

{kind=link}
Agentic AI Techniques are all the fashion nowadays! They’re merely LLMs in a for-loop linked with sure prompts and instruments which might autonomously do duties for you. Nonetheless, you too can construct dependable step-by-step workflows, guiding the LLM to be extra dependable because it solves issues for you. Lately in February 2025, OpenAI launched Deep Analysis, which is an agent which might take a consumer matter, mechanically run a bunch of searches and compile them into a pleasant report. Nonetheless, it’s only accessible of their 200$ professional plan. Right here I’ll present you a hands-on step-by-step information on the right way to construct your personal Deep Analysis and Report Era Agent for lower than a greenback utilizing LangGraph!
Temporary on Deep Analysis by OpenAI
OpenAI launched Deep Analysis on February 2, 2025, the place it has been launched as a further functionality of their ChatGPT product. They name this a brand new agentic functionality that may do multi-step analysis on the web for advanced duties or queries given by the consumer. What they declare is that it accomplishes in tens of minutes what would take a human many hours.

Deep analysis is OpenAI’s present Agentic AI product that may do give you the results you want autonomously. You give it a process or matter by way of a immediate, and ChatGPT will discover, analyze, and synthesize a whole bunch of on-line sources to create a complete report on the degree of a analysis analyst. Powered by a model of the upcoming OpenAI o3 mannequin that’s optimized for internet looking and information evaluation, it leverages reasoning to go looking, interpret, and analyze huge quantities of textual content, photos, and PDFs on the web, to lastly compile a pleasant structured report.
This does come nevertheless with some restrictions as you possibly can solely use it when you’ve got the 200$ ChatGPT professional subscription. That’s the place I are available in with my very own Agentic AI System which might do deep analysis and construct a pleasant compiled report in lower than a greenback. Let’s get began!
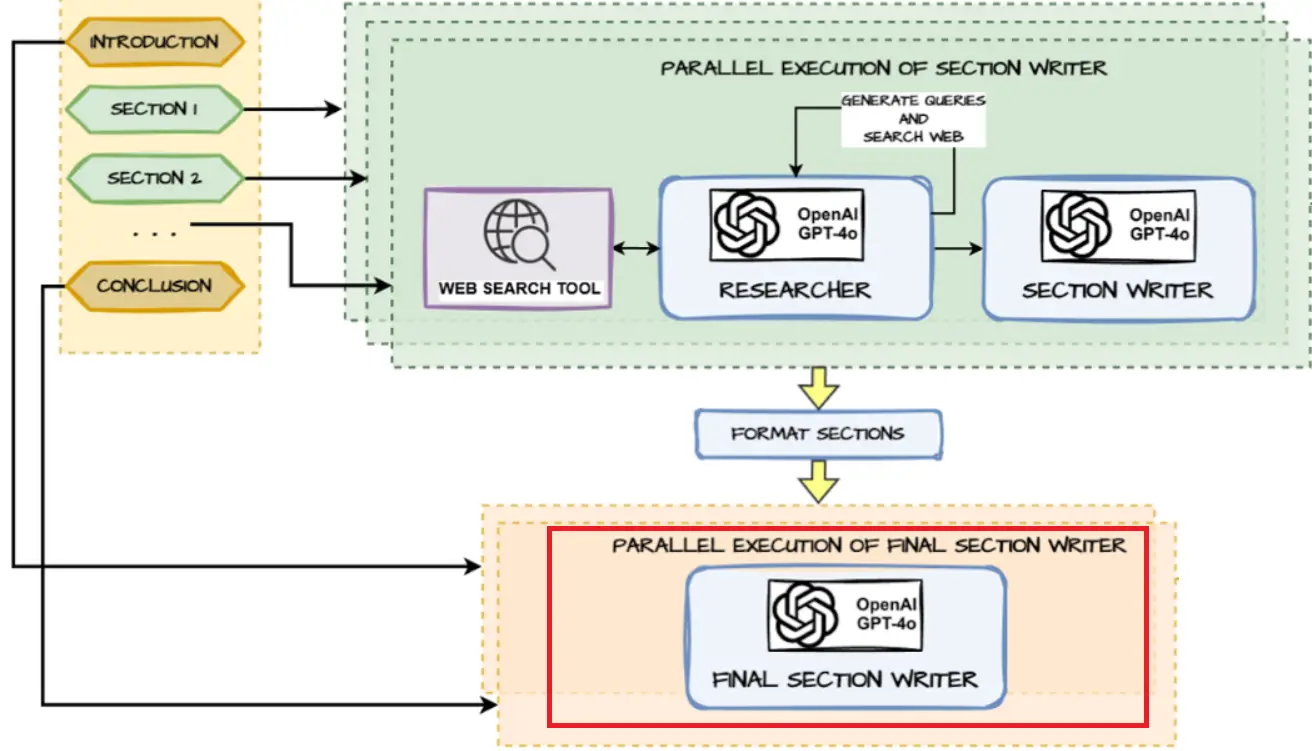
Deep Analysis & Structured Report Era Planning Agentic AI System Structure
The next determine exhibits the general structure of our system which we will probably be implementing with LangChain’s LangGraph open-source framework for constructing stateful agentic programs with ease and management.
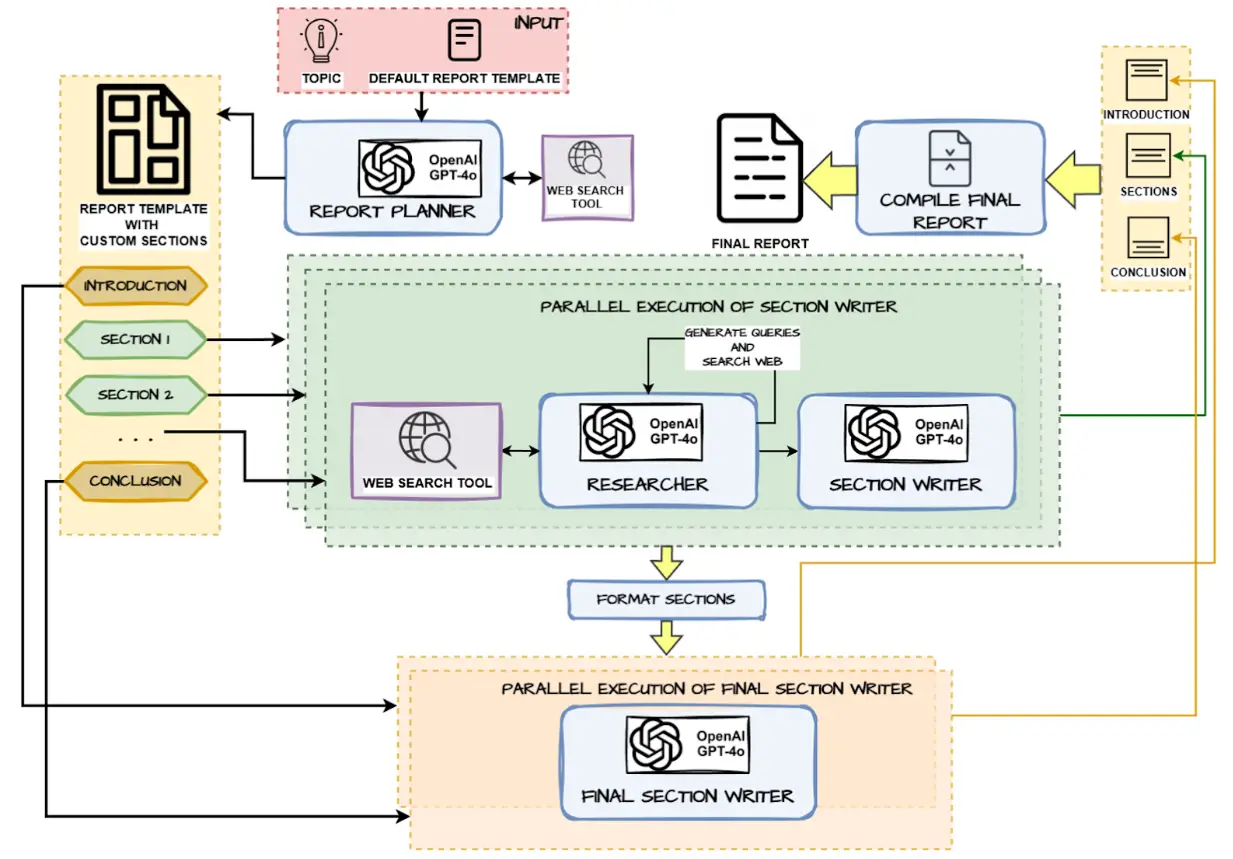
The important thing parts which is able to energy the above system embrace:
- A robust Giant Language Mannequin which is sweet in reasoning. We’re utilizing GPT-4o which isn’t tremendous costly and quick, nevertheless, you possibly can even use LLMs like Llama 3.2 or different open-source alternate options.
- LangGraph for constructing our agentic system because it is a wonderful framework for constructing cyclical graph-based programs which might keep state variables all through the workflow and assist construct agentic suggestions loops simply.
- Tavily AI is a wonderful AI-powered search engine, excellent for internet analysis and getting information from web sites to energy our Deep Analysis System.
This venture focuses on constructing a Planning Agent for Deep Analysis and Structured Report Era as an alternative choice to OpenAI’s Deep Analysis. The agent follows the favored Planning Agent Design Sample and automates the method of analyzing a user-defined matter, performing deep internet analysis, and producing a well-structured report. The workflow is definitely impressed by LangChain’s personal Report mAIstro so full credit score to them for arising with the workflow, I took that as my baseline inspiration after which constructed out this method, which consists of the next parts:
1. Report Planning:
- The agent analyzes the user-provided matter and default report template to create a customized plan for the report.
- Sections corresponding to Introduction, Key Sections, and Conclusion are outlined primarily based on the subject.
- A internet search device is used to gather the data required earlier than deciding on the principle sections.
2. Parallel Execution for Analysis and Writing:
- The agent makes use of parallel execution to effectively carry out:
- Net Analysis: Queries are generated for every part and executed by way of the net search device to retrieve up-to-date data.
- Part Writing: The retrieved information is used to write down content material for every part, with the next course of:
- The Researcher gathers related information from the net.
- The Part Author makes use of the information to generate structured content material for the assigned part.
3. Formatting Accomplished Sections:
- As soon as all sections are written, they’re formatted to make sure consistency and adherence to the report construction.
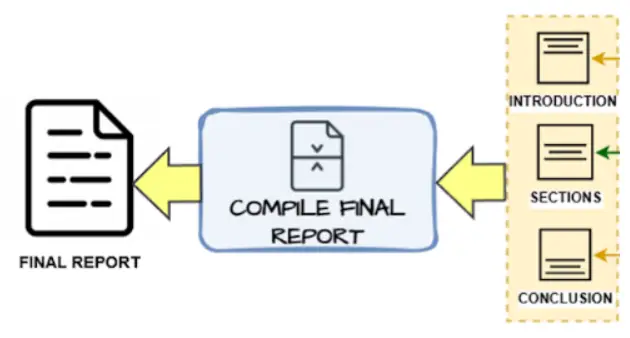
4. Introduction and Conclusion Writing:
- After the principle sections are accomplished and formatted:
- The Introduction and Conclusion are written primarily based on the content material of the remaining sections (in parallel)
- This course of ensures that these sections align with the general stream and insights of the report.
5. Last Compilation:
- All accomplished sections are compiled collectively to generate the ultimate report.
- The ultimate output is a complete and structured report within the type of Wiki docs.
Let’s now begin constructing out these parts step-by-step with LangGraph and Tavily.
Arms-on Implementation of our Deep Analysis & Structured Report Era Planning Agentic AI System
We’ll now implement the end-to-end workflow for our Deep Analysis Report Generator Agentic AI System primarily based on the structure we mentioned intimately within the earlier part step-by-step with detailed explanations, code and outputs.
Set up Dependencies
We begin by putting in the required dependencies that are going to be the libraries we will probably be utilizing to construct our system. This consists of langchain, LangGraph and likewise wealthy for producing good markdown studies.
!pip set up langchain==0.3.14
!pip set up langchain-openai==0.3.0
!pip set up langchain-community==0.3.14
!pip set up langgraph==0.2.64
!pip set up wealthyEnter Open AI API Key
We enter our Open AI key utilizing the getpass() operate so we don’t by chance expose our key within the code.
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')Enter Tavily Search API Key
We enter our Tavily Search key utilizing the getpass() operate so we don’t by chance expose our key within the code. You may get the important thing from right here they usually have a beneficiant free tier.
TAVILY_API_KEY = getpass('Enter Tavily Search API Key: ')Setup Atmosphere Variables
Subsequent, we arrange some system atmosphere variables which will probably be used later when authenticating our LLM and Tavily Search.
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
os.environ['TAVILY_API_KEY'] = TAVILY_API_KEYOutline Agent State Schema
We use LangGraph to construct our agentic system as a graph with nodes the place every node consists of a particular execution step within the general workflow. Every particular set of operations (nodes) can have their very own schema as outlined beneath. You may customise this additional primarily based by yourself type of report technology.
from typing_extensions import TypedDict
from pydantic import BaseModel, Area
import operator
from typing import Annotated, Checklist, Non-compulsory, Literal
# defines construction for every part within the report
class Part(BaseModel):
identify: str = Area(
description="Title for a selected part of the report.",
)
description: str = Area(
description="Temporary overview of the principle subjects and ideas to be coated on this part.",
)
analysis: bool = Area(
description="Whether or not to carry out internet seek for this part of the report."
)
content material: str = Area(
description="The content material for this part."
)
class Sections(BaseModel):
sections: Checklist[Section] = Area(
description="All of the Sections of the general report.",
)
# defines construction for queries generated for deep analysis
class SearchQuery(BaseModel):
search_query: str = Area(None, description="Question for internet search.")
class Queries(BaseModel):
queries: Checklist[SearchQuery] = Area(
description="Checklist of internet search queries.",
)
# consists of enter matter and output report generated
class ReportStateInput(TypedDict):
matter: str # Report matter
class ReportStateOutput(TypedDict):
final_report: str # Last report
# general agent state which will probably be handed and up to date in nodes within the graph
class ReportState(TypedDict):
matter: str # Report matter
sections: record[Section] # Checklist of report sections
completed_sections: Annotated[list, operator.add] # Ship() API
report_sections_from_research: str # accomplished sections to write down ultimate sections
final_report: str # Last report
# defines the important thing construction for sections written utilizing the agent
class SectionState(TypedDict):
part: Part # Report part
search_queries: record[SearchQuery] # Checklist of search queries
source_str: str # String of formatted supply content material from internet search
report_sections_from_research: str # accomplished sections to write down ultimate sections
completed_sections: record[Section] # Last key in outer state for Ship() API
class SectionOutputState(TypedDict):
completed_sections: record[Section] # Last key in outer state for Ship() APIUtility Capabilities
We outline a couple of utility capabilities which is able to assist us run parallel internet search queries and format outcomes obtained from the net.
1. run_search_queries(…)
This can asynchronously run Tavily search queries for a particular record of queries and return again the search outcomes. That is async so it’s non-blocking and will be executed in parallel.
from langchain_community.utilities.tavily_search import TavilySearchAPIWrapper
import asyncio
from dataclasses import asdict, dataclass
# simply to deal with objects created from LLM reponses
@dataclass
class SearchQuery:
search_query: str
def to_dict(self) -> Dict[str, Any]:
return asdict(self)
tavily_search = TavilySearchAPIWrapper()
async def run_search_queries(
search_queries: Checklist[Union[str, SearchQuery]],
num_results: int = 5,
include_raw_content: bool = False
) -> Checklist[Dict]:
search_tasks = []
for question in search_queries:
# Deal with each string and SearchQuery objects
# Simply in case LLM fails to generate queries as:
# class SearchQuery(BaseModel):
# search_query: str
query_str = question.search_query if isinstance(question, SearchQuery)
else str(question) # textual content question
strive:
# get outcomes from tavily async (in parallel) for every search question
search_tasks.append(
tavily_search.raw_results_async(
question=query_str,
max_results=num_results,
search_depth="superior",
include_answer=False,
include_raw_content=include_raw_content
)
)
besides Exception as e:
print(f"Error creating search process for question '{query_str}': {e}")
proceed
# Execute all searches concurrently and await outcomes
strive:
if not search_tasks:
return []
search_docs = await asyncio.collect(*search_tasks, return_exceptions=True)
# Filter out any exceptions from the outcomes
valid_results = [
doc for doc in search_docs
if not isinstance(doc, Exception)
]
return valid_results
besides Exception as e:
print(f"Error throughout search queries: {e}")
return []2. format_search_query_results(…)
This can extract the context from Tavily search outcomes, make sure that content material will not be duplicated from the identical URLs and format it to indicate the Supply, URL, and related content material (and optionally uncooked content material which will be truncated primarily based on the variety of tokens)
import tiktoken
from typing import Checklist, Dict, Union, Any
def format_search_query_results(
search_response: Union[Dict[str, Any], Checklist[Any]],
max_tokens: int = 2000,
include_raw_content: bool = False
) -> str:
encoding = tiktoken.encoding_for_model("gpt-4")
sources_list = []
# Deal with completely different response codecs if search outcomes is a dict
if isinstance(search_response, dict):
if 'outcomes' in search_response:
sources_list.prolong(search_response['results'])
else:
sources_list.append(search_response)
# if search outcomes is a listing
elif isinstance(search_response, record):
for response in search_response:
if isinstance(response, dict):
if 'outcomes' in response:
sources_list.prolong(response['results'])
else:
sources_list.append(response)
elif isinstance(response, record):
sources_list.prolong(response)
if not sources_list:
return "No search outcomes discovered."
# Deduplicate by URL and hold distinctive sources (web site urls)
unique_sources = {}
for supply in sources_list:
if isinstance(supply, dict) and 'url' in supply:
if supply['url'] not in unique_sources:
unique_sources[source['url']] = supply
# Format output
formatted_text = "Content material from internet search:nn"
for i, supply in enumerate(unique_sources.values(), 1):
formatted_text += f"Supply {supply.get('title', 'Untitled')}:n===n"
formatted_text += f"URL: {supply['url']}n===n"
formatted_text += f"Most related content material from supply: {supply.get('content material', 'No content material accessible')}n===n"
if include_raw_content:
# truncate uncooked webpage content material to a sure variety of tokens to forestall exceeding LLM max token window
raw_content = supply.get("raw_content", "")
if raw_content:
tokens = encoding.encode(raw_content)
truncated_tokens = tokens[:max_tokens]
truncated_content = encoding.decode(truncated_tokens)
formatted_text += f"Uncooked Content material: {truncated_content}nn"
return formatted_text.strip()We will check out these capabilities simply to see if it work as follows:
docs = await run_search_queries(['langgraph'], include_raw_content=True)
output = format_search_query_results(docs, max_tokens=500,
include_raw_content=True)
print(output)Output
Content material from internet search:Supply Introduction - GitHub Pages:
===
URL: https://langchain-ai.github.io/langgraphjs/
===
Most related content material from supply: Overview¶. LangGraph is a library for
constructing stateful, multi-actor purposes with LLMs, used to create agent
and multi-agent workflows......
===
Uncooked Content material: 🦜🕸️LangGraph.js¶
⚡ Constructing language brokers as graphs ⚡
On the lookout for the Python model? Click on
right here ( docs).
Overview......Supply ️LangGraph - GitHub Pages:
===
URL: https://langchain-ai.github.io/langgraph/
===
Most related content material from supply: Overview¶. LangGraph is a library for
constructing stateful, multi-actor purposes with LLMs, ......
===
Uncooked Content material: 🦜🕸️LangGraph¶
⚡ Constructing language brokers as graphs ⚡
Be aware
On the lookout for the JS model? See the JS repo and the JS docs.
Overview¶
LangGraph is a library for constructing
stateful, multi-actor purposes with LLMs, ......
Making a Default Report Template
That is the start line for the LLM to get an thought of the right way to construct a common report and it’ll use this as a suggestion to construct a customized report construction primarily based on the subject. Bear in mind this isn’t the ultimate report construction however extra of a immediate to information the agent.
# Construction Guideline
DEFAULT_REPORT_STRUCTURE = """The report construction ought to deal with breaking-down the user-provided matter
and constructing a complete report in markdown utilizing the next format:
1. Introduction (no internet search wanted)
- Temporary overview of the subject space
2. Principal Physique Sections:
- Every part ought to deal with a sub-topic of the user-provided matter
- Embrace any key ideas and definitions
- Present real-world examples or case research the place relevant
3. Conclusion (no internet search wanted)
- Goal for 1 structural component (both a listing of desk) that distills the principle physique sections
- Present a concise abstract of the report
When producing the ultimate response in markdown, if there are particular characters within the textual content,
such because the greenback image, guarantee they're escaped correctly for proper rendering e.g $25.5 ought to turn out to be $25.5
"""Instruction Prompts for Report Planner
There are two principal instruction prompts:
1. REPORT_PLAN_QUERY_GENERATOR_PROMPT
Helps the LLM to generate an preliminary record of questions primarily based on the subject to get extra data from the net about that matter in order that it may possibly plan the general sections and construction of the report
REPORT_PLAN_QUERY_GENERATOR_PROMPT = """You're an skilled technical report author, serving to to plan a report.
The report will probably be targeted on the next matter:
{matter}
The report construction will observe these tips:
{report_organization}
Your aim is to generate {number_of_queries} search queries that may assist collect complete data for planning the report sections.
The question ought to:
1. Be associated to the subject
2. Assist fulfill the necessities specified within the report group
Make the question particular sufficient to search out high-quality, related sources whereas masking the depth and breadth wanted for the report construction.
"""2. REPORT_PLAN_SECTION_GENERATOR_PROMPT
Right here we feed the LLM with the default report template, the subject identify and the search outcomes from the preliminary queries generated to create an in depth construction for the report. The LLM will generate a structured response of the next fields for every main part which will probably be within the report (that is simply the report construction – no content material is created at this step):
- Title – Title for this part of the report.
- Description – Temporary overview of the principle subjects and ideas to be coated on this part.
- Analysis – Whether or not to carry out internet seek for this part of the report or not.
- Content material – The content material of the part, which you’ll depart clean for now.
REPORT_PLAN_SECTION_GENERATOR_PROMPT = """You're an skilled technical report author, serving to to plan a report.
Your aim is to generate the define of the sections of the report.
The general matter of the report is:
{matter}
The report ought to observe this organizational construction:
{report_organization}
It's best to mirror on this extra context data from internet searches to plan the principle sections of the report:
{search_context}
Now, generate the sections of the report. Every part ought to have the next fields:
- Title - Title for this part of the report.
- Description - Temporary overview of the principle subjects and ideas to be coated on this part.
- Analysis - Whether or not to carry out internet seek for this part of the report or not.
- Content material - The content material of the part, which you'll depart clean for now.
Think about which sections require internet search.
For instance, introduction and conclusion is not going to require analysis as a result of they are going to distill data from different components of the report.
"""Node Perform for Report Planner
We’ll construct the logic for the report planner node which has the target of making a structured customized report template with main part names and descriptions primarily based on the enter consumer matter and the default report template tips.
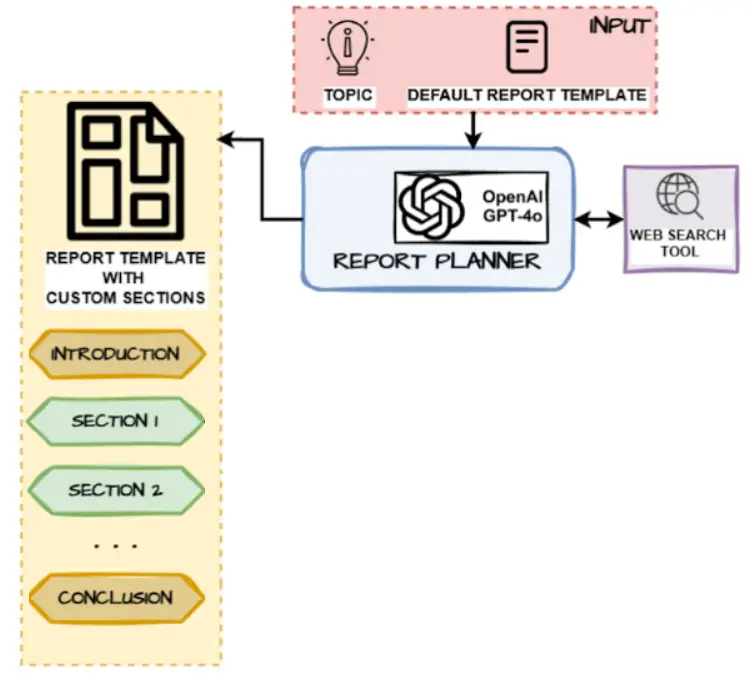
This operate makes use of the 2 prompts created earlier to:
- First, generate some queries primarily based on the consumer matter
- Search the net and get some data on these queries
- Use this data to generate the general construction of the report with the important thing sections essential to be created
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
llm = ChatOpenAI(model_name="gpt-4o", temperature=0)
async def generate_report_plan(state: ReportState):
"""Generate the general plan for constructing the report"""
matter = state["topic"]
print('--- Producing Report Plan ---')
report_structure = DEFAULT_REPORT_STRUCTURE
number_of_queries = 8
structured_llm = llm.with_structured_output(Queries)
system_instructions_query = REPORT_PLAN_QUERY_GENERATOR_PROMPT.format(
matter=matter,
report_organization=report_structure,
number_of_queries=number_of_queries
)
strive:
# Generate queries
outcomes = structured_llm.invoke([
SystemMessage(content=system_instructions_query),
HumanMessage(content="Generate search queries that will help with planning the sections of the report.")
])
# Convert SearchQuery objects to strings
query_list = [
query.search_query if isinstance(query, SearchQuery) else str(query)
for query in results.queries
]
# Search internet and guarantee we watch for outcomes
search_docs = await run_search_queries(
query_list,
num_results=5,
include_raw_content=False
)
if not search_docs:
print("Warning: No search outcomes returned")
search_context = "No search outcomes accessible."
else:
search_context = format_search_query_results(
search_docs,
include_raw_content=False
)
# Generate sections
system_instructions_sections = REPORT_PLAN_SECTION_GENERATOR_PROMPT.format(
matter=matter,
report_organization=report_structure,
search_context=search_context
)
structured_llm = llm.with_structured_output(Sections)
report_sections = structured_llm.invoke([
SystemMessage(content=system_instructions_sections),
HumanMessage(content="Generate the sections of the report. Your response must include a 'sections' field containing a list of sections. Each section must have: name, description, plan, research, and content fields.")
])
print('--- Producing Report Plan Accomplished ---')
return {"sections": report_sections.sections}
besides Exception as e:
print(f"Error in generate_report_plan: {e}")
return {"sections": []}Instruction Prompts for Part Builder – Question Generator
There may be one principal instruction immediate:
1. REPORT_SECTION_QUERY_GENERATOR_PROMPT
Helps the LLM to generate a complete record of questions for the subject of that particular part which must be constructed
REPORT_SECTION_QUERY_GENERATOR_PROMPT = """Your aim is to generate focused internet search queries that may collect complete data for writing a technical report part.
Subject for this part:
{section_topic}
When producing {number_of_queries} search queries, make sure that they:
1. Cowl completely different elements of the subject (e.g., core options, real-world purposes, technical structure)
2. Embrace particular technical phrases associated to the subject
3. Goal latest data by together with 12 months markers the place related (e.g., "2024")
4. Search for comparisons or differentiators from related applied sciences/approaches
5. Seek for each official documentation and sensible implementation examples
Your queries ought to be:
- Particular sufficient to keep away from generic outcomes
- Technical sufficient to seize detailed implementation data
- Various sufficient to cowl all elements of the part plan
- Centered on authoritative sources (documentation, technical blogs, educational papers)"""
Node Perform for Part Builder – Generate Queries (Question Generator)
This makes use of the part matter and the instruction immediate above to generate some questions for researching on the internet to get helpful data on the part matter.
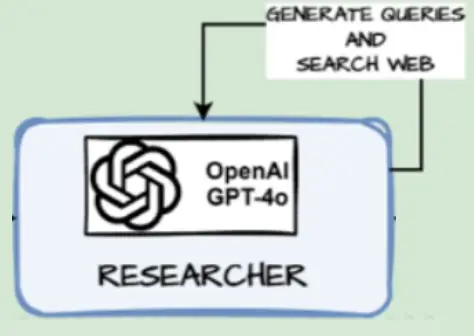
def generate_queries(state: SectionState):
""" Generate search queries for a particular report part """
# Get state
part = state["section"]
print('--- Producing Search Queries for Part: '+ part.identify +' ---')
# Get configuration
number_of_queries = 5
# Generate queries
structured_llm = llm.with_structured_output(Queries)
# Format system directions
system_instructions = REPORT_SECTION_QUERY_GENERATOR_PROMPT.format(section_topic=part.description, number_of_queries=number_of_queries)
# Generate queries
user_instruction = "Generate search queries on the supplied matter."
search_queries = structured_llm.invoke([SystemMessage(content=system_instructions),
HumanMessage(content=user_instruction)])
print('--- Producing Search Queries for Part: '+ part.identify +' Accomplished ---')
return {"search_queries": search_queries.queries}Node Perform for Part Builder – Search Net
Takes the queries generated by generate_queries(…)for a particular part, searches the net and codecs the search outcomes utilizing the utility capabilities we outlined earlier.
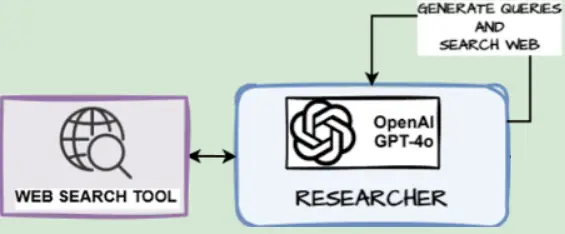
async def search_web(state: SectionState):
""" Search the net for every question, then return a listing of uncooked sources and a formatted string of sources."""
# Get state
search_queries = state["search_queries"]
print('--- Looking out Net for Queries ---')
# Net search
query_list = [query.search_query for query in search_queries]
search_docs = await run_search_queries(search_queries, num_results=6, include_raw_content=True)
# Deduplicate and format sources
search_context = format_search_query_results(search_docs, max_tokens=4000, include_raw_content=True)
print('--- Looking out Net for Queries Accomplished ---')
return {"source_str": search_context}Instruction Prompts for Part Builder – Part Author
There may be one principal instruction immediate:
1. SECTION_WRITER_PROMPT
Constrains the LLM to generate and write the content material for a particular part utilizing sure tips on type, construction, size, method and the paperwork obtained from the net earlier utilizing the search_web(…) operate are additionally despatched.
SECTION_WRITER_PROMPT = """You're an skilled technical author crafting one particular part of a technical report.
Title for the part:
{section_title}
Subject for this part:
{section_topic}
Tips for writing:
1. Technical Accuracy:
- Embrace particular model numbers
- Reference concrete metrics/benchmarks
- Cite official documentation
- Use technical terminology exactly
2. Size and Fashion:
- Strict 150-200 phrase restrict
- No advertising and marketing language
- Technical focus
- Write in easy, clear language don't use advanced phrases unnecessarily
- Begin together with your most essential perception in **daring**
- Use quick paragraphs (2-3 sentences max)
3. Construction:
- Use ## for part title (Markdown format)
- Solely use ONE structural component IF it helps make clear your level:
* Both a targeted desk evaluating 2-3 key objects (utilizing Markdown desk syntax)
* Or a brief record (3-5 objects) utilizing correct Markdown record syntax:
- Use `*` or `-` for unordered lists
- Use `1.` for ordered lists
- Guarantee correct indentation and spacing
- Finish with ### Sources that references the beneath supply materials formatted as:
* Checklist every supply with title, date, and URL
* Format: `- Title : URL`
3. Writing Method:
- Embrace no less than one particular instance or case research if accessible
- Use concrete particulars over common statements
- Make each phrase depend
- No preamble previous to creating the part content material
- Focus in your single most essential level
4. Use this supply materials obtained from internet searches to assist write the part:
{context}
5. High quality Checks:
- Format ought to be Markdown
- Precisely 150-200 phrases (excluding title and sources)
- Cautious use of solely ONE structural component (desk or bullet record) and provided that it helps make clear your level
- One particular instance / case research if accessible
- Begins with daring perception
- No preamble previous to creating the part content material
- Sources cited at finish
- If there are particular characters within the textual content, such because the greenback image,
guarantee they're escaped correctly for proper rendering e.g $25.5 ought to turn out to be $25.5
"""Node Perform for Part Builder – Write Part (Part Author)
Makes use of the SECTION_WRITER_PROMPT from above and feeds it with the part identify, description and internet search paperwork and passes it to an LLM to write down the content material for that part
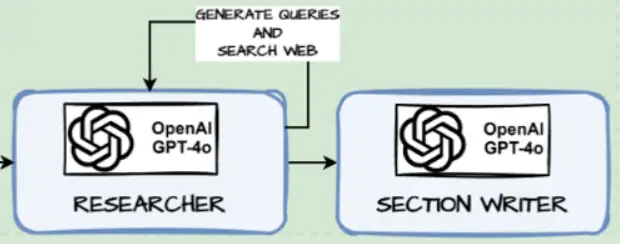
def write_section(state: SectionState):
""" Write a piece of the report """
# Get state
part = state["section"]
source_str = state["source_str"]
print('--- Writing Part : '+ part.identify +' ---')
# Format system directions
system_instructions = SECTION_WRITER_PROMPT.format(section_title=part.identify, section_topic=part.description, context=source_str)
# Generate part
user_instruction = "Generate a report part primarily based on the supplied sources."
section_content = llm.invoke([SystemMessage(content=system_instructions),
HumanMessage(content=user_instruction)])
# Write content material to the part object
part.content material = section_content.content material
print('--- Writing Part : '+ part.identify +' Accomplished ---')
# Write the up to date part to accomplished sections
return {"completed_sections": [section]}Create the Part Builder Sub-Agent
This agent (or to be extra particular, sub-agent) will probably be known as a number of instances in parallel, as soon as for every part to go looking the net, get content material after which write up that particular part. We leverage LangGraph’s Ship assemble for doing this.
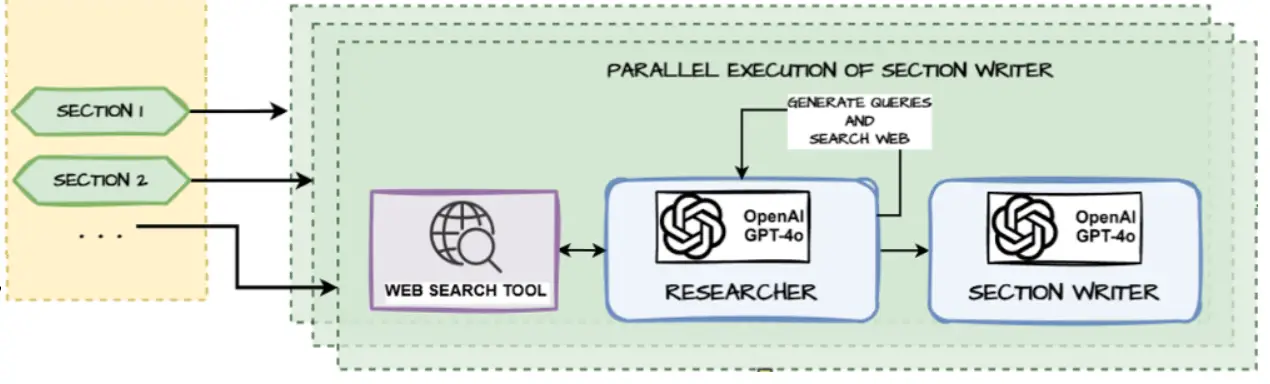
from langgraph.graph import StateGraph, START, END
# Add nodes and edges
section_builder = StateGraph(SectionState, output=SectionOutputState)
section_builder.add_node("generate_queries", generate_queries)
section_builder.add_node("search_web", search_web)
section_builder.add_node("write_section", write_section)
section_builder.add_edge(START, "generate_queries")
section_builder.add_edge("generate_queries", "search_web")
section_builder.add_edge("search_web", "write_section")
section_builder.add_edge("write_section", END)
section_builder_subagent = section_builder.compile()
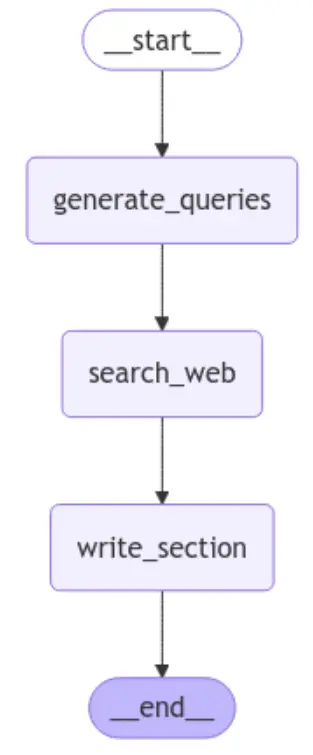
# Show the graph
from IPython.show import show, Picture
Picture(section_builder_subagent.get_graph().draw_mermaid_png())
Output
Create Dynamic Parallelization Node Perform – Parallelize Part Writing
Ship(…) is used to parallelize and name the section_builder_subagent as soon as for every part to write down up the content material (in parallel)
from langgraph.constants import Ship
def parallelize_section_writing(state: ReportState):
""" That is the "map" step after we kick off internet analysis for some sections of the report in parallel after which write the part"""
# Kick off part writing in parallel by way of Ship() API for any sections that require analysis
return [
Send("section_builder_with_web_search", # name of the subagent node
{"section": s})
for s in state["sections"]
if s.analysis
]Create Format Sections Node Perform
That is principally the part the place all of the sections are formatted and mixed collectively into one massive doc.
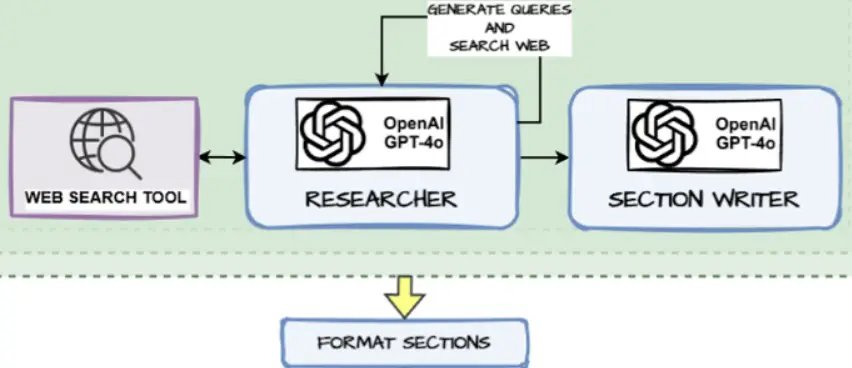
def format_sections(sections: record[Section]) -> str:
""" Format a listing of report sections right into a single textual content string """
formatted_str = ""
for idx, part in enumerate(sections, 1):
formatted_str += f"""
{'='*60}
Part {idx}: {part.identify}
{'='*60}
Description:
{part.description}
Requires Analysis:
{part.analysis}
Content material:
{part.content material if part.content material else '[Not yet written]'}
"""
return formatted_str
def format_completed_sections(state: ReportState):
""" Collect accomplished sections from analysis and format them as context for writing the ultimate sections """
print('--- Formatting Accomplished Sections ---')
# Checklist of accomplished sections
completed_sections = state["completed_sections"]
# Format accomplished part to str to make use of as context for ultimate sections
completed_report_sections = format_sections(completed_sections)
print('--- Formatting Accomplished Sections is Completed ---')
return {"report_sections_from_research": completed_report_sections}Instruction Prompts for the Last Part
There may be one principal instruction immediate:
1. FINAL_SECTION_WRITER_PROMPT
Constrains the LLM to generate and write the content material for both the introduction OR conclusion utilizing sure tips on type, construction, size, method and the content material of the already written sections are additionally despatched.
FINAL_SECTION_WRITER_PROMPT = """You're an skilled technical author crafting a piece that synthesizes data from the remainder of the report.
Title for the part:
{section_title}
Subject for this part:
{section_topic}
Accessible report content material of already accomplished sections:
{context}
1. Part-Particular Method:
For Introduction:
- Use # for report title (Markdown format)
- 50-100 phrase restrict
- Write in easy and clear language
- Give attention to the core motivation for the report in 1-2 paragraphs
- Use a transparent narrative arc to introduce the report
- Embrace NO structural components (no lists or tables)
- No sources part wanted
For Conclusion/Abstract:
- Use ## for part title (Markdown format)
- 100-150 phrase restrict
- For comparative studies:
* Should embrace a targeted comparability desk utilizing Markdown desk syntax
* Desk ought to distill insights from the report
* Maintain desk entries clear and concise
- For non-comparative studies:
* Solely use ONE structural component IF it helps distill the factors made within the report:
* Both a targeted desk evaluating objects current within the report (utilizing Markdown desk syntax)
* Or a brief record utilizing correct Markdown record syntax:
- Use `*` or `-` for unordered lists
- Use `1.` for ordered lists
- Guarantee correct indentation and spacing
- Finish with particular subsequent steps or implications
- No sources part wanted
3. Writing Method:
- Use concrete particulars over common statements
- Make each phrase depend
- Focus in your single most essential level
4. High quality Checks:
- For introduction: 50-100 phrase restrict, # for report title, no structural components, no sources part
- For conclusion: 100-150 phrase restrict, ## for part title, solely ONE structural component at most, no sources part
- Markdown format
- Don't embrace phrase depend or any preamble in your response
- If there are particular characters within the textual content, such because the greenback image,
guarantee they're escaped correctly for proper rendering e.g $25.5 ought to turn out to be $25.5"""Create Write Last Sections Node Perform
This operate makes use of the instruction immediate FINAL_SECTION_WRITER_PROMPT talked about above to write down up the introduction and conclusion. This operate will probably be executed in parallel utilizing Ship(…) beneath
def write_final_sections(state: SectionState):
""" Write the ultimate sections of the report, which don't require internet search and use the finished sections as context"""
# Get state
part = state["section"]
completed_report_sections = state["report_sections_from_research"]
print('--- Writing Last Part: '+ part.identify + ' ---')
# Format system directions
system_instructions = FINAL_SECTION_WRITER_PROMPT.format(section_title=part.identify,
section_topic=part.description,
context=completed_report_sections)
# Generate part
user_instruction = "Craft a report part primarily based on the supplied sources."
section_content = llm.invoke([SystemMessage(content=system_instructions),
HumanMessage(content=user_instruction)])
# Write content material to part
part.content material = section_content.content material
print('--- Writing Last Part: '+ part.identify + ' Accomplished ---')
# Write the up to date part to accomplished sections
return {"completed_sections": [section]}Create Dynamic Parallelization Node Perform – Parallelize Last Part Writing
Ship(…) is used to parallelize and name the write_final_sections as soon as for every of the introduction and conclusion to write down up the content material (in parallel)
from langgraph.constants import Ship
def parallelize_final_section_writing(state: ReportState):
""" Write any ultimate sections utilizing the Ship API to parallelize the method """
# Kick off part writing in parallel by way of Ship() API for any sections that don't require analysis
return [
Send("write_final_sections",
{"section": s, "report_sections_from_research": state["report_sections_from_research"]})
for s in state["sections"]
if not s.analysis
]Compile Last Report Node Perform
This operate combines all of the sections of the report collectively and compiles it into the ultimate report doc
def compile_final_report(state: ReportState):
""" Compile the ultimate report """
# Get sections
sections = state["sections"]
completed_sections = {s.identify: s.content material for s in state["completed_sections"]}
print('--- Compiling Last Report ---')
# Replace sections with accomplished content material whereas sustaining unique order
for part in sections:
part.content material = completed_sections[section.name]
# Compile ultimate report
all_sections = "nn".be a part of([s.content for s in sections])
# Escape unescaped $ symbols to show correctly in Markdown
formatted_sections = all_sections.substitute("$", "TEMP_PLACEHOLDER") # Quickly mark already escaped $
formatted_sections = formatted_sections.substitute("$", "$") # Escape all $
formatted_sections = formatted_sections.substitute("TEMP_PLACEHOLDER", "$") # Restore initially escaped $
# Now escaped_sections incorporates the correctly escaped Markdown textual content
print('--- Compiling Last Report Completed ---')
return {"final_report": formatted_sections}Construct our Deep Analysis & Report Author Agent
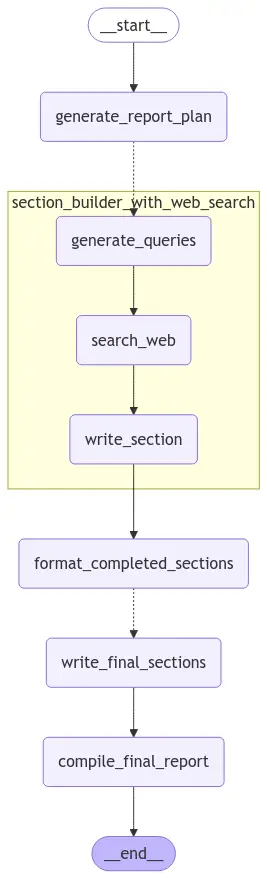
We now deliver all of the outlined parts and sub-agents collectively and construct our principal planning agent.
builder = StateGraph(ReportState, enter=ReportStateInput, output=ReportStateOutput)
builder.add_node("generate_report_plan", generate_report_plan)
builder.add_node("section_builder_with_web_search", section_builder_subagent)
builder.add_node("format_completed_sections", format_completed_sections)
builder.add_node("write_final_sections", write_final_sections)
builder.add_node("compile_final_report", compile_final_report)
builder.add_edge(START, "generate_report_plan")
builder.add_conditional_edges("generate_report_plan",
parallelize_section_writing,
["section_builder_with_web_search"])
builder.add_edge("section_builder_with_web_search", "format_completed_sections")
builder.add_conditional_edges("format_completed_sections",
parallelize_final_section_writing,
["write_final_sections"])
builder.add_edge("write_final_sections", "compile_final_report")
builder.add_edge("compile_final_report", END)
reporter_agent = builder.compile()
# view agent construction
show(Picture(reporter_agent.get_graph(xray=True).draw_mermaid_png()))Output
We are actually able to run and check out our agentic system!
Run and Check our Deep Analysis & Report Author Agent
Let’s lastly put our deep analysis report writing agent to the check! We’ll create a easy operate to stream the progress dwell after which present the ultimate report. I might advocate to show off all of the intermediate print messages after getting a functioning agent!
from IPython.show import show
from wealthy.console import Console
from wealthy.markdown import Markdown as RichMarkdown
async def call_planner_agent(agent, immediate, config={"recursion_limit": 50}, verbose=False):
occasions = agent.astream(
{'matter' : immediate},
config,
stream_mode="values",
)
async for occasion in occasions:
for okay, v in occasion.objects():
if verbose:
if okay != "__end__":
show(RichMarkdown(repr(okay) + ' -> ' + repr(v)))
if okay == 'final_report':
print('='*50)
print('Last Report:')
md = RichMarkdown(v)
show(md)Check Run
matter = "Detailed report on how is NVIDIA profitable the sport in opposition to its opponents"
await call_planner_agent(agent=reporter_agent,
immediate=matter)Output
--- Producing Report Plan ---
--- Producing Report Plan Accomplished ---
--- Producing Search Queries for Part: NVIDIA's Market Dominance in GPUs
------ Producing Search Queries for Part: Strategic Acquisitions and
Partnerships ---
--- Producing Search Queries for Part: Technological Improvements and AI
Management ------ Producing Search Queries for Part: Monetary Efficiency and Progress
Technique ---
--- Producing Search Queries for Part: NVIDIA's Market Dominance in GPUs
Accomplished ---
--- Looking out Net for Queries ---
--- Producing Search Queries for Part: Monetary Efficiency and Progress
Technique Accomplished ---
--- Looking out Net for Queries ---
--- Producing Search Queries for Part: Technological Improvements and AI
Management Accomplished ---
--- Looking out Net for Queries ---
--- Producing Search Queries for Part: Strategic Acquisitions and
Partnerships Accomplished ---
--- Looking out Net for Queries ---
--- Looking out Net for Queries Accomplished ---
--- Writing Part : Strategic Acquisitions and Partnerships ---
--- Looking out Net for Queries Accomplished ---
--- Writing Part : Monetary Efficiency and Progress Technique ---
--- Looking out Net for Queries Accomplished ---
--- Writing Part : NVIDIA's Market Dominance in GPUs ---
--- Looking out Net for Queries Accomplished ---
--- Writing Part : Technological Improvements and AI Management ---
--- Writing Part : Strategic Acquisitions and Partnerships Accomplished ---
--- Writing Part : Monetary Efficiency and Progress Technique Accomplished ---
--- Writing Part : NVIDIA's Market Dominance in GPUs Accomplished ---
--- Writing Part : Technological Improvements and AI Management Accomplished ---
--- Formatting Accomplished Sections ---
--- Formatting Accomplished Sections is Completed ---
--- Writing Last Part: Introduction ------ Writing Last Part:
Conclusion ------ Writing Last Part: Introduction Accomplished ---
--- Writing Last Part: Conclusion Accomplished ---
--- Compiling Last Report ---
--- Compiling Last Report Completed ---
==================================================
Last Report:
It offers us a reasonably complete, well-researched and well-structured report for our given matter as seen above!
Conclusion
In case you are studying this, I commend your efforts in staying proper until the tip on this huge information! Right here we noticed that it’s not too tough to construct one thing just like a full-fledged business (and never too low cost at that!) product launched by OpenAI, an organization which positively is aware of the right way to push out high quality merchandise on Generative AI and now Agentic AI.
We noticed an in depth structure and workflow on the right way to construct our personal Deep Analysis and Report Era Agentic AI System and general to run this method, it prices you lower than a greenback as promised! For those who use open-source parts for the whole lot, it’s completely free! Plus that is completely customizable the place you possibly can management the best way the searches occur, the construction, size and magnificence of the report. Do be aware that if you’re utilizing Tavily, you possibly can simply find yourself making loads of searches when operating this agent for deep analysis so be conscious and hold monitor of your utilization. This simply offers you a basis to construct on and be happy to make use of this code and system and customise it and make it even higher!
Head of Group, Principal AI Scientist at Analytics Vidhya, Revealed Creator and AI Advisor with over 10 years of worldwide expertise working with Fortune 100 firms, startups and educational organizations