point out the mannequin is not correct and might have retraining.
- Alert if the variety of lacking values in a key enter characteristic has elevated considerably in comparison with the coaching information. Lacking information might skew predictions.
- Alert if the distribution of a characteristic has drifted past a threshold relative to the baseline. This might sign an information high quality concern or that the mannequin must be up to date for the brand new information patterns.
- Alert if no new predictions have been logged previously 24 hours. This might imply the inference pipeline has failed and wishes consideration.
- Alert if the mannequin bias (imply error) is persistently optimistic or damaging. This might point out the mannequin is systematically over or below forecasting.
There are built-in queries already generated to construct the views of the dashboard. To create an alert, navigate to the SQL question that calculates the metric you need to monitor from the profile or drift metrics desk. Then, within the Databricks SQL question editor, click on “Create Alert” and configure the alert situations, comparable to triggering when the MAPE exceeds 0.1. You’ll be able to set the alert to run on a schedule, like hourly or every day, and specify easy methods to obtain notifications (e.g. e mail, Slack, PagerDuty).
Along with alerts on the default metrics, you may write customized SQL queries to calculate bespoke metrics to your particular use case. For instance, possibly you need to alert if the MAPE for high-value merchandise exceeds a distinct threshold than for low-value merchandise. You might be a part of the profile metrics with a product desk to section the MAPE calculation.
The secret is that every one the characteristic and prediction information is accessible in metric tables, so you may flexibly compose SQL to outline customized metrics which are significant for your corporation. You’ll be able to then create alerts on prime of those customized metrics utilizing the identical course of.
By establishing focused alerts in your forecasting mannequin metrics, you may preserve a pulse on its efficiency with out handbook monitoring. Alerts help you reply shortly to anomalies and preserve belief within the mannequin’s predictions. Mixed with the multi-dimensional evaluation enabled by Lakehouse Monitoring, you may effectively diagnose and resolve points to maintain your forecast high quality excessive.
Monitor Lakehouse Monitoring Bills
Whereas not particular to forecasting fashions, it is essential to know easy methods to observe your utilization and bills for Lakehouse Monitoring itself. When planning to make use of Lakehouse Monitoring, it is essential to know the related prices so you may price range appropriately. Lakehouse Monitoring jobs run on serverless compute infrastructure, so you do not have to handle clusters your self. To estimate your Lakehouse Monitoring prices, comply with these steps:
- Decide the quantity and frequency of displays you intend to create. Every monitor will run on a schedule to refresh the metrics.
- Estimate the information quantity and complexity of the SQL expressions to your displays. Bigger information sizes and extra complicated queries will devour extra DBUs.
- Lookup the DBU fee for serverless workloads based mostly in your Databricks tier and cloud supplier.
- Multiply your estimated DBUs by the relevant fee to get your estimated Lakehouse Monitoring price.
Your precise prices will rely in your particular monitor definitions and information, which may differ over time. Databricks gives two methods to watch your Lakehouse Monitoring prices: utilizing a SQL question or the billing portal. Seek advice from https://docs.databricks.com/en/lakehouse-monitoring/expense.html for extra data.
Prepared to begin monitoring your forecasting fashions with Databricks Lakehouse Monitoring? Join a free trial to get began. Already a Databricks buyer? Try our documentation to arrange your first inference profile monitor as we speak.